如何将自己开发的模型转换为TensorFlow Lite可用模型
由于我现在还处在机器学习入门阶段,对很多知识也是一知半解,没有那个实力去写好的原创文章,所以还是翻译一篇文章分享给大家。如果有问题请参看原文或和我联系。原文地址:https://heartbeat.fritz.ai/intro-to-machine-learning-on-android-how-to-convert-a-custom-model-to-tensorflow-lite-e07d2d9d50e3

对于开发者来说,在移动设备上运行预先训练好的模型的能力意味着向边界计算(edge computing)迈进了一大步。[译注:所谓的边界计算,从字面意思理解,就是与现实世界的边界。数据中心是网络的中心,PC、手机、监控照相机处在边界。]数据能够直接在用户手机上处理,私人数据仍然掌握在他们手中。没有蜂窝网络的延迟,应用程序可以运行得更顺畅,并且可大幅减少公司的云服务账单。快速响应式应用现在可以运行复杂的机器学习模型,这种技术转变将赋予产品工程师跳出条条框框思考的力量,迎来应用程序开发的新潮流。
继Apple发布CoreML之后,Google发布了TensorFlow Lite的开发者预览版,这是TensorFlow Mobile的后续发展版本。通过在支持它的设备上利用硬件加速,TensorFlow Lite可以提供更好的性能。它也具有较少的依赖,从而比其前身有更小的尺寸。尽管目前还处于早期阶段,但显然谷歌将加速发展TF Lite,持续增加支持并逐渐将注意力从TFMobile转移。考虑到这一点,我们直接选择TFLite, 尝试创建一个简单的应用程序,做一个技术介绍。
初识
显然从谷歌的TensorFlow Lite文档入手最好,这些文档主要在github上(https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/lite)。他们还发布了一些简单的教程来帮助其他人上手:
- Android Demo:使用TFLite版本MobileNet模型的Android应用程序。
- TensorFlow for Poets 2:谷歌的TFLite教程,重新训练识别花卉的模型。
这些示例和教程更侧重于使用预先训练的模型或重新训练现有的模型。但是用户自己的模型呢? 如果我有一个训练的模型,想将其转换为.tflite文件,该怎么做?有一些简略提示我该怎么做,我按图索骥,无奈有一些进入了死胡同。经过一天费尽心思的搜索,一小撮脚本和几杯咖啡,我终于让它能够工作了 - 一个简单的,转换过的MNIST.tflite模型。(我发誓,这不会是另一个MNIST训练教程,Google和许多其他开发人员已经用尽了这个话题)。
在这篇文章中,我们将学习一些通用的技巧,一步一步为移动设备准备一个TFLite模型。
从一个简单的模型开始
首先,我想选择一个未经过预先训练或转换成.tflite文件的TensorFlow模型,理所当然我选择使用MNIST数据训练的简单的神经网络(目前支持3种TFLite模型:MobileNet、Inception v3和On Device Smart Reply)。
幸运的是,Google在其模型库(model zoo)中开放了大量研究模型和可用模型,这其中包括MNIST训练脚本。我们将在本节中引用该代码,大致浏览一下,熟悉它。
我们应该对此训练脚本进行一些修改,以便稍后进行转换。
- 第一个问题是“什么是输入和输出层?”
class Model(tf.keras.Model):
...
def __call__(self, inputs, training):
# Input layer
y = tf.reshape(inputs, self._input_shape)
y = self.conv1(y)
y = self.max_pool2d(y)
y = self.conv2(y)
y = self.max_pool2d(y)
y = tf.layers.flatten(y)
y = self.fc1(y)
y = self.dropout(y, training=training)
# Returns a logit layer
return self.fc2(y)从这段代码,我们清楚地看到输入层是tf.reshape,所以给它一个名字。
y = tf.reshape(inputs, self._input_shape, name='input_tensor’)一个好的做法是为输入和输出图层命名。这将为您在后面节省一些时间和精力,因此您不必在tensorboard上四处搜索以填写转换工具的某些参数。(另外一个好处是,如果您共享模型而没有共享训练脚本,开发人员可以研究模型并快速识别图形的输入输出)。
- 我开始猜想Logit层是输出层,但那不是我们想要获得推断结果的层。相反,我们希望softmax层用于推断模型的输出。(请看如下代码的第7行)
def model_fn(features, labels, mode, params):
...
logits = model(image, training=False)
predictions = {
'classes': tf.argmax(logits, axis=1),
'probabilities': tf.nn.softmax(logits, name='softmax_tensor'),
}
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(
mode=tf.estimator.ModeKeys.PREDICT,
predictions=predictions,
export_outputs={
'classify': tf.estimator.export.PredictOutput(predictions)
})我们还需要在TensorFlow图中暴露softmax图层,因为它是用于推断的输出图层。现在它嵌入在推断方法中。作一个简单的修正,将其移出,这样当我们训练此模型时,图形将包含此图层。 显然有更好的方法来修改它,但这是编辑现有MNIST脚本的简单方法。
总而言之,我们研究了训练脚本,并专门命名了模型推理所需的输入和输出层。请记住,我们正在使用的MNIST脚本同时进行训练和推理。了解训练和推理层之间的区别很重要。 由于我们希望准备好的模型仅用于移动平台上的推断(在MNIST数据的情况下预测手写数字),因此我们只需要预测所需的图层。请记住,我们正在使用的MNIST脚本既有训练又有预测。稍后,我们将在Tensorboard中看到分离两者。
这里有完整的mnist.py文件供您参考。
- 要训练模型,在模型项目根目录下请运行以下命令。在我的17年Macbook Pro上,这需要约1-2小时。
python official/mnist/mnist.py --export_dir /tmp/mnist_saved_model --model-dir /tmp/mnist_graph_def_with_ckpts这些导出目录保存检查点和定义图形的protobuf文件。我们来分析一下从训练文件中保存的不同的TF格式。
在TensorFlow格式之间转换:
github文档中,对GraphDef(.pb)、FrozenGraphDef(带有冻结变量的.pb)、SavedModel(.pb - 用于推断服务器端的通用格式)和Checkpoint文件(在训练过程中的序列化变量)有明确的解释。 这是我创建的一张图表,展示了如何从一个转换到另一个,一步一步解释这中间涉及到的东西。

从MNIST训练脚本中,我们得到文本可读形式(.pbtxt)的Graph Def、检查点和保存的图形。 重要的是要注意GraphDef、Saved Model、FrozenGraph和Optimized Graphs都以protobuf格式保存(.pb)
- 训练模型 - 这将生成3个代表网络结构的文件。我们关心的是GraphDef和检查点文件。在训练脚本的命令中,保存这些文件的文件夹位于/tmp/mnist_saved_model下。你应该看到这样的文件:
>> ls /tmp/mnist_graph_def_with_ckpts
checkpoint
model.ckpt-48000
model.ckpt-35626
model.ckpt-39410
model.ckpt-43218
model.ckpt-47043
model.ckpt-48000
graph.pbtxt.pbtxt是图形def的文本格式。 您应该能够像任何.pb文件一样使用它。
我强烈建议使用Tensorboard来检查图表。请参考附录了解如何导入和使用它。
审查.pbtxt图,我们看到:

训练后在Tensorboard中可视化graph.pbtxt - 在这里,我们标记了输入和输出图层以及仅用于模型训练中的不必要图层。
使用Tensorboard,我们可以看到训练脚本中生成的每个图层。由于我们命名了输入和输出图层,因此我们可以轻松识别它们,然后开始了解哪些图层对于推断是必需的,哪些图层可以丢弃掉的。 绿线框起来的所有内容都用于在训练过程中调整权重。同样,input_tensor之前的所有内容也是不必要的。在移动设备上运行之前,我们需要裁剪此图。 TFLite中大多数训练层也不受支持(请参阅附录)。
- 冻结图 - 这将冻结GraphDef中的检查点变量
freeze_graph
--input_graph=/tmp/mnist_graph_def_with_ckpts/graph.pbtxt
--input_checkpoint=/tmp/mnist_graph_def_with_ckpts/model.ckpt-48000
--input_binary=false
--output_graph=/tmp/mnist_graph_def_with_ckpts/frozen_mnist.pb
--output_node_names=softmax_tensor- 如果您使用pip安装了TensorFlow,将会得到freeze_graph命令。 (安装说明)
- 打开检查点文件并确定最新的文件。 在我们的例子中,它是model.ckpt-48000
- Input binary选项是false,因为我们传递的是.pbtxt文件而不是.pb(在这种情况下,它应该是true)。
- 最难的部分是识别output_node_name,但由于我们在训练脚本中给了它一个名字,这样就很容易了。如果您没有为创建的模型提供训练脚本,则需要使用Tensorboard并为其找到自动生成的名称(我花了大量时间试图理解这一点,因此简而言之,训练脚本得心应手是一项巨大的奖励)。
结果是:/tmp/mnist_graph_def_with_ckpts/frozen_mnist.pb下的冻结图。此时,再次检查Tensorboard中的图形是个好主意。
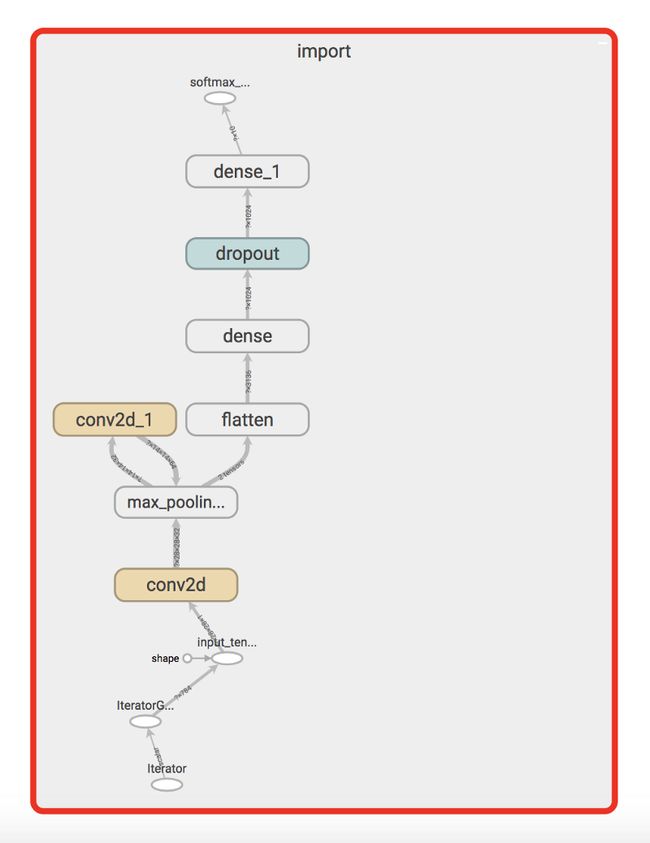
请注意,freeze_graph实际上删除了训练中使用的大部分图层。但是,我们仍然有一些与TFLite不兼容的东西。具体来说,请注意“dropout”和“iterator”层。这些图层用于训练,仍然需要裁剪。为了这一目的,我们使用优化器。
- 优化冻结图
optimize_for_inference工具(安装指南)接受输入和输出名称,并执行另一次传递以去除不必要的图层。
optimize_for_inference \
--input=/tmp/mnist_graph_def_with_ckpts/frozen_mnist.pb \
--output=/tmp/mnist_graph_def_with_ckpts/opt_mnist_graph.pb \
--frozen_graph=True \
--input_names=input_tensor \
--output_names=softmax_tensor我们需要指定输入和输出名称(input_tensor&softmax_tensor)。这个任务删除了图中的所有预处理。
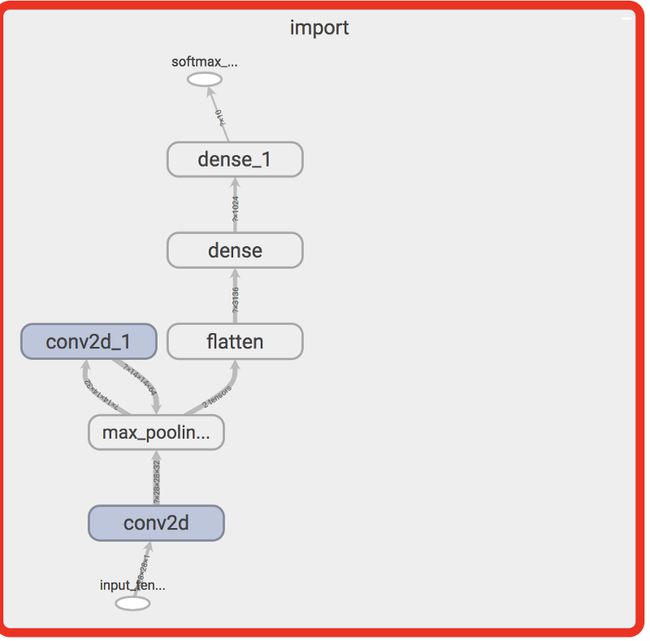
在Tensorboard中评估opt_mnist_graph.pb。 注意dropout和iterator现在不见了。
结果应该是准备好转换为TFLite的图表。如果仍有不受支持的图层,请检查graph_transform工具。在本例中,所有操作都受支持。
- 转换为TFLite
最后一步是运行toco工具,及TensorFlow Lite优化转换器。唯一可能令人困惑的部分是输入形状。使用Tensorboard或summarize_graph工具,您可以获得形状。

在Tensorboard中,如果我们评估input_tensor,你会看到形状?x28x28x1。这里? 代表batch_size。在我们的例子中,我们将构建一个Android应用程序,该应用程序一次只能检测一个图像,因此在下面的toco工具中,我们将形状设置为1x28x28x1。
toco \
--input_file=/tmp/mnist_graph_def_with_ckpts/opt_mnist_graph.pb \
--input_format=TENSORFLOW_GRAPHDEF \
--output_format=TFLITE \
--inference_type=FLOAT \
--input_type=FLOAT \
--input_arrays=input_tensor \
--output_arrays=softmax_tensor \
--input_shapes=1,28,28,1 \
--output_file=/tmp/mnist_graph_def_with_ckpts/mnist.tflite这里您得到一个可以直接添加到Android项目的TFLite文件。如果您已经完成了前面的步骤并确保所有操作都与TensorFlow Lite兼容,那么这部分应该非常简单。如果您有任何问题,请随时在下面留言。
得到的经验:
- Tensorboard是你的朋友。用它在每一步评估图形,识别不支持的图层,并找出输入和输出形状。在更复杂的模型中,您可能会遇到TFLite不支持的操作,因此了解它们是哪些操作并查看是否可以使用graph_transform工具进行操作,也是很好的。
- 为输入和输出层命名。不要让TensorFlow为您做。由于我们在训练脚本中做了一些小改动,我们可以轻松填写每个转换工具中的不同选项。您也可以使用Tensorboard查找生成的名称,但是对输入和输出进行命名可以让其他可能没有原始训练脚本的人员更加清楚。
- 了解在训练和推理中使用了哪些图层 - 我们从一个脚本训练了MNIST模型,因此得到的图形包含了大量额外的图层。虽然诸如optimize_for_inference和freeze_graph之类的工具裁剪了训练节点,但我也遇到过不能像我期望的那样精确执行的情况(例如,有一次,我必须参考一个很棒的博客文章手动从冻结图中删除dropout层)。
- TensorFlow格式 - 理解每种工具和操作如何生成不同的文件格式。如果能自动获取SavedGraph并将其转换(缩减中间的一堆步骤)会很棒,但我们还没有做到。
- 转换服务器端模型以实现移动框架兼容性并非易事 - 在移动端机器学习的生命周期中,大量工程师要么停滞不前,要么将大部分时间花在将现有模型转换到移动设备上。有TOCO和coremltools(用于iOS上的Core ML)之类的工具是一个很好的开始,但通常情况下,您必须修改底层模型架构(并可能需要重新训练它)才能使转换器正常工作。
- TensorFlow Lite仍处在开发人员预览版中 - 文档中特别提到,甚至谷歌也承认,如果您需要生产级支持,最好留在TFMobile中,因为它们可以为操作系统提供更多支持。尽管令人兴奋,但并没有太多的例子或文档。如果您希望获得先机,可以深入实际的TensorFlow代码库。代码始终是真理的最佳来源:)
下一步
从培训脚本开始,我们能够检查和修改TensorFlow图表,以便用于移动设备。通过遵循这些步骤,我们修剪了不必要的操作,并能够成功地将protobuf文件(.pb)转换为TFLite(.tflite)。
在接下来的文章中,我们将切换到移动开发并看看如何使用我们新近转换的mnist.tflite文件在Android应用程序中检测手写数字。
附录
使用Tensorboard
- 我创建了一个修改版本的import_pb_to_tensorboard.py,以支持导入图形定义(.pb)、图形定义文本(.pbtxt)和保存模型(.pb)文件类型。 希望在未来几天内提交PR。
- 要设置tensorboard,请确保其已经安装并依照如下步骤:
# From anywhere though I suggest you make it outside of the git repos
mkdir training_summaries
# Runs tensorboard in the background at http://localhost:6006
tensorboard --logdir training_summaries &
# Using my modified import_pb_to_tensorboard.py in the tensorflow repo (feel free to edit to your liking)
import_pb_to_tensorboard.py --model_dir /tmp/mnist_graph_def_with_ckpts/graph.pbtxt --log_dir training_summaries/mnist --graph_type=PbTxt
training_summarizes目录用于存储导入图形的结果
支持的TFLite操作
Google正在继续增加对更多操作的支持,这里列出了当前可用的列表。
