jupyter安装及配置scala、spark、pyspark内核
安装 jupyter和python
本文使用Anaconda安装jupyter。
Anaconda可以看做Python的一个集成安装,安装它后就默认安装了python、IPython、集成开发环境Spyder和众多的包和模块
也可参照https://docs.anaconda.com/anaconda/install/linux进行安装
下载 Anaconda
Anaconda的官网下载地址https://www.anaconda.com/download/,可以根据自己的需要自行下载,本文使用的操作系统为ubuntu,因此下载的是Anaconda installer for Linux.
wget https://repo.continuum.io/archive/Anaconda3-5.0.1-Linux-x86_64.sh使用MD5或SHA-256验证数据完整性。
md5sum Anaconda3-5.0.1-Linux-x86_64.sh #后跟下载文件的实际路径和文件名或者
sha256sum Anaconda3-5.0.1-Linux-x86_64.sh安装Anaconda
bash Anaconda3-5.0.1-Linux-x86_64.sh 
接受许可协议
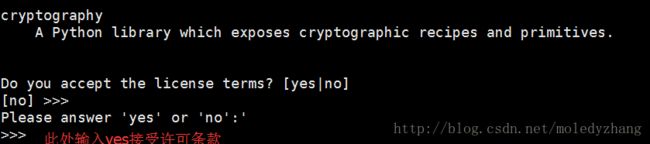
选择安装路径,直接回车表示选择默认路径

在/root/.bashrc中将Anaconda 1安装位置预先安装到PATH中
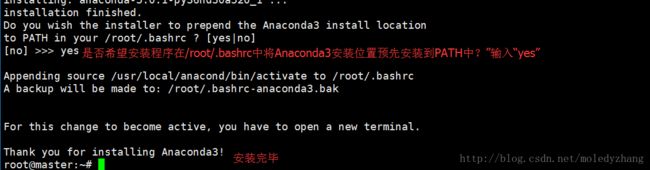
使安装生效
source ~/.bashrc到此Anaconda安装结束。
启动jupyter notebook
Anaconda自带安装了jupyter,因此安装完Anaconda后,在命令行输入如下命令即可启动jupyter notebook
jupyter notebook

默认制定的WEBUI地址为localhost,端口为8888,因此是不允许远程访问的。
也可在启动时手动指定
jupyter notebook --allow-root --no-browser --port 6789 --ip=*
配置jupyter notebook的远程访问
jupyter notebook安装好后默认只能在本地服务器本地访问(也就是我的ubuntu虚拟机上),如果想从真机windows上访问,需做如下配置
1.登陆远程服务器
ssh 远程服务器ip地址或主机名2.生成配置文件
jupyter notebook --generate-config![]()
该命令执行完后,会输出配置文件的默认保存路径
3.生成密码
打开ipython,创建密文密码,将生成的密码复制下来
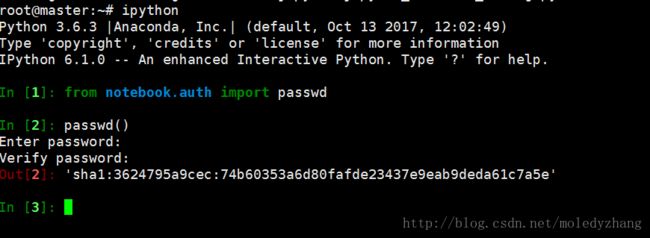
4.修改默认配置文件
vim ~/.jupyter/jupyter_notebook_config.py修改如下选项
c.NotebookApp.ip = '*'
c.NotebookApp.password = u'sha1:3624795a9cec:74b60353a6d80fafde23437e9eab9deda61c7a5e' #将刚才复制的密文复制到此处
c.NotebookApp.open_browser = False #指定不打开浏览器
c.NotebookApp.port = 6789 #指定端口5.启动jupyter notebook
jupyter notebook --allow-root #root用户需添加--allow-root选项,其他不用6.本地浏览器访问
http://ip或主机名:6789
输入之前创建的密码即可进入
安装scala kernel
jupyter提供了Python之外的许多编程语言的支持, 如R,Go, Scala等等,不过都需要用户手动安装,这里讲scala kernel和spark kernel的安装
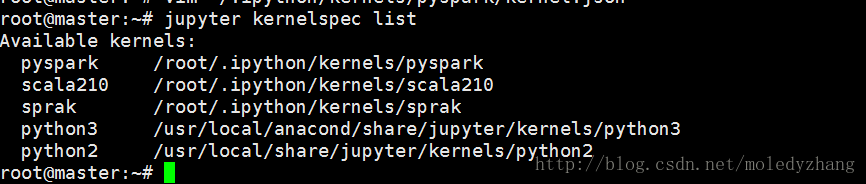
查看已有内核
jupyter kernelspec list
可以看到,已经安装了python2和python3
下载jupyter-scala
https://oss.sonatype.org/content/repositories/snapshots/com/github/alexarchambault/jupyter/jupyter-scala-cli_2.10.5/0.2.0-SNAPSHOT/jupyter-scala_2.10.5-0.2.0-SNAPSHOT.tar.xz
安装jupyter-scala
tar -xvf jupyter-scala_2.10.5-0.2.0-SNAPSHOT.tar.xz -C /usr/local/
bash /usr/local/jupyter-scala_2.10.5-0.2.0-SNAPSHOT/bin/jupyter-scala出现如下界面,表示已经成功安装

此时,再次查看支持的内核,发现多了一个

安装spark kernel
前提准备
安装spark,可以参考博主的 spark分布式集群环境搭建(hadoop之上)
安装sbt,之后编译spark需要sbt,具体的安装方法可参考博文http://blog.csdn.net/he582754810/article/details/54311233
安装spark kernel
cd /usr/local/anacond
git clone https://github.com/apache/incubator-toree.git#如果没有git命令,请先行安装
cd incubator-toree/修改Makefile文件中的APACHE_SPARK_VERSION选项的值,与SPARK_HOME统一版本
APACHE_SPARK_VERSION?=2.2.1使用”make build”命令编译spark,出现success表示成功,这个过程时间比较长,需要等几分钟
make buildmake dist #该命令用于将可执行文件及相关文件打包成一个tar.gz压缩的文件用来作为发布软件的软件包。
cd dist/toree/bin/
ls使用ls查到当前目录下有一个名为run.sh的文件,记住该文件的路径(/usr/local/anacond/incubator-toree/dist/toree/bin/run.sh
),后面会使用到
cd /root/.ipython/kernels/sprak/
vim kernel.json写入如下内容
{
"display_name": "Spark 2.2.1 (Scala 2.10.4)",
"lauguage_info": {"name": "scala"},
"argv": [
"/usr/local/anacond/incubator-toree/dist/toree/bin/run.sh",#替换为前面记住的run.sh的路径
"--profile",
"{connection_file}"
],
"codemirror_mode": "scala",
"env": {
"SPARK_OPTS": "--master=local[2] --driver-java-options=-Xms1024M --driver-java-options=-Xms4096M --driver-java-options=-Dlog4j.logLevel=info",
"MAX_INTERPRETER_THREADS": "16",
"CAPTURE_STANDARD_OUT": "true",
"CAPTURE_STANDARD_ERR": "true",
"SEND_EMPTY_OUTPUT": "false",
"SPARK_HOME": "/usr/local/spark",#替换成自己的SPARK_HOME路径
"PYTHONPATH": "/usr/local/spark/python:/usr/local/spark/python/lib/py4j-0.10.4-src.zip"#替换为自己的
}
}
再次查看内核
jupyter kernelspec list
到这里我们就已经成功安装上spark的内核了,接下来启动jupyter notebook
jupyter notebook --allow-root本地浏览器访问,我们就可以新建一个支持scala和spark的notebook了

安装pyspark kernel
mkdir ~/.ipython/kernels/pyspark
vim ~/.ipython/kernels/pyspark/kernel.json
写入如下内容:
{
"display_name": "pySpark",
"language": "python",
"argv": [
"/usr/local/anacond/bin/python3",
"-m",
"IPython.kernel",
"-f",
"{connection_file}"
],
"env": {
"SPARK_HOME": "/usr/local/spark",
"PYTHONPATH": "/usr/local/spark/python:/usr/local/spark/python/lib/py4j-0.10.4-src.zip",
"PYTHONSTARTUP": "/usr/local/spark/python/pyspark/shell.py ",
"PYSPARK_SUBMIT_ARGS": "pyspark-shell"
}
}注意将其中的路径替换成自己的,然后查看内核
到此,我们已经为jupyter配置了scala、spark、pyspark内核,可以根据具体的开发任务选择不同的内核
参考博文
http://blog.csdn.net/heng_2218/article/details/51006075
http://blog.csdn.net/gavin_john/article/details/53177630