Python3 解决中文乱码 requests库中文乱码问题【别的博客好多都是都是然并卵的教程】
直接教程
s=requests.session()
s.headers['Accept']='text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8'
s.headers['Accept-Encoding']='gzip, deflate, br'
s.headers['Host']='pan.baidu.com'
s.headers['Accept-Language']='zh-CN,zh;q=0.9,en;q=0.8,ja;q=0.7,ko;q=0.6'
s.headers['User-Agent']='zilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
response =s.get(urlsA[0])
response.encoding = response.apparent_encoding
data=response.text教程详解
当使用requests库的时候,会出现中文乱码的情况
参考代码分析Python requests库中文编码问题
Python HTTP库requests中文页面乱码解决方案!
分析
根据这两篇文章可知:
分析requests的源代码发现,text返回的是处理过的Unicode型的数据,而使用content返回的是bytes型的原始数据。也就是说,r.content相对于r.text来说节省了计算资源,content是把内容bytes返回. 而text是decode成Unicode. 如果headers没有charset字符集的化,text()会调用chardet来计算字符集,这又是消耗cpu的事情.
| 1 2 3 4 |
|
这里测试使用电影天堂的网页,因为网页不太标准
输出为
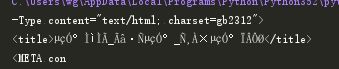
输出了乱码
response.encoding
![]()
从第二篇文章可以知道reqponse header只指定了type,但是没有指定编码(一般现在页面编码都直接在html页面中),查找原网页可以看到
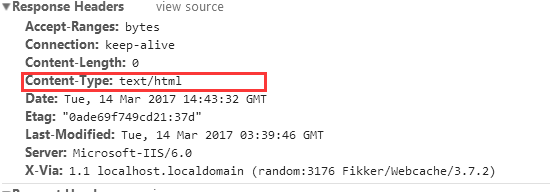
再找一个标准点的网页查看,比如博客园的网页博客园
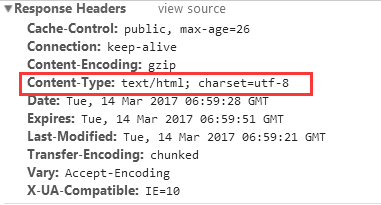
response herders的Content-Type指定了编码类型
《HTTP权威指南》里第16章国际化里提到,如果HTTP响应中Content-Type字段没有指定charset,则默认页面是'ISO-8859-1'编码。这处理英文页面当然没有问题,但是中文页面,就会有乱码了!
解决
如果在确定使用text,并已经得知该站的字符集编码时,可以使用 r.encoding = ‘xxx’ 模式, 当你指定编码后,requests在text时会根据你设定的字符集编码进行转换.
使用apparent_encoding可以获得真实编码
| 1 2 |
|
这是程序自己分析的,会比较慢
还可以从html的meta中抽取
| 1 2 |
|
解决方法
| 1 2 |
|
这时候的输出为
