Image Caption图像描述总结
方法分类
- 现有的解决图像描述任务的算法大致可以分为三类 :基于模板式的 、基于相似空间检索式的 、基于多模翻译式的 。
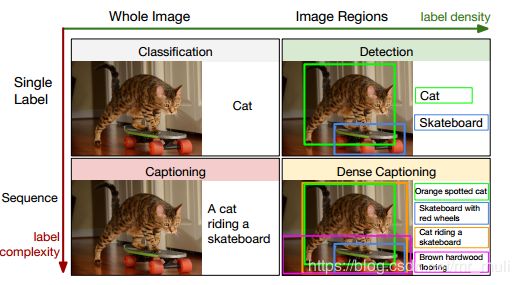
- 现有的生成图像描述的形式大致也可分为三类 :单句子式描述 ,密集型描述,多语言描述。
- 模板式:模板式基于句法树创建的数据驱动模型,基于视觉依存表示来提取对象之间的关系,利用名词,动词 ,场景和介词组成的四元组描述图像 ,基于语言解析的表达模型也有广泛应用 。 基 于模板的方法的优点是得到的语言描述更有可能在语法上正确,缺点是它们仍然高度依赖于模板 ,不适用于所有图像,且限制了输出的多样性
- 相似性检索的方式:对于图像查询方式,是指检索向量空间中最接近的图像描述 ,以生成自己的图像描述 。 通常这个方法确实可以实现人类的描述 , 因为所有的句子来自现有的人工生成的句子。 但该方法需要收集大量人工生成的句子,训练集也需要多样化, 并且这个方法一定程度上不能产生一个很新颖的描述。
- 在此之后的研究则大多是不断在文献 NIC 的基础上,从不同的卷积神经网络编码模型、不同的循环神经网络语言模型、不同的编码输入方式和不同的词嵌入(Word Embedding)等方面考虑,对其进行改进
- CNN:卷积层为特征提取层,而激活层是特征映射层
- LSTM:输入门和遗忘门用于控制输入记忆神经元的数据,而输出门控制输入隐含层的数据对其输出的影响
评价策略
原理是比较机器翻译结果 ( candidate) 和人工翻译结果 ( reference) 的相似度。
-
BLEU方法是一种基于精度的度量方法, 主要思想是衡量生成的句子与参考句子之间的 n-Gram 精度, 用"B-n" 表示所有精度的平均值, 取值在 (0; 1] 之间,其值越大, 表明模型在该 “B-n” 上的效果越好; 在不同的 “B-n” 之间, n 越大, 表示生成的句子连贯性越好.。
-
METEOR 自动评测方法既考虑了准确率, 也考虑了召回率。 首先使用任意匹配的方式将参考句子与生成句子中的单词按照精准匹配、 同义匹配和前缀匹配的方式依次寻找匹配的最大值, 当三种匹配的最大值存在相同时, 选择按顺序两两匹配中交叉数最少的匹配作为 “对齐(alignment)”; 通过不断代, 生成对齐集合, 然后将该集合中元素的个数与参考句子中单词总数的比值作为召回率, 与生成句子中单词总数的比值作为准确率, 然后使用调和平均值的方式计算最终值, 取值在 (0; 1] 之间, 其值越大, 说明生成的句子质量越高。
-
ROUGE 准则定义最长公共子序列来计算相似度,序列要求有顺序不一定连续。
-
CIDEr 评价方法 引入了 “共识” 的概念, 通过计算生成句子和人工标注的参考句子之间的余弦距离对生成句子进行评价, 其值越大, 表明生成句子与图像中所有参考句子之间的语义相似度越大。
BLEU指数同时采用了长度惩罚和非长度惩罚的计算结果,它反映了生成结果与参考答案之间的N元文法准确率。
METEOR测度基于单精度加权调和平均数和单字召回率。
Rouge与BLEU 类似,它是基于召回率的相似度衡量方法。
CIDEr是基于共识的评价方法,优于上述其他指标。
平行语料库:
源语言和目标语言中的句子对通常具有相似的句子结构(通常包括规则短语和相同的单词顺序)
多标签分类中常用的三项指标:
Precision@k表示前k个预测 标签的准确率,即在前k个预测标签中正确的标签个数除以k;
![]()
Recall@k表示前k个预测标签的召回率,即在前k个预测标签中正确的标签个数除以答案中的总标签个数;
![]()
其中,y为真实标签,yˆ 是预测标签
F1@k表示对前k个预测标签的准确率和召回率计算加权调和平均
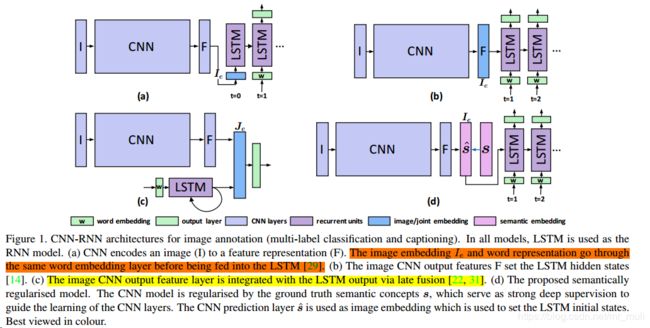
CNN-RNN:CNN的图像嵌入与LSTM不同连接方式:
(图来自:2017–S-CNN-RNN–《Semantic Regularisation for Recurrent Image Annotation》)
利用外部知识图
《Improving Image Captioning by Leveraging Knowledge Graphs》
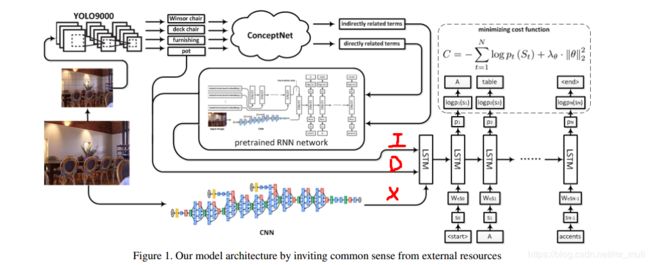
2019–CNet-NIC:首先YOLO9000检测图像中的对象,然后利用ConceptNet提供直接相关的术语和间接相关的术语,将D,I和X的合并作为LSTM 的初始化输入
YOLO9000:被检测到的物体和直接相关的术语提供了关于图像中单个物体的更多信息,而间接相关的术语提供了关于整个场景的信息
ConceptNet:一个有标签的图,它将自然语言的单词和短语连接起来,这些单词和短语的边缘表示它们之间的常识关系,从而推断出一组直接或间接与描述对象识别模块在场景中找到的对象的单词相关的术语
利用图像标签信息:
《Image Captioning with Semantic Attention》
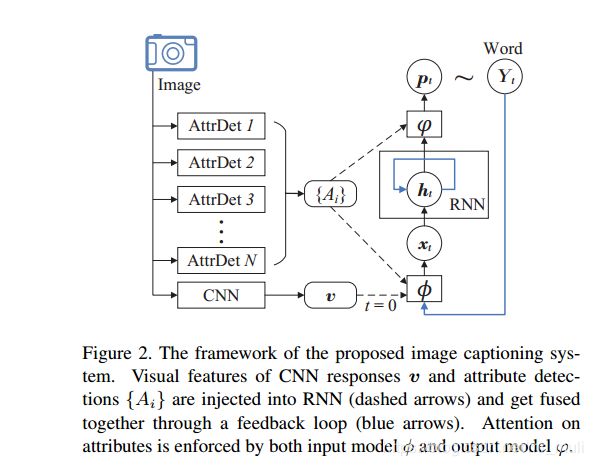
2016–GoogleNet+RNN —自顶向下+自底向上 结合
图像描述有两种基本模式:top-down和bottom-up。
top-down模式就是从图像的一个要素出发,转化它为单词,这类方法很难注意细节。
bottom-up模式首先提出描述图像各个方面的单词,然后组合这些单词,这类方法从独立的方面形成句子,缺少端到端形式的训练。
在《show,attend and tell》中,注意力是以固定的分辨率在空间上建模的。在每次重复迭代时,该算法计算一组与预定义的空间位置相对应的注意权值。相反,本文可以在图像中任何分辨率的任何地方使用概念。事实上,本文甚至可以使用在图像中没有直接视觉存在的概念。
对于这个attributes, 文章提出了三种方法来提取,分别是:
- 用图像的caption在数据库以KNN最近邻方法查找相近的图片,并选择其标签
- 使用多标签排序的分类器(Multi-label Ranking)
- 使用全卷积网络(FCN)
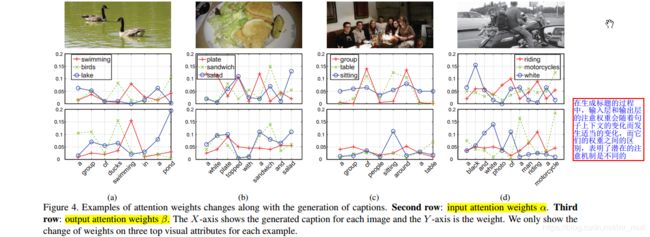
利用 基于区域的多标签分类框架
《Image Captioning and Visual Question Answering Based on Attributesand External Knowledge》
2016-- 只使用 多标签分类 得到的属性向量得分,没有使用 整个图像的特征CNN(I)作为输入
由于每个单词出现在标题中的次数相对较少,将 多示例学习问题 转化为 多标签分类问题。
基于区域的多标签分类框架:
(1)由于有些属性可能只适用于图像的子区域,跟随论文[61]提出多标签分类框架。
(2)需要任意数量的子区域提案作为输入,然后共享CNN与每一个提案,从不同的提案和CNN的输出结果与最大平均池化 聚合生成最终的预测
将CNN特性和属性向量结合起来作为LSTM的输入,但是我们发现这种方法不如只在相同的设置中使用属性向量
另外,本文的 对比试验较多,利用了 PCA 降维,SVM的属性分类, 与论文[61]相比 使用 logistic 损失函数
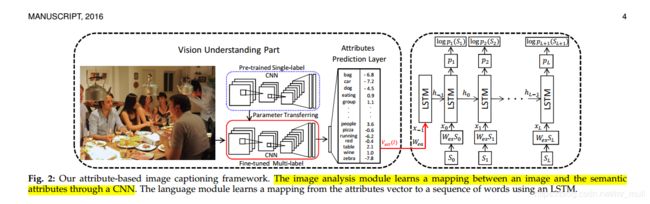
RNN结构及展开形式
参考链接:http://www.alannah.cn/2019/02/16/cnn-rnn-a-unified-framework-for-multi-label-image-classification/
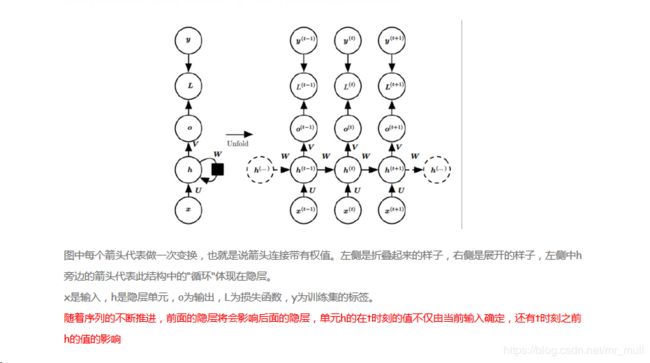 RNN可以看作是一个隐马尔可夫模型的扩展,它采用非线性转换函数,能够对长期时间依赖关系进行建模
RNN可以看作是一个隐马尔可夫模型的扩展,它采用非线性转换函数,能够对长期时间依赖关系进行建模
多示例学习(MIL)
- 多示例学习(MIL)的训练数据集是有标记的,但是标记的标签仅仅包含正和负两个类别,且标记对象的单位不是样本,而是由若干样本组成的袋(bag)。当一个袋被标为负时,这个袋中所有的样本均为负。而当一个袋被标为正时,袋中至少有一个样本为正。模型训练的目标是学习一个分类器,对新的样本输入,能够进行正负标记。
注意力机制(attention)
- 将注意机制运用在图像描述任务的 NIC 模型中,使用的方式大多是先将图像分割成 n个区域,然后直接将图像不同区域的 CNN 特征作为学习注意权重的对象输入语言模型,使得语言模型生成新词时,图像相关部分特征的权重较高,从而让解码器 RNN 要用图片的相关部分来生成描述词语。
Stanford Parser和NTLK对比
由于斯坦福解析器[31]生成的解析树中存在不相关的单词和噪声配置,我们使用ntlk[41]中的pos标记工具和lemmatizer工具同时对源语句进行白化
[31] Parsing natural scenes and natural language with recursive neural networks.
[41] Nltk: the natural language toolkit
图片-语句匹配
《基于语义蕴含关系的图片语句匹配模型》
目前已有的图片-语句匹配方法主要有两大类:
1:将图片和语句映射到一个公共的语义空间, 然后进行两者之间的匹配;
2:采用诸如典型相关分析 (Canonical correlation analysis, CCA)、深度学习等方式来建立图片和语句之间的关联
图像多分类问题
CNN提取图片特征,之后用SVM分类:https://blog.csdn.net/weixin_41036461/article/details/84205924
主要参考第一篇,具体的论文我把论文放到百度网盘中了:
https://pan.baidu.com/s/1Ghh4nfjfBKDyA47fc6M4JQ
有相同的CNN之后使用SVM的一些GitHub的开源代码:
https://github.com/Fdevmsy/Image_Classification_with_5_methods
https://github.com/efidalgo/AutoBlur_CNN_Features
https://github.com/tomrunia/TF_FeatureExtraction