Java Bean 拷贝工具Orika 介绍
首发http://wangbt5191-hotmail-com.iteye.com/blog/1632444, 转载请给出原始链接。
最近笔者在项目调优过程中发现公司的老产品在使用Dozer 做Bean Copy 性能非常慢,发现在这个领域业界还是有很多新秀的。 Orika 应该就算一个比较好的吧。
Orika 的官方主页请戳这里 。 Orika 在自己的官方站点上声称自己是simpler, better and faster Java bean mapping framework 。
性能数据:
废话不多说, 先来上性能数据:
dozerCost_ = 1260ms page number = 1 size = 50
orikaCost_ = 72ms page number = 2 size = 50
dozerCost_ = 53ms page number = 3 size = 50
orikaCost_ = 3ms page number = 4 size = 50
dozerCost_ = 35ms page number = 5 size = 50
...
orikaCost_ = 11ms page number = 994 size = 50
dozerCost_ = 32ms page number = 995 size = 50
orikaCost_ = 2ms page number = 996 size = 50
dozerCost_ = 26ms page number = 997 size = 50
orikaCost_ = 2ms page number = 998 size = 50
dozerCost_ = 36ms page number = 999 size = 50
orikaCost_ = 16ms page number = 1000 size = 50
total orika cost = 2250ms
total dozer cost = 16776ms优势:
1. 性能
大概是Dozer的8-10 倍, 这个上面的已经做了描述
2. 内存消耗
大概是Dozer内存消耗的一半多点。 为什么做到这点的还没想清楚, 估计是因为运行期不需要维护复杂的Mapping 关系。 不需要大量的Mapping 关系查找以及需要的对这些查找优化所消耗的空间。
3. 简单
Orika的代码短小精悍, 而且可读性非常强, Dozer如果要加减一个功能, 不才完全没有信心, Orika 我还是可以偶尔在Orika里面打几个酱油的。
工作原理:
1. 快在哪里
Orika 的工作原理是在预先生成运行期需要运行的目标代码类, 这个类的最终实现类里面就两个方法 mapAtoB 和mapBtoA. 这里我取一个代码片段分析下,
package ma.glasnost.orika.generated;
public class OrikaAbstractVOAbstractBOMapper9079818 extends ma.glasnost.orika.impl.GeneratedMapperBase {
public void mapAtoB(java.lang.Object a, java.lang.Object b, ma.glasnost.orika.MappingContext mappingContext) {
super.mapAtoB(a,b, mappingContext);
com.best.oasis.genidc.biz.common.model.AbstractBO source =
(com.best.oasis.genidc.biz.common.model.AbstractBO) a;
com.best.oasis.genidc.common.vo.AbstractVO destination =
(com.best.oasis.genidc.common.vo.AbstractVO) b;
if(((java.lang.Long)source.getCreatorId()) != null){
destination.setCreatorId(((java.lang.Long)source.getCreatorId()));
}
if(((java.lang.Long)source.getCreatorId()) != null){
if(((java.lang.Long)source.getCreatorId()) != null){
destination.setCreatorName((java.lang.String) mapperFacade.convert(((java.lang.Long)source.getCreatorId()), usedTypes[2], usedTypes[3], "genidcUserNameConverter"));
}
}
if(((java.lang.Long)source.getUpdatorId()) != null){
destination.setUpdatorId(((java.lang.Long)source.getUpdatorId()));
}
if(((java.lang.Long)source.getUpdatorId()) != null){
if(((java.lang.Long)source.getUpdatorId()) != null){
destination.setUpdatorName((java.lang.String) mapperFacade.convert(((java.lang.Long)source.getUpdatorId()), usedTypes[2], usedTypes[3], "genidcUserNameConverter"));
}
}
if(((com.best.oasis.genidc.biz.system.model.SysCodeInfo)source.getStatus()) != null){
if(((java.lang.String)((com.best.oasis.genidc.biz.system.model.SysCodeInfo)source.getStatus()).getCnCodeName()) != null){
destination.setStatusName(((java.lang.String)((com.best.oasis.genidc.biz.system.model.SysCodeInfo)source.getStatus()).getCnCodeName()));
}
}
if(((com.best.oasis.genidc.biz.system.model.SysCodeInfo)source.getStatus()) != null){
if(((java.lang.Long)((com.best.oasis.genidc.biz.system.model.SysCodeInfo)source.getStatus()).getId()) != null){
destination.setStatusId(((java.lang.Long)((com.best.oasis.genidc.biz.system.model.SysCodeInfo)source.getStatus()).getId()));
}
}
if(((com.best.oasis.genidc.biz.system.model.SysCodeInfo)source.getStatus()) != null){
if(((java.lang.String)((com.best.oasis.genidc.biz.system.model.SysCodeInfo)source.getStatus()).getCode()) != null){
destination.setStatusCode(((java.lang.String)((com.best.oasis.genidc.biz.system.model.SysCodeInfo)source.getStatus()).getCode()));
}
}
if(customMapper != null) {
customMapper.mapAtoB(source, destination, mappingContext);
}
}
public void mapBtoA(java.lang.Object a, java.lang.Object b, ma.glasnost.orika.MappingContext mappingContext) {
.....
}
从生成的目标代码来说, 这两个方法的目的就是调父类方法去拷贝父类的映射关系的字段然后拷贝当前类的映射关系的字段。 这个目标生成类已经是和手动写的映射代码一样的了。
这段代码是配置以下配置生成的
com.best.oasis.genidc.biz.common.model.AbstractBO com.best.oasis.genidc.common.vo.AbstractVO status.idstatusId status.cnCodeNamestatusName status.codestatusCode creatorIdcreatorName updatorIdupdatorName creatorIdcreatorId updatorIdupdatorId
Orika 的设计思路就是预先通过javaassist 把Java Bean 之间的映射关系一次性生成目标拷贝方法代码。 这样就可以避免在Bean 映射环节一次次的读取映射规则。 这就是Orika 性能提升的原因。
。 理论上以生成的目标Java 代码来运行映射是拷贝模式所能取到性能最大值的方法。 当然, 如果你说跳出Java, 那要另当别论。
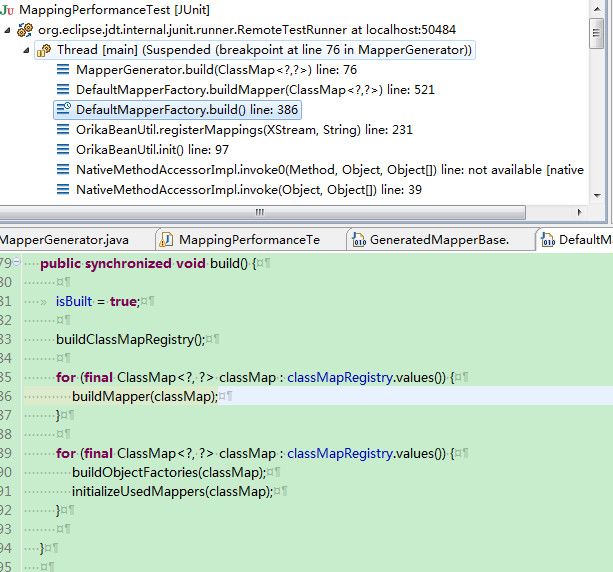
2. 目标代码如何生成
感兴趣的同学我们继续留在这节里面看一下Orika怎么做到生成目标代码的:
Orika 以MapperFactory 来管理Bean-Bean 之间的映射空间和生成客户端使用Map 映射的门脸对象, 在使用之前, Orika 会调用同步的build方法来进行对所有注册的Bean 映射关系进行运行期类生成的工作。
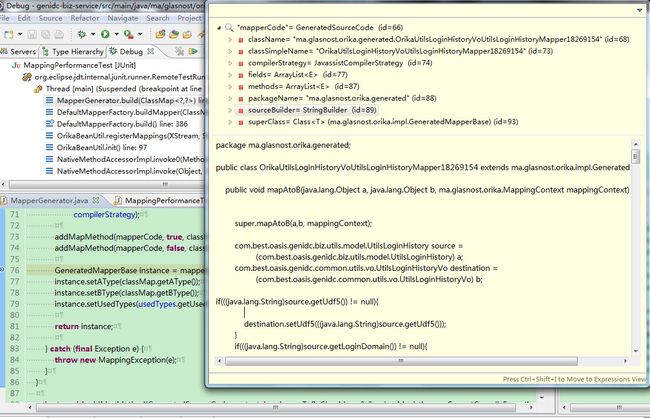
在最终build 方法里面, 生成GeneratedSourceCode mapperCode 实例, 在截图中我们可以看到它维护了一个StringBuilder类型的变量, 这个变量的值就是我们需要生成的最终目标类的源代码。 然后mapperCode会负责调用getInstance 方法来使用StringBuilder中的文本内容编译目标类, 然后获取实例。
有追问精神的同学会问具体如何通过规则得到StringBuilder 里面的文本内容, 就是在上面截图里面的addMapMethod 方法的两次调用做的, 分别生成mapAtoB 和生成mapBtoA 方法, 由于Orika 的良好封装, 这个代码也是非常易懂易读的, 有兴趣的童鞋可以自行去阅读。 我这里只给插几个路标给大家指个大方向。
3. 接下来我们看看映射的时候如何使用目标代码的

从上图的Debug的Trace我们可以看到在映射的时候是会最终调用目标方法的mapAtoB 方法(或者mapBtoA), 通过上面生成的mapAtoB的代码阅读我们可以看到它会调用父类方法的 super.mapAtoB(a,b, mappingContext); 就是截图这里的, 我们可以看到它其实就是做了对要映射bean 的父类映射的关系的属性拷贝。