Hadoop环境搭建与入门实例
1目的及要求
基于Hadoop平台,实现广度优先搜索(BFS)的Mapreduce算法找到图中两个点的最短路径。
给定一个图
2实验环境
本实验基于虚拟机环境,所采用的软件及其版本如下:
虚拟机软件:Oracle VirtualBox 5.2.6
虚拟机操作系统:Ubuntu 16.04.1 LTS - 64 bit
Java环境:JDK-1.8
Hadoop平台:Hadoop 2.7.6
3实验内容与步骤
3.1实验环境搭建
3.1.1搭建Java开发环境
1)键入如下命令将jdk软件包解压至指定目录:
tar -zxvf jdk-8u181-linux-x64.tar.gz -C your_java_home
2)键入如下命令编辑profile文件:
sudo vim /etc/profile
设置jdk环境变量,在profile文件的末尾添加如下内容:
export JAVA_HOME=your_java_home
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
需要注意的是,设置CLASSPATH环境变量时,等号后面有个点,代表当前目录。
3)键入如下命令,让环境变量立即生效:
source /etc/profile
4)检查jdk是否安装好,键入如下命令:
java -version
结果如下图所示:

3.1.2搭建Hadoop环境
Hadoop有多种部署模式,包括本地模式,伪分布式模式和完全分布式模式。
其中,本地模式主要用于本地开发调试;伪分布式模式主要用于学习用途,这种模式是在一台机器的不同进程上运行Hadoop的各个模块,伪分布式的意思是虽然各个模块是在各个进程上分开运行的,但是只是运行在一个操作系统上的,并不是真正的分布式。完全分布式模式是生产环境采用的模式,Hadoop运行在服务器集群上。
这里搭建的是伪分布式模式,过程如下:
1)键入如下命令将hadoop软件包解压至指定目录:
tar -zxvf hadoop-2.7.6.tar.gz -C your_hadoop_home
2)键入如下命令,给hadoop添加Java环境变量:
vim your_hadoop_home/etc/hadoop/hadoop-env.sh
在hadoop-env.sh文件中设置JAVA_HOME的位置添加如下内容:
export JAVA_HOME=your_java_home
3)修改hadoop配置文件
首先进入hadoop配置文件目录
cd your_hadoop_home/etc/hadoop
编辑core-site.xml配置文件,在configuration标签之间添加如下内容:

其中,hadoop.tmp.dir用于设置hadoop存储临时文件的目录。
编辑hdfs-site.xml配置文件,添加如下内容:

其中,dfs.name.dir与dfs.data.dir分别用于设置hdfs的namenode和datanode存储数据。
4)格式化hdfs,命令如下:
your_hadoop_home/bin/hdfs namenode -format
5)键入如下命令,启动hdfs:
your_hadoop_home/sbin/start-dfs.sh
启动完毕后,使用jps命令可以查看当前运行的Java进程,如下图所示:

hdfs启动后,在浏览器中输入如下地址,可以进入hadoop的管理界面:
http://localhost:50070/
如下图所示:
在网页的Utilities-Browse the file system子页面,可以查看当前存储在hdfs里的内容。
3.2实验步骤
1)准备可执行jar文件
根据实验要求,使用Java语言编写程序,程序分为两个模块,预处理模和MapReduce迭代模块。其中,预处理模块包括Preprocess.java一个源文件,迭代模块包括Mainjob.java和Node.java两个源文件。由于程序中使用了Hadoop的类库,在源文件编译时需要在classpath中加入Hadoop的类库所在路径,使用如下命令进行编译:
javac Preprocess.java Node.java Mainjob.java -cp `hadoop classpath`
需要注意,hadoop classpath两边的是反单引号,通过执行hadoop classpath这一命令,可以返回Hadoop的类库路径。
编译完成后,使用jar命令将两个模块编译生成的类分别打包成两个jar文件,并命名为preprocess.jar和mainjob.jar。
2)上传输入文件到HDFS
在hdfs启动后,首先在hdfs中创建目录:
your_hadoop_path/bin/hdfs dfs -mkdir -p /BFS/10000EWG/input
然后使用如下命令将欲处理的文件上传到hdfs:
your_hadoop_path/bin/hdfs dfs -put 10000EWG.txt /BFS/10000EWG/input
3)执行程序
在准备好可执行jar文件和待处理的输入文件后,首先提交预处理程序至Hadoop平台运行:
your_hadoop_path/bin/hadoop jar preprocess.jar
然后提交执行MapReduce循环迭代程序:
your_hadoop_path/bin/hadoop jar mainjob.jar
4)程序运行输出
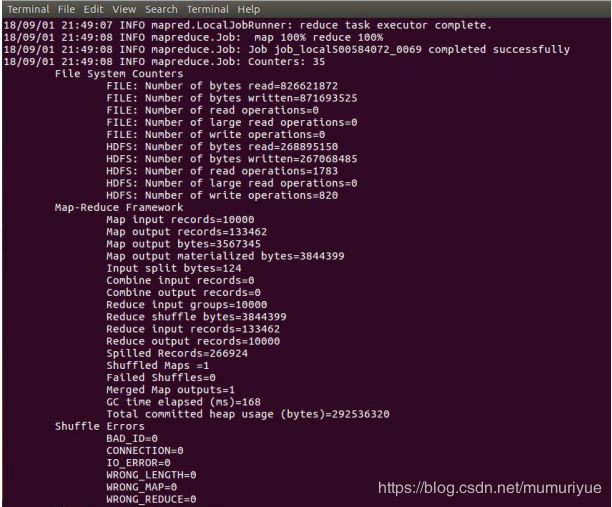
预处理程序运行较快,主处理模块由于包含大量迭代步骤运行较慢,通过程序输出可知,共迭代了69次(以10000EWG.txt为输入数据),如下图所示:
在HDFS中保存了迭代过程中生成的中间文件,如下图所示:
4实验结果与数据处理
4.1 MapReduce介绍
MapReduce是由Google提出的一种分布式计算模型,用于解决海量数据的计算问题。MapReduce计算模型的原理是:利用一个输入key/value对集合来产生一个输出的key/value对集合。MapReduce库的用户用两个函数表达这个计算:Map()和Reduce()。用户自定义的Map函数接受一个输入的key/value对值,然后产生一个中间key/value对值的集合。MapReduce库把所有具有相同中间key值的中间value值集合在一起后传递给Reduce函数。用户自定义的Reduce函数接受一个中间key的值和相关的一个value值的集合。Reduce函数合并这些具有相同key的value值,从而形成一个较小的key/value对集合。
4.2 Dijkstra算法
Dijkstra算法使用了广度优先搜索解决赋权有向图或者无向图的单源最短路径问题。下面来回顾一下该算法的步骤:
1)把所有结点的标识都设为UNVISITED,距离设为INFINIT。
2)把出发点s的距离设置为0,状态设置为VISITED。
3)从图中所有UNVISITED的点中选择距离最小的结点v。
4)设置v的状态为VISITED。
5)用v来更新其相邻结点。若某相邻结点u的当前距离D[u] > D[v] + weight(v, u),则把u的距离D[u]更新为D[v] + weight(v, u)。
6)重复3到5步的操作,直到所有结点状态都被设置为VISITED。
4.3实验数据处理
在实验给出的输入数据中,每一行表示的是任意两个顶点间的距离,为了便于使用最短路径算法,要先对数据进行预处理,使每一行表示顶点到其所有相邻定点距离的形式。
基于map-reduce的并行最短路径算法和Dijkstra算法类似,也是基于迭代的思想。它每次迭代执行一个map-reduce job,并且只遍历一个顶点。在Map中,它先输出这个顶点的完整邻接顶点数据,然后遍历该顶点的邻接顶点,并输出该顶点ID及距离。在Reduce中,对当前顶点,遍历map的输出权重,若比当前的路径值小,则更新。最后输出当前该顶点到其它定点的距离,作为下一次迭代的输入。