机器学习ensemble之stacking方法及新手的坑
tags: [机器学习, ensmeble]
-
- Bagging
- Boosting
- Stacking&blending
- 理解
- 错误认知
- 正确认知
- 多维数据的处理办法
- 方法一
- 方法二(reshape)
- Resources:
原始博客查看:小白机器学习博客
Ensembel(集成学习)是一个简单,但非常有效的算法,在各大kaggle竞赛中,获得很高排名的,很多都应用了ensemble方法。这里是对ensemble learning 进行优秀资源的整理,便于以后查看。
了解集成学习可以从这篇blog开始:
集成学习(ensemble learning)原理详解
常见的Ensemble方法有这2种:Bagging and boosting。还有现在越来越多的stacking and blending。
Bagging
Bagging 算法如下图,通过随机采样训练集,进行训练,采集T个训练集,就训练T个弱学习器。然后通过一定的结合策略,如取平均,或者vote等形式变成一个强学习器。采集训练集时,是有放回的采集。

Boosting
从图中可以看出,Boosting算法的工作机制是首先从训练集用初始权重训练出一个弱学习器1,根据弱学习的学习误差率表现来更新训练样本的权重,使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的弱学习器2中得到更多的重视。然后基于调整权重后的训练集来训练弱学习器2.,如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器。
Boosting系列算法里最著名算法主要有AdaBoost算法和提升树(boosting tree)系列算法。提升树系列算法里面应用最广泛的是梯度提升树(Gradient Boosting Tree)。AdaBoost和提升树算法的原理在后面的文章中会专门来讲。From: link

Stacking&blending
理解
数据比赛大杀器—-模型融合(stacking&blending)
大话机器学习之STACKing,一个让诸葛亮都吃瘪的神技
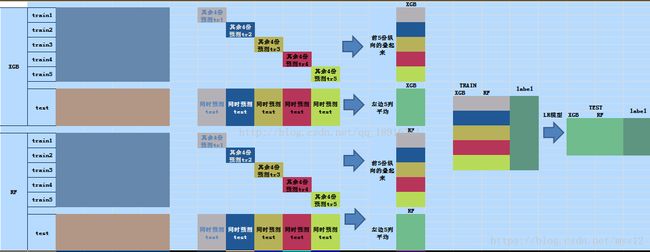
错误认知
研究了stack技能有一阵子,查到的资料和代码基本上都是这样的。里面给的图如下图

看他的代码怎么都不能理解。KFold,cross-validation不是应该一个model就要训练了5次吗?为什么图中是用一个**model来训练一个Fold集,而代码中是每个model都要训练每个**fold集。
所以大部分转载或者写的stack方法都是错误的?不一定,有可能是没注意,有可能他们理解方式不一样。可惜对新手的我们很具有误导性啊。下文的中的作者就遇到跟我一样的情况。
正确认知
感谢这篇文章的作者跟我有一样的疑虑,正确的图应该是下面这样的。
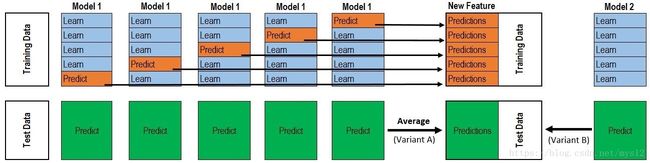
对于每一轮的 5-fold,Model 1都要做满5次的训练和预测, 之后的得到第一层的预测集P1,
model 2做满5次训练和预测,预测的集合是P2,once again, P3, P4, P5。 [P1,P2,P3,P4,P5]作为第二层训练集的input part. output part仍然是整个train set的label.
testset 在model 1中,每一次的训练就预测一次,总共有[T1,T2,T3,T4,T5],我们这时候后,取 mean[T1,T2,T3,T4,T5] m e a n [ T 1 , T 2 , T 3 , T 4 , T 5 ] 作为我们下一层的测试集 t1,同样道理,model 2时,得到t2,….第二层的测试集就是[t1,t2,t3,t4,t5],label仍然时整个test set的label.
附上该作者的代码解释:

多维数据的处理办法
以及我自己项目的部分代码。我的项目label值是一个二维的坐标,所以情况相比一维要复杂的多。在存储第二层的数据时,花了很多力气。
from sklearn.model_selection import KFold
kf = KFold(n_splits=5, random_state=2018)
def get_oof(clf, X_train, y_train, X_test):
blend_train = np.zeros((y_train.shape[0],2)) # 二维label值
blend_test = np.zeros((X_test.shape[0],2))
blend_test_skf = np.zeros((X_test.shape[0],2,5)) # 5是因为有5次训练
for i, (train_index, test_index) in enumerate(list(kf.split(X_train))):
print("Fold", i)
kf_X_train = X_train[train_index]
kf_y_train = y_train[train_index]
kf_X_test = X_train[test_index]
kf_y_test = y_train[test_index]
model = clf(kf_X_train,kf_y_train)
blend_train[test_index]=model.predict(kf_X_test) #
blend_test_skf[:,:,i] = model.predict(X_test) #
blend_test[:,:]=blend_test_skf.mean(axis=2)
return blend_train, blend_test之后需要把P1,P2,P3,P4,P5给整合到表格中,因为P本身是坐标,2维的。就像这个样子。
| P1 | P2 | P3 | P4 | P5 |
|---|---|---|---|---|
| (34,45) | (22,44) | (27,56) | (43,56) | (12,34) |
| … | … | … | … | … |
方法一
跟我们处理的一维数据很不一样。首先怎么把P1,P2…组合起来就是个问题。用np.column_stack? 不行,那个函数只能表示一维。我们可以设置新的3D矩阵
train = np.zeros((len(p1),2,5)),
train[:,:,0] = P1
train[:,:,1] = P2
...同样的道理,得到的 test的三维数据。
怎么来训练呢。一般的算法都是二维数据,当然也有一些算法是支持多维的,如KNN, decisiontree, extratree(看到有这样说的,但我还没尝试过,KNN试过可以)。
方法二(reshape)
利用reshape函数,把二维变1维, x_coordinate 对应 X_label, y_coordinate 对顶Y_label。转化成1维的情况,就很方便了。利用np.column_stack组合5个model得到的数据集。然后进行有监督训练,之后也可以再处理转化成二维的数组(x_coordinate,y_coordinate)。
def reshaped(predict):
size = predict.shape[0]
j = predict.reshape((2*size, 1))
return jResources:
Kaggle机器学习之模型融合(stacking)心得
Ensemble Learning-模型融合-Python实现
KAGGLE ENSEMBLING GUIDE
总结Kaggle-Ensemble-Guide