python知识梳理三 —— dict & 对象
文章目录
- 1.dict
- 2.对象
1.dict
1. dict属于mapping类型
from collections.abc import Mapping, MutableMapping
#dict属于mapping类型
a = {}
print (isinstance(a, MutableMapping)) # True
2.dict常用方法
a = {"bobby1":{"company":"imooc"},
"bobby2": {"company": "imooc2"}
}
# 1.clear
# a.clear()
# pass
# 2.copy, 返回浅拷贝
new_dict = a.copy()
new_dict["bobby1"]["company"] = "imooc3"
# 深拷贝
# import copy
# new_dict = copy.deepcopy(a)
# new_dict["bobby1"]["company"] = "imooc3"
# 3.formkeys
new_list = ["bobby1", "bobby2"]
new_dict = dict.fromkeys(new_list, {"company":"imooc"})
# 4.get
value = new_dict.get('bobby1', {})
# 5.items
for key, value in new_dict.items():
print(key, value)
# 6.setdefault
defauult_value = new_dict.setdefault('bobby', 'imooc')
# 7.update
new_dict.update(bobby='imooc')# 传递单个值
new_dict.update(bobby='imooc', bobby3='imooc') # 传递多个值
new_dict.update([('bobby', 'imooc')]) # list里面放tuple
new_dict.update((("bobby","imooc"),)) # tuple中放tuple
3.继承
不建议继承list和dict
from collections import UserDict
class Mydict(UserDict):
def __setitem__(self, key, value):
super().__setitem__(key, value*2)
my_dict = Mydict(one=1) # {'one': 2}
4.set集合
set 集合 fronzenset (不可变集合) 无序, 不重复,set性能很高(可以查看源码查询方法)
s = frozenset("abcde") # frozenset 可以作为dict的key
5.测试python中dict和set性能
参考代码:https://github.com/liyaopinner/AdvancePython_resource
注意
1、dict查找的性能远远大于list
2、在list中随着list数据的增大 查找时间会增大
3、在dict中查找元素不会随着dict的增大而增大
1. dict的key或者set的值都必须是可以hash的
不可变对象都是可hash的, str, fronzenset, tuple,自己实现的类可以重载 hash
2. dict的内存花销大,但是查询速度快, 自定义的对象 或者python内部的对象都是用dict包装的
3. dict的存储顺序和元素添加顺序有关
4. 添加数据有可能改变已有数据的顺序
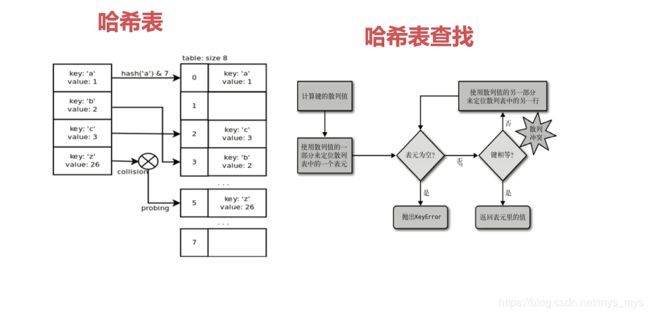
2.对象
1.什么是对象?is & ==
python和java中的变量本质不一样,python的变量实质上是一个指针 int str, 便利贴
intern机制
优点:在创建新的字符串对象时,会先在缓存池里面找是否有已经存在的值相同的对象(标识符,即只包含数字、字母、下划线的字符),如果有,则直接拿过来用(引用),避免频繁的创建和销毁内存,提升效率。
a = 1
a = "abc"
#1. a贴在1上面
#2. 先生成对象 然后贴便利贴
# is & ==
a = [1,2,3]
b = a
print (id(a), id(b)) # 2565188837960 2565188837960
print (a is b) # True
# is:判断是否为同一个对象 (id(a), id(b))
a = [1,2,3,4]
b = [1,2,3,4]
print (id(a), id(b)) # 2565188838024 2565190064200
print (a is b) # False
# python intern机制
a = 1 # 建立一个全局为1的对象
b = 1 # a与b是同一个对象
print (a is b) # True
2.垃圾回收机制
python中垃圾回收的算法是采用 引用计数
a = 1 # a指向1
b = a # b指向1
del a # 1的计数 减少一个,如果减少到0,就被垃圾回收机制回收
a = object()
b = a # a b指向同一个对象
del a
print(b)
# print(a) # 报错
class A:
def __del__(self):
pass
3.一个错误
def add(a, b):
a += b
return a
class Company:
# 尽量不要传递list(可修改)
def __init__(self, name, staffs=[]):
self.name = name
self.staffs = staffs
def add(self, staff_name):
self.staffs.append(staff_name)
def remove(self, staff_name):
self.staffs.remove(staff_name)
if __name__ == "__main__":
com1 = Company("com1", ["bobby1", "bobby2"])
com1.add("bobby3")
com1.remove("bobby1")
print (com1.staffs) # ['bobby2', 'bobby3']
com2 = Company("com2")
com2.add("bobby")
print(com2.staffs) # ['bobby']
print (Company.__init__.__defaults__) # (['bobby'],)
com3 = Company("com3")
com3.add("bobby5")
# 注意 *************************************
# 没有传递list参数时,会默认指向Company.__init__.__defaults__
# 因此com2和com3是共用的
print (com2.staffs) # ['bobby', 'bobby5']
print (com3.staffs) # ['bobby', 'bobby5']
print (com2.staffs is com3.staffs) # True
# a = 1
# b = 2
# c = add(a, b)
# print(c) # 3
# print(a, b) # 1 2
# a = [1,2]
# b = [3,4]
# c = add(a, b)
# print(c) # [1, 2, 3, 4]
# # 注意 *******************
# print(a, b) # [1, 2, 3, 4] [3, 4]
# a = (1, 2)
# b = (3, 4)
# c = add(a, b)
# print(c) # (1, 2, 3, 4)
# print(a, b) # (1, 2) (3, 4)