机器学习集成学习算法——boosting系列
本篇基于机器学习(edt:周志华)的集成学习章节,衍生学习多种boosting集成学习算法。
集成学习(ensemblelearning)通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统(multi-calssifiersystem)。

目前的集成学习方法大致可以分为两大类:
前者的代表是Boosting,后者的代表是Bagging。

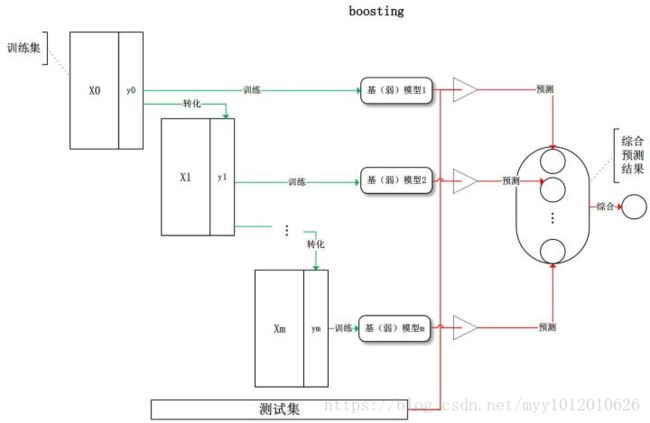
Boosting 是一种将弱分离器 组合起来形成强分类器F(x)的框架,一般地,Boosting算法有三个要素:
1)函数模型:Boosting是加法函数,又叫叠加型的: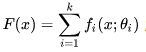
2)目标函数:选定某种损失函数作为优化目标:![]()
3)优化算法:贪婪地逐步优化,即
以下介绍几种典型的boosting算法,包括:AdaBoost、GBDT、XGBoost、lightGBM、CatBoost
一、AdaBoost算法

AdaBoost算法的主要原理:
优点:
缺点:

- base_estimator:基学习器,默认CART分类树
- n_estimators:最大的弱学习器的个数,默认50
- learning_rate:每个弱学习器的权重缩减系数
- Algorithm:SAMME和SAMME.R(默认)
二、GBDT算法(Gradient Boosting Decision Tree)
AdaBoost是通过提升错分数据点的权重来定位模型的不足,而Gradient Boosting是通过算梯度(gradient)来定位模型的不足。
模型可以表示为: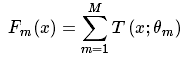
弱分类器的损失函数: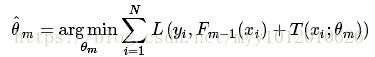
模型一共训练M轮,每轮产生一个弱分类器 T(x;θm) 。
过程:利用损失函数的负梯度在当前模型的值作为回归问题提升树算法中的残差的近似值去拟合一个回归树。gbdt每轮迭代的时候,都去拟合损失函数在当前模型下的负梯度。这样每轮训练的时候都能够让损失函数尽可能快的减小,尽快的收敛达到局部最优解或者全局最优解。
优点:
1)可以灵活处理各种类型的数据,包括连续值和离散值。
2)在相对少的调参时间情况下,预测的准确率也可以比较高(相对SVM)。
3)使用一些健壮的损失函数,对异常值的鲁棒性非常强。比如 Huber损失函数和Quantile损失函数。
缺点:
1)由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过自采样的SGBT来达到部分并行。
在scikit-learn中,GradientBoostingClassifier为GBDT的分类类

- n_estimators:最大迭代基学习器个数,默认100
- learning_rate:每个弱学习器的权重缩减系数,默认0.1
- subsample:子采样,取值为(0,1],1为全部采样,即没有子采样(无放回)
- loss: 损失函数。
三、XGBoost算法

GBDT是以决策树(CART)为基学习器的GB算法,Xgboost扩展改进了GBDT。Xgboost算法更快,准确率也相对高一些,LightGBM则是在Xgboost的基础上根据Xgboost存在的缺点,进一步改进优化。
改进点:
1、GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。允许用户定义自定义优化目标和评价标准,只要一、二阶可导即可。
2 、 xgboost 在代价函数里加入了正则项,用于控制模型的复杂度。从 Bias-variance tradeoff 角度来讲,正则项降低了模型 variance ,使学习出来的模型更加简单,防止过拟合,这也是 xgboost 优于传统 GBDT 的一个特性。
3、对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。Xgboost把缺失值当做稀疏矩阵来对待,本身的在节点分裂时不考虑的缺失值的数值。缺失值数据会被分到左子树和右子树分别计算损失,选择较优的一个。
4、支持并行:训练时可以用所有的 CPU 内核来并行化建树,实现并行处理,也支持Hadoop实现。Xgboost使用可并行的近似直方图(histogram)算法,高效地生成候选的分割点。特征粒度上的并行,决策树学习最耗时的是对特征进行排序,xgboost在训练前,预先对数据进行排序保存为Block,后面的迭代重复使用这个结构(排序存储为Block,然后调用Block取特征)
5、模型的可扩展性:GBDT以CART作为基分类器,xgboost还支持线性分类器(gblinear)。
6、剪枝:XGBoost分裂到指定的树的最大深度,反向剪枝,去掉不再有正值的分裂。
7、内置交叉验证:Xgboost允许在boosting处理中每轮迭代进行交叉验证。因此,很容易得到boosting迭代单次运行的最佳次数。交叉验证时可以返回模型在每一折作为预测集时的预测结果,方便构建ensemble模型。
8、输出特征重要性:可以给出训练好的模型的特征重要性,可以基于此对模型进行特征选择。
在python中实现需手动安装xgboost包

四、lightGBM
LightGBM 是一个基于树学习的梯度提升框架,支持高效率的并行训练,它有以下优势:
- 更快的训练效率 - 低内存使用 - 更好的准确率
- 支持并行和GPU -可处理大
算法原理——
先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。

•多线程优化:特征并行的主要思想是在不同机器在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。
· 设定更大的max_bin值(但会拖慢速度)
· 设定较小的learning_rate值,较大的num_iterations值
· 设定大的num_leaves值(但容易导致过拟合)
· 加大训练集数量(更多样本,更多特征)
· 试试boosting= dart更
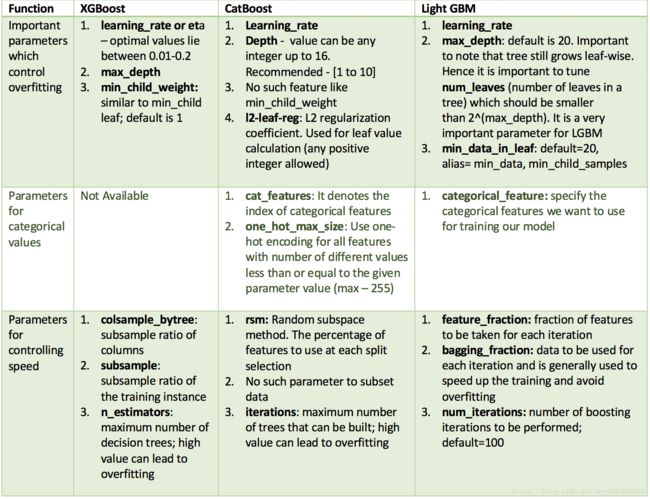
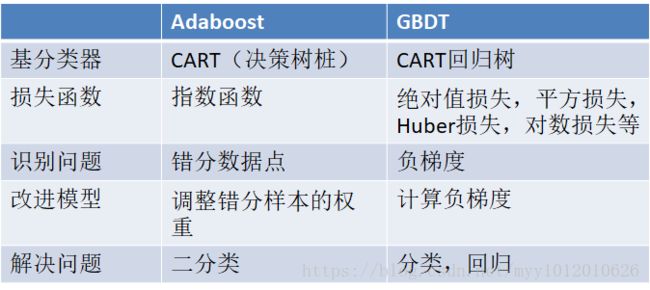
五、算法对比
在实际使用的过程中,给我一个最直接的感觉就是LightGBM的速度比xgboost快很快