UntrimmedNets for Weakly Supervised Action Recognition and Detection 翻译+学习笔记
我们从未修剪的视频中引入一种更有效的直接学习动作识别模型的机制。
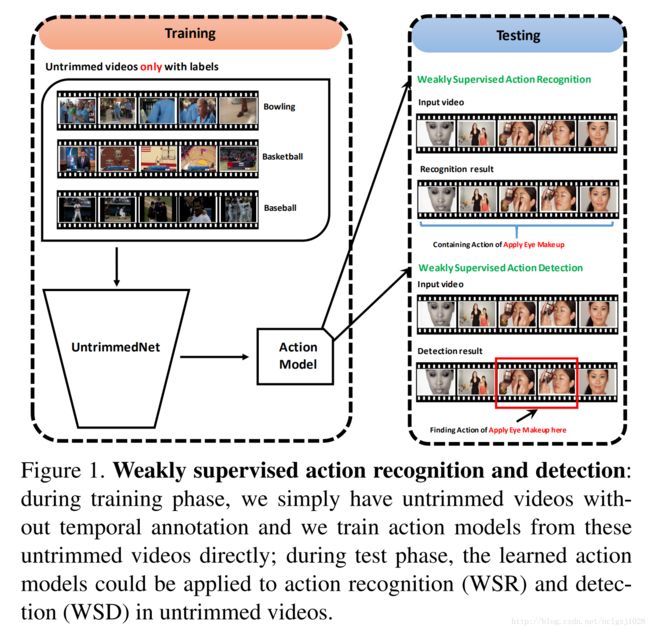
在这个新的设置中,只有视频级的动作标签在训练期间可用,目标是从未修剪的视频中学习模型,可以应用于新的视频,以执行动作识别或检测。
由于训练中对动作实例没有精确的时态注释,因此将其称为弱监督动作识别(WSR)和检测(WSD),WSR和WSD的建立将大大减少人工构建大规模数据集的工作量。
然而,这种弱监督的设置也带来了新的挑战,因为我们的学习算法不仅需要学习每个动作类的视觉模式,而且也要自动推理可能的动作实例的时间位置。
在这项工作中,通过提出一种新的端到端架构,称为UntrimedNet,来解决wsr和wsd问题的挑战。
在没有动作实例的时态注解的情况下,UntrimedNet直接将未修剪的视频作为输入,并利用它的视频标签来学习网络权重。
简而言之,UntrimmedNet主要由两部分组成,即分类模块、选择模块、分别处理学习行为模型和行为实例检测问题。
将分类和选择模块的输出融合在一起,得到未修剪的视频的预测结果,可以利用这些结果以端到端的方式调优UntrimmedNet参数。
具体来说,我们的UntrimedNet首先生成剪辑建议,其中可能包含操作实例,采用均匀或镜头采样。然后,将这些剪辑建议输入UntrimedNet进行特征提取。
基于这些剪辑级表示,当选择模块尝试选择或排列这些剪辑建议时,分类模块的目的是预测每个剪辑提案的分类分数。
在实践中,分类模块的设计是基于一个标准的softmax分类器和由两种替代机制实现选择模块:艰难的选择和软选择。
对于艰难选择,使用top-k池方法来确定最多的k判别剪辑,对于软选择,学习一个注意权重来对不同剪辑的重要性进行排序。
最后的分类结果和选择模块与加权乘法产生的修剪视频水平预测融合。
有了这个视频级预测和全局视频标签,我们能够联合优化分类模块、选择模块以及基于标准反向传播算法的特征提取网络。
我们的UntrimedNet不使用操作实例的时间注释,但与使用强有力的训练监督的最先进的方法相比,它在动作识别和动作检测方面获得了优异的性能。
3. Learning from Untrimmed Videos
首先,我们描述了UntrimmedNets的剪辑方案的方法。其次,详细介绍了UntrimedNet的体系结构设计。
3.1剪辑抽样
动作实例通常描述具有特定意图的连续和连贯的运动模式,这种模式可能持续几秒钟,不包含镜头变化。然而,一个未经修剪的视频往往表现出极其复杂的运动动力学,动作实例可能只占它的一小部分。因此,我们的UntrimedNet首先从未修剪的视频中生成简短的剪辑,这可以作为未修剪的网络培训的行动建议。这可以作为UntrimmedNet网络训练的活动建议。
给出一个没有修剪的视频V,它的长度为T帧,模型的方法是生成一组剪辑建议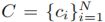 ,N是建议的数目,
,N是建议的数目,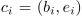 表示地i个建议词ci开始和结束位置。我们设计了两种简单而有效的方法来产生建议:均匀抽样(Uniform sampling)和基于镜头的抽样(shot-based sampling)。
表示地i个建议词ci开始和结束位置。我们设计了两种简单而有效的方法来产生建议:均匀抽样(Uniform sampling)和基于镜头的抽样(shot-based sampling)。
Uniform sampling:
假设行动实例可能具有相对较短的持续时间,建议将视频等分成N个片段![]() 。但这种抽样方法忽略了动作实例的连续和一致性质,并且容易产生不精确的建议。
。但这种抽样方法忽略了动作实例的连续和一致性质,并且容易产生不精确的建议。
Shot-based sampling:
预测每个动作实例都集中在一个镜头内一致的运动上。提出了一种基于镜头变化检测的采样方法。具体而言,我们提取每个帧的HOG特征,并计算相邻帧之间的HOG特征差异。然后,我们用这个差值的绝对值来测量视觉内容的变化,如果它大于一个阈值,就会检测到镜头的变化。在每一个镜头中,我们建议以连续的方式(在实践中将K设置为300)对固定时间的镜头剪辑进行采样,这有助于打破持续时间很长的镜头。
假设我们有一个以![]() 表示的镜头,其中
表示的镜头,其中![]() 表示这个镜头的开始和结束位置,我们从这个镜头中提出建议
表示这个镜头的开始和结束位置,我们从这个镜头中提出建议![]() ,最终最后,我们将来自不同镜头的所有剪辑建议合并为UntrimedNet进行训练。
,最终最后,我们将来自不同镜头的所有剪辑建议合并为UntrimedNet进行训练。
3.2 UntrimmedNets
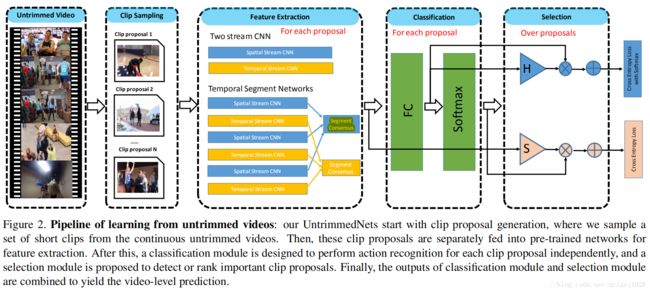
如图2所示,UntrimedNet的体系结构由一个特征提取模块、一个分类模块和一个选择模块组成。这些不同的组件都是设计成可区分的,并以端到端的方式使未剪裁的网络可训练。
特征提取模块在提案生成之后,这些镜头剪辑被输入深层网络中进行特征提取。这些特征表示用于描述剪辑视觉内容,并传递到下一层以进行动作识别。形式上,给出了一套视频V和一组剪辑建议![]() ,对于每个剪辑方案c,我们将表示为
,对于每个剪辑方案c,我们将表示为![]() 。我们的UntrimedNet是一个弱监督的动作识别和检测的通用框架,它不依赖于特征提取网络的选择。在实验中,我们尝试了两种架构: 有着更深层结构的Two-Stream CNN[40]和具有相同的体系结构的时间段的网络[50]。更多细节将在第5节中介绍。
。我们的UntrimedNet是一个弱监督的动作识别和检测的通用框架,它不依赖于特征提取网络的选择。在实验中,我们尝试了两种架构: 有着更深层结构的Two-Stream CNN[40]和具有相同的体系结构的时间段的网络[50]。更多细节将在第5节中介绍。
分类模块
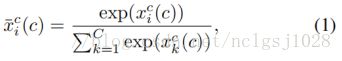
其中![]() 表示
表示![]() 第i个的维数。为了清晰起见,我们使用符号
第i个的维数。为了清晰起见,我们使用符号![]() 来表示剪辑方案c的原始分类分数,并使用
来表示剪辑方案c的原始分类分数,并使用![]() 表示Softmax分类分数。这两种类型的分类分数略有差异。原来的分类得分
表示Softmax分类分数。这两种类型的分类分数略有差异。原来的分类得分![]() 对原始类激活进行编码以及它的响应能够反映包含特定动作类的程度。在不包含操作实例的情况下,它的值对于所有类都可能非常小。然而,Softmax分类评分
对原始类激活进行编码以及它的响应能够反映包含特定动作类的程度。在不包含操作实例的情况下,它的值对于所有类都可能非常小。然而,Softmax分类评分![]() 经历了规范化运算,并将其和转化为1。如果在这个剪辑中有一个动作实例,这个Softmax分数可以编码动作类分布的信息。但对于背景剪辑,这种归一化操作可能会放大噪声激活,其响应可能无法正确编码视觉信息。
经历了规范化运算,并将其和转化为1。如果在这个剪辑中有一个动作实例,这个Softmax分数可以编码动作类分布的信息。但对于背景剪辑,这种归一化操作可能会放大噪声激活,其响应可能无法正确编码视觉信息。
选择模块的目标是选择那些最可能包含行动实例的剪辑建议。为此,我们设计了两种选择机制:基于多实例学习原理的硬选择(Mil)[6]和基于注意模型的软选择。[31, 53].从实验中可以看出,这两种选择方法都能很好地解决弱监督学习问题。
在硬选择方法中,我们尝试为每个动作类识别k剪辑建议(实例)的子集。灵感来自多实例学习的想法,我们选择最高K分类实例最高的分类分数,然后在这些选定的实例之间的平均值。应该注意的是,在这里,我们使用原始的分类评分,因为它的值能够正确地反映包含某些动作实例的可能性。
在硬选择方法中,我们试图确定每个动作类的 k 剪辑建议(实例)的子集。受多个实例学习思想的启发,我们选择了分类得分最高的k个实例,然后在这些选择的实例中进行平均。应该注意的是,在这里,我们使用原始的分类评分,因为它的值能够正确地反映包含某些动作实例的可能性。形式上,让我们使用![]() 对类 i 和实例Cj的选择进行编码,其中,
对类 i 和实例Cj的选择进行编码,其中,![]() 是一组评分最高的剪辑方案指数。
是一组评分最高的剪辑方案指数。
在软选择方法中,我们希望将所有剪辑方案的分类分数结合起来,并学习一个重要的权重来对不同的剪辑方案进行排序。从直觉上看,这些剪辑建议是不是所有相关的行动类,我们可以学习一个注意权重,以突出歧视剪辑建议和压制背景剪辑建议。形式上,对于每一个剪辑方案,我们根据特征表示φ(C)的线性变换来学习这个注意权重。即,![]() 其中
其中![]() 是模型参数。然后,通过一个Softmax层传递不同剪辑方案的注意权重,并相互比较如下:
是模型参数。然后,通过一个Softmax层传递不同剪辑方案的注意权重,并相互比较如下:
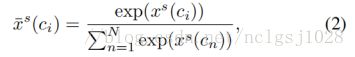
其中![]() 是表示剪辑建议C的原始的选择分数。
是表示剪辑建议C的原始的选择分数。![]() 是softmax选择得分。应该注意的是,在分类模块中,Softmax操作 (Eq.(1))分别应用于不同动作类的分类分数,而在选择模块中,这个操作(Eq.(2))在不同的剪辑方案之间执行。尽管具有相似的数学公式,但这两个Softmax层的设计目的分别是为了分类和选择。
是softmax选择得分。应该注意的是,在分类模块中,Softmax操作 (Eq.(1))分别应用于不同动作类的分类分数,而在选择模块中,这个操作(Eq.(2))在不同的剪辑方案之间执行。尽管具有相似的数学公式,但这两个Softmax层的设计目的分别是为了分类和选择。
视频预测
最后,通过将分类和选择分数相结合,可以得到未修剪的视频V的预测评分![]() 。具体来说,对于硬选择,我们只需将所选的top-k实例简单的求个平均:
。具体来说,对于硬选择,我们只需将所选的top-k实例简单的求个平均:
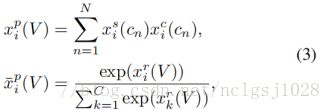
其中![]() 分别是剪辑方案Cn的硬选择指标和分类评分。我们的硬选择的模块是基于原来的分类得分,我们需要执行一个softmax操作规范汇总视频水平得分。
分别是剪辑方案Cn的硬选择指标和分类评分。我们的硬选择的模块是基于原来的分类得分,我们需要执行一个softmax操作规范汇总视频水平得分。
在软选择的情况下,由于我们已经学会了一个注意权重来对这些剪辑建议进行排序,我们只需使用加权求和来组合分类和选择m的分数。下列模块:
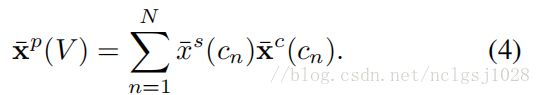
在这里,与硬选择不同,我们对每个剪辑方案使用Softmax分类评分,因为这种标准化分数将使注意力权重学习更容易和更稳定。注意方程(4)形成概率向量的凸组合。因此,不需要进一步的正常化。
3.3. 训练
在前一小节介绍了UntrimedNet体系结构之后,我们将讨论如何优化模型参数。特征提取、分类模块和选择模块的组成采用前馈神经网络实现,这些神经网络与模型参数都是可微的。因此,根据强监督体系结构(如双流cnn)的训练方法,我们采用了具有交叉熵损失的标准反向传播方法。
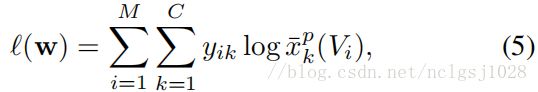
其中,如果视频Vi包含k个类别的动作实例,则![]() 设置为1,否则为0,则M是训练视频的数量。在训练期间,权重衰减率为0.0005。对于包含多个类的动作实例的视频,我们首先用它的L1-范数[51]规范标签向量y,即,
设置为1,否则为0,则M是训练视频的数量。在训练期间,权重衰减率为0.0005。对于包含多个类的动作实例的视频,我们首先用它的L1-范数[51]规范标签向量y,即,![]() ,然后使用这个规范化的标号向量y来计算交叉熵损失。
,然后使用这个规范化的标号向量y来计算交叉熵损失。
4.动作识别与检测
在介绍了UntrimedNet直接从未修剪的视频中学习之后,我们现在开始描述如何利用这些学习到的模型在未修剪的视频中进行动作识别和检测。
行为识别由于我们的未剪裁网是建立在two-stream CNN[40]或时间段网络[50]上的,所以所学习的模型可以看作是片段级分类器。根据以往方法[40,50,52]的识别流程,我们在未修剪的视频中对动作识别进行分段评估。在实践中,我们每30帧采样一帧(或5帧光流叠加)。采样帧的识别分数用top-k池(k设置为20)或加权和进行汇总,以得到最终的视频级别预测。
动作检测我们拥有软选择模块的UntrimedNet不仅提供了一个识别分数,同时也为每个片段输出一个注意权重。自然,这种注意力权重可以被用于未修剪的视频中的动作检测(时间定位)。为了实现更精确的定位,我们每15帧进行一次测试,并保持每帧的预测分数和注意力权重。基于注意权值,我们对其进行阈值化(设置为0.0001)来去除背景。最后,在去除背景后,对分类分数进行阈值化(设置为0.5),得到最终的检测结果。