UDAF和UDF的介绍
目录
UDF介绍
UDAF简介
关于UDAF的一个误区
使用UDF
在SQL语句中使用UDF
直接对列应用UDF(脱离sql)
UDAF使用
继承UserDefinedAggregateFunction
继承Aggregator
UDF介绍
UDF(User Define Function),即用户自定义函数,Spark的官方文档中没有对UDF做过多介绍,猜想可能是认为比较简单吧。
几乎所有sql数据库的实现都为用户提供了扩展接口来增强sql语句的处理能力,这些扩展称之为UDXXX,即用户定义(User Define)的XXX,这个XXX可以是对单行操作的UDF,或者是对多行操作的UDAF,或者是UDTF,本次主要介绍UDF。
UDF的UD表示用户定义,既然有用户定义,就会有系统内建(built-in),一些系统内建的函数比如abs,接受一个数字返回它的绝对值,比如substr对字符串进行截取,它们的特点就是在执行sql语句的时候对每行记录调用一次,每调用一次传入一些参数,这些参数通常是表的某一列或者某几列在当前行的值,然后产生一个输出作为结果。
适用场景:UDF使用频率极高,对于单条记录进行比较复杂的操作,使用内置函数无法完成或者比较复杂的情况都比较适合使用UDF。
UDAF简介
先解释一下什么是UDAF(User Defined Aggregate Function),即用户定义的聚合函数,聚合函数和普通函数的区别是什么呢,普通函数是接受一行输入产生一个输出,聚合函数是接受一组(一般是多行)输入然后产生一个输出,即将一组的值想办法聚合一下。
关于UDAF的一个误区
我们可能下意识的认为UDAF是需要和group by一起使用的,实际上UDAF可以跟group by一起使用,也可以不跟group by一起使用,这个其实比较好理解,联想到mysql中的max、min等函数,可以:
| 1 |
|
表示根据bar字段分组,然后求每个分组的最大值,这时候的分组有很多个,使用这个函数对每个分组进行处理,也可以:
| 1 |
|
这种情况可以将整张表看做是一个分组,然后在这个分组(实际上就是一整张表)中求最大值。所以聚合函数实际上是对分组做处理,而不关心分组中记录的具体数量。
使用UDF
在SQL语句中使用UDF
在sql语句中使用UDF指的是在spark.sql("select udf_foo(…)")这种方式使用UDF,套路大致有以下几步:
1. 实现UDF,可以是case class,可以是匿名类
2. 注册到spark,将类绑定到一个name,后续会使用这个name来调用函数
3. 在sql语句中调用注册的name调用UDF
下面是一个简单的示例:
package cc11001100.spark.sql.udf
import org.apache.spark.sql.SparkSession
object SparkUdfInSqlBasicUsageStudy {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("SparkUdfStudy").getOrCreate()
import spark.implicits._
// 注册可以在sql语句中使用的UDF
spark.udf.register("to_uppercase", (s: String) => s.toUpperCase())
// 创建一张表
Seq((1, "foo"), (2, "bar")).toDF("id", "text").createOrReplaceTempView("t_foo")
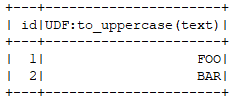
spark.sql("select id, to_uppercase(text) from t_foo").show()
}
}运行结果:
直接对列应用UDF(脱离sql)
在sql语句中使用比较麻烦,还要进行注册什么的,可以定义一个UDF然后将它应用到某个列上:
package cc11001100.spark.sql.udf
import org.apache.spark.sql.{SparkSession, functions}
object SparkUdfInFunctionBasicUsageStudy {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("SparkUdfStudy").getOrCreate()
import spark.implicits._
val ds = Seq((1, "foo"), (2, "bar")).toDF("id", "text")
val toUpperCase = functions.udf((s: String) => s.toUpperCase)
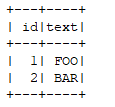
ds.withColumn("text", toUpperCase('text)).show()
}
}运行效果:
需要注意的是受Scala limit 22限制,自定义UDF最多接受22个参数,不过正常情况下完全够用了。
UDAF使用
继承UserDefinedAggregateFunction
使用UserDefinedAggregateFunction的套路:
1. 自定义类继承UserDefinedAggregateFunction,对每个阶段方法做实现
2. 在spark中注册UDAF,为其绑定一个名字
3. 然后就可以在sql语句中使用上面绑定的名字调用
下面写一个计算平均值的UDAF例子,首先定义一个类继承UserDefinedAggregateFunction:
package cc11001100.spark.sql.udaf
import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
object AverageUserDefinedAggregateFunction extends UserDefinedAggregateFunction {
// 聚合函数的输入数据结构
override def inputSchema: StructType = StructType(StructField("input", LongType) :: Nil)
// 缓存区数据结构
override def bufferSchema: StructType = StructType(StructField("sum", LongType) :: StructField("count", LongType) :: Nil)
// 聚合函数返回值数据结构
override def dataType: DataType = DoubleType
// 聚合函数是否是幂等的,即相同输入是否总是能得到相同输出
override def deterministic: Boolean = true
// 初始化缓冲区
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L
buffer(1) = 0L
}
// 给聚合函数传入一条新数据进行处理
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (input.isNullAt(0)) return
buffer(0) = buffer.getLong(0) + input.getLong(0)
buffer(1) = buffer.getLong(1) + 1
}
// 合并聚合函数缓冲区
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
// 计算最终结果
override def evaluate(buffer: Row): Any = buffer.getLong(0).toDouble / buffer.getLong(1)
}然后注册并使用它:
package cc11001100.spark.sql.udaf
import org.apache.spark.sql.SparkSession
object SparkSqlUDAFDemo_001 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("SparkStudy").getOrCreate()
spark.read.json("data/user").createOrReplaceTempView("v_user")
spark.udf.register("u_avg", AverageUserDefinedAggregateFunction)
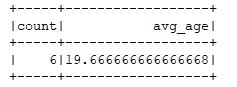
// 将整张表看做是一个分组对求所有人的平均年龄
spark.sql("select count(1) as count, u_avg(age) as avg_age from v_user").show()
// 按照性别分组求平均年龄
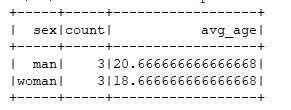
spark.sql("select sex, count(1) as count, u_avg(age) as avg_age from v_user group by sex").show()
}
}使用到的数据集:
{"id": 1001, "name": "foo", "sex": "man", "age": 20}
{"id": 1002, "name": "bar", "sex": "man", "age": 24}
{"id": 1003, "name": "baz", "sex": "man", "age": 18}
{"id": 1004, "name": "foo1", "sex": "woman", "age": 17}
{"id": 1005, "name": "bar2", "sex": "woman", "age": 19}
{"id": 1006, "name": "baz3", "sex": "woman", "age": 20}运行结果:
继承Aggregator
还有另一种方式就是继承Aggregator这个类,优点是可以带类型:
package cc11001100.spark.sql.udaf
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.{Encoder, Encoders}
/**
* 计算平均值
*
*/
object AverageAggregator extends Aggregator[User, Average, Double] {
// 初始化buffer
override def zero: Average = Average(0L, 0L)
// 处理一条新的记录
override def reduce(b: Average, a: User): Average = {
b.sum += a.age
b.count += 1L
b
}
// 合并聚合buffer
override def merge(b1: Average, b2: Average): Average = {
b1.sum += b2.sum
b1.count += b2.count
b1
}
// 减少中间数据传输
override def finish(reduction: Average): Double = reduction.sum.toDouble / reduction.count
override def bufferEncoder: Encoder[Average] = Encoders.product
// 最终输出结果的类型
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
/**
* 计算平均值过程中使用的Buffer
*
* @param sum
* @param count
*/
case class Average(var sum: Long, var count: Long) {
}
case class User(id: Long, name: String, sex: String, age: Long) {
}运行结果: