最全面的MySQL面试题大全-二
继续上篇博客的内容,进行详细的分析以及查询操作。
5. 查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩(没成绩的显示为 null )
分析:看到这道题,首先需要考虑要获得学生姓名以及学生编号必须在学生表中,获取到总成绩必须在成绩表中,这样就又涉及到了多表查询的问题,首先我们先来做个简单的查询操作看一下效果。
select s.sid,s.sname ,count(cid) as zs FROM Student as s, SC;
会发现并不是我们想要的结果,下面就是分析的问题。
首先来分开看一下各自的结果
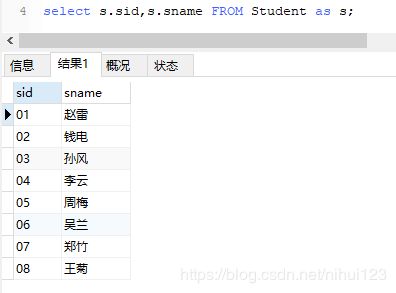
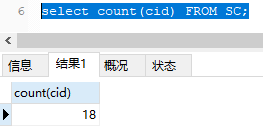
从上面两张图上面可以看到,在查询的时候两个结果是不对等的,但是我们想做的事情是让第二个结果按照第一个结果进行分割。那么我们应该怎么写这个语句呢,也就是说我们要使用第一个结果的条件进行操作。
select s.sid,s.sname,count(cid) as xkzs,sum(score) as zcj
from Student as s LEFT JOIN SC
on s.sid = SC.sid
group BY s.sid;

6.按条件统计老师的数量
分析:按照某个姓氏统计老师的数量,这样的话就是涉及到模糊查询,在MySQL中使用模糊查询主要是使用%进行匹配,例如下面语句就是统计张老师的个数
select count(tname)FROM Teacher WHERE tname LIKE '张%'
7.根据条件查询中所有学生的成绩表。
分析:首先需要查询学生信息涉及到的是一个多表查询的问题,其次这个查询条件和之前的查询条件的区别,在于查询的是所有学生的信息。那么应该如何进行查询。
这里先给出一个结果
select s.* ,a.score as yuwen,b.score as shuxue,c.score as yingyu
from Student s,
(SELECT sid ,score from SC WHERE cid=01) a,
(SELECT sid ,score from SC WHERE cid=02) b,
(SELECT sid ,score from SC WHERE cid=03) c
WHERE s.sid = a.sid and s.sid = b.sid and s.sid = c.sid;
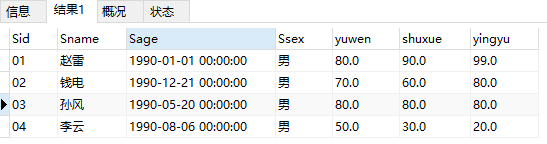
会发现上面的结果并不是我们想要的结果,那么为什么会出现这样的结果呢?我们先了做个分析,首先,给出思路是先从学生表中查到所有学生的信息,然后再从成绩表中获取到所有对应科目的成绩。将两者结合到一起。但是我们会发现一个问题,在成绩表中能同时满足三个条件的数据只有前四个,后面的数据是没有第四个条件的。有了这样的分析之后,对结果进行了如下的改动
select s.* ,a.score as yuwen,b.score as shuxue,c.score as yingyu
from Student s,
(SELECT sid ,score from SC WHERE cid=01) a,
(SELECT sid ,score from SC WHERE cid=02) b,
(SELECT sid ,score from SC WHERE cid=03) c
WHERE s.sid = a.sid and s.sid = b.sid or s.sid = c.sid;
但是这个结果是不合理的,所以采用了一个巧妙的方式。如下
select s.sid,s.sname,count(cid) as xkzs,sum(score) as zcj,
SUM(case WHEN cid = 01 THEN score else null end) as yuwen,
SUM(case WHEN cid = 02 THEN score else null end) as shuxue,
SUM(case WHEN cid = 03 THEN score else null end) as yingyu
from Student as s ,SC
WHERE s.sid = SC.sid
group BY s.sid;

根据上面结果我们会发现其实后面部分的三个人是语文数学英语各自有一门课程没有成绩,那么如果使用上面的第一种方式或者是第二种方式其实都是需要费很大的力气才能完成的。
8.查询学过某个老师课程的学生的信息。
分析:首先上来就知道,要查询上过某个可得学生的的信息,首先要到SC表中找到有成绩的学生,获取到对应的课程id cid和学生id sid。那么问题来了,这个是多表查询呢?还是多表子查询呢?这个就需要分析一下,例如,我们需要找到上过张三老师上过课的学生,在SC中找到对应的cid 和sid,然后在学生表中找到对应的sid对应的学生。分析表结构之后发现其实在SC表中对应并不直接是Tid。所要先联合SC表,Teacher表以及Course表找到Sid。
select sid FROM SC,Course,Teacher
WHERE SC.cid = Course.cid
AND Course.tid = Teacher.tid
AND Teacher.tname='张三'
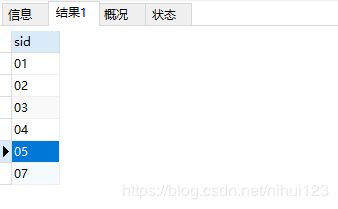
看到上张三课的学生其实挺多的。找到学生id之后就需要到学生表中去找到属于这些范围内的学生了。之前提到过,在SQL中使用范围表示有三种方式
- 使用不等号进行判断
- 使用between and
- 使用 in关键字
SELECT * from Student WHERE sid in(
select sid FROM SC,Course,Teacher
WHERE SC.cid = Course.cid
AND Course.tid = Teacher.tid
AND Teacher.tname='张三'
)
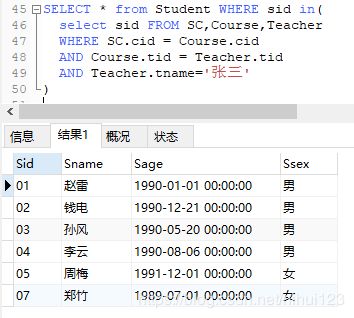
9. 查询选择所有课程的学生信息。
分析:首先分析选择所有课程的学生的sid是可以通过。SC表获取到的,那么怎么算做是选择所有课程的学生呢?之前的例子中遇到一个查询所有成绩的,可不可以借鉴那个例子呢?答案是不能,第一、需要知道选所有课程的学生有那些,其次要从学生中通过sid进行分组,那么问什么要分组呢,首先我们知道按照sid分组就可以知道那些学生是选择了三门课程,并进行了统计,到这里给出第一条语句。
select sid, count(sid) from SC GROUP BY sid
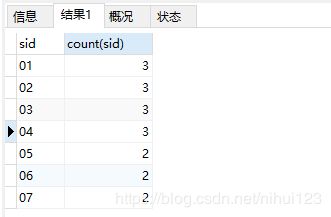
通过结果可以进一步的分析,如果将这个结果作为一个临时表进行进一步的查询应该怎么做呢?
select * from Student as s,
(select sid, count(sid) as cnt from SC GROUP BY sid) a
WHERE s.sid = a.sid AND a.cnt = 3;
上面语句显然是实现了功能的。那么还有没有更加优化的语句呢?这里介绍一个关键字having,为什么使用Having,Having与Where到底是什么区别。
查询没有选择所有课程的学生
select s.* from Student as s,
(select sid, count(sid) as cnt from SC GROUP BY sid) a
WHERE s.sid = a.sid AND a.cnt != 3;
Having 和Where
首先Where关键字是用来进行条件过滤的,用于选择符合条件的记录。但是在某种条件下其实可以使用where和Having得到同样的结果例如
select sid,count(1) from SC
GROUP BY sid
HAVING sid = 01;
select sid,count(1) from SC
where sid = 01;
GROUP BY sid
首先分析一下区别在什么地方
- Where子语句是用来指定“行”的条件,而Having子语句是指定组的条件。
- 使用Where子语句指定条件时,由于排序之前就对数据局进行了过滤,所以减少了排序的数据量,但是Having子句在排序之后才会对数据进行分组。
- 使用Where子语句速度更高是因为Where子语句指定的条件可以作为索引。
- where子句中不能使用聚合函数,而Having子句中可以使用。
总结
在之前面试的时候面试官问过为什么不使用Having语句,现在对于Having进行了一个深入的了解。展示了几个条件查询和子查询的组合。也提供了一个新的方式来统计各个列中为空的情况。