CRUSH算法介绍
CRUSH数据分布算法的全称是:Controlled, Scalable, Decentralized Placement of Replicated Data.
开源的分布式存储Ceph采用CRUSH数据分布算法以达到以下几个要求:
1. 数据分布均衡
2. 负载均衡
3. 灵活应对集群扩容和缩容:无论是添加或删除设备,都能最小化数据迁移
4. 支持大规模集群,消除因几种存储元数据而可能的单点失败
CRUSH算法除了要达到以上几个要求,它的主要目的是为了定位所存储数据的位置。
在Ceph存储中,数据都是以object为基本单位进行存储的,每个object默认为4MB大小;若干个object属于一个PG(Placement Group,归置组);而若干个PG又属于一个OSD;一般来说,一个OSD对应于一块磁盘。Ceph采用层级化的集群结构(Hierarchical Cluster Map),并且用户可自定义该集群结构,而OSD正是这个层级化集群结构的叶子节点。用户可定义整个集群分为3层,也可定义为5层,具体还可以定义每层的名字。举个栗子,一个Ceph集群,最顶层叫做root,root下面分为2个data center,每个data center有3个room,每个room有4个机架,每个机架上有5台机器,每台机器有6块硬盘(即6个OSD)。这些都是可自定义的,并且还可在线修改(见此篇)。整个层次结构中,除了叶子节点OSD之外,其他的都称之为bucket. 而上面提到的PG,不属于该层级结构。因为层级结构反映的是物理情况,相当于设定故障域,方便定位问题,而PG则是一个逻辑概念(在实际中,PG相当于磁盘上的一个目录,而属于这个PG的诸多object则是这个目录下的文件)。在一个Ceph集群上,可建立若干个Pool,每个Pool在创建的时候,就需要指明该Pool的PG数目。因此,Pool也是一个逻辑的概念。而PG,其实还相当于一致性Hash中的虚拟节点 -- PG的数目不会改变就如同虚拟节点的数目不会改变。而OSD相当于是一致性Hash中的物理节点。一旦一块磁盘损坏,其对应的OSD上的数据会迁移到其他的OSD上,这就相当于一致性Hash中的物理节点损坏后,其所管辖的虚拟节点被划分给了其他的物理节点。
那么,CRUSH算法如何定位存储数据的位置,并且满足以上四大要求呢?
Sage在2006年关于CRUSH的原论文写得非常言简意赅,并且主要是介绍抽象的CRUSH算法,而没有结合Ceph来谈,比如就完全没有提及PG和OSD的概念。因此,估计是要看看Sage的其他几篇论文和Ceph的源码才能清楚一点。现根据前人的几篇文献总结如下。
CRUSH算法主要用于在Ceph中定位存储数据的位置,分为2个步骤:
1. 根据数据对象(object)的对象名,计算得到PG_ID:
PG_ID = Pool_ID + Hash(2. 根据PG_ID,计算得到一组OSD
首先,为何是一组OSD?
因为在Ceph中,Pool分为2种。第一种是Replicated Pool,比如每个object都有N个副本,就是属于这种;第二种是EC Pool,运用的是纠删码技术,每个object只有一个副本,但有一些用于校验和还原的数据块。因此无论对于哪种Pool,一个object都需要多个OSD来保存其副本或者是保存其纠删码,因此输出是一组OSD.
那么,如何根据PG_ID,计算得到一组OSD呢?
首先,用户在建立Pool的时候,要设置存储规则(Placement Rule)。当然,如果不设定,那么就采用默认的规则。规则看起来是这样的:
Action Resulting
take(root) root
select(1, row) row-2
select(3, cabinet) cab-21, cab-23, cab-24
select(1, disk) disk-210, disk-233, disk-245
emit 效果如下图所示:
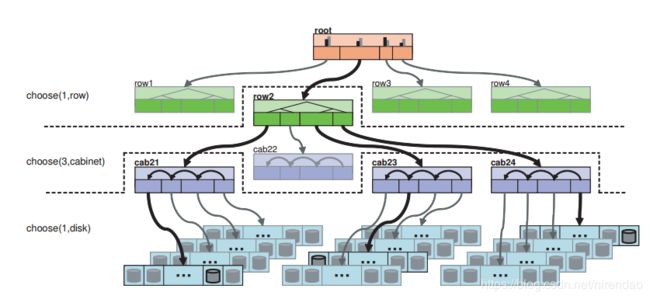
这三步(take、select(n,t), emit),是真正的原CRUSH论文中CRUSH算法的架构内容。而在涉及到select的时候,也需要介绍下是如何select的 -- 即bucket选择算法。详情如下。
第一步take(root), 代表的是选中了这个root.
注意,在一个Ceph集群中,是有可能有多个root的,因为层次结构是用户可自己设定的。比如,用户把所有SSD的设备设置成属于一个root,而把所有HDD的设备设置成属于另一个root.
第二步,select(n, t). 这一步是关键,意思是,选择n个类型为t的bucket.
那么,是如何选择的呢?
首先,select有2种操作方式:
- choose firstn: 深度优先选择出n个类型为t的子bucket,只到bucket为止
- chooseleaf: 先选择出n个类型为t的bucket,再在每个bucket下选择一个OSD设备
其次,就是如何去选择bucket了,即bucket随机选择算法。
一共有4种类型的bucket,对于每种类型的bucket,如何“选出”的方法是不一样的。而在设置Placement Rule时,可以指定采用哪种bucket随机选择算法,即属于哪种bucket.
这里首先介绍一个重要的Hash函数,因为该函数在多个bucket选择算法中都用到了,但作用各不相同:
hash(PG_ID, r, bucket_id) 这个Hash函数的输入有3个:PG_ID,r为 [1-n] 中的一个值(n为副本数),bucket_id
这个Hash函数的输出是一个 [0-1] 之间的数值
1. Uniform Bucket
每个bucket的权重都相同(这里应该指的是同层级的节点的weight都相同),并且基本没有硬件设备添加和删除的情况
这种Bucket因为所有item权重都相同,因此选择速度很快,为O(1),但是一旦需要添加或删除设备,就退化成普通Hash,即几乎所有数据都需要迁移。在实际中,一般不会使用这种bucket.
2. List Bucket
其子item在内存中使用数据结构中的链表来保存,其所包含的item可以具有任意权重。(注:此处item和bucket是一个意思) 具体查找bucket的方法是:
1> 从表头item开始查找,先得到表头item的权重Wh,剩余链表中所有item权重之和为Ws.
2> 根据 hash(PG_ID, r, bucket_id) 计算得到一个 [0-1] 之间的值v,若v在 [0-Wh/Ws) 的范围,则选择表头item,并返回表头item的id;
3> 否则,继续遍历剩余的链表,继续上述的递归查找。
由以上分析可知,List Bucket的查找复杂度为 O(n)
这种Bucket在实际中一般也不太会用,因为其删除硬件时,效率也较差。
3. Tree Bucket
此种类型的Bucket的子item组织成树的结构。每个OSD是叶子节点;根节点和中间节点是虚拟节点,其权重等于左右子树的权重之和。具体查找bucket的方法如下:
1> 从根节点开始遍历
2> 设左子树权重为W1,而当前节点权重为Wn,然后根据 hash(PG_ID, r, bucket_id) 计算得到一个 [0-1] 之间的值v;
a> 若v在 [0-W1/Wn) 之间,那么在左子树中继续选择item;
b> 否则在右子树中选择item
c> 一直遍历,直至叶子节点
由以上分析可知,Tree Bucket的查找复杂度为 O(log n)
这种Bucket在实际中可以考虑使用。其选择速度是很快的,而在添加和删除硬件设备时,速度也还可以。
4. Straw Bucket
此种类型的bucket选择算法是Ceph的默认选择算法。具体如下:
1> 函数 f(Wi) 是和item的权重Wi相关的函数,决定了每个item被选中的概率;权重(weight)越高的item则被选中的概率越大。
注意,这里的weight并不是相当于磁盘可用空间,而是相当于总空间,因此是固定不变的。
2> 给每个item计算一个长度
length = f(Wi) * hash(PG_ID, r, bucket_id) 然后选择length最大的item.
因为straw在增删设备时的表现最佳,而在选择速度上也还可以,因此,它被选作默认的bucket选择算法。
以上各个bucket选择算法的对比情况见下表:
| Bucket选择算法 | 选择的速度 | item添加的容易程度 | item删除的容易程度 |
| uniform | O(1) | poor | poor |
| list | O(n) | optimal | poor |
| tree | O(log n) | good | good |
| straw | O(n) | better | better |
| straw2 | O(n) | optimal | optimal |
当选出一个OSD后,可能出现冲突(重复选择)、失效(磁盘损坏)、过载的情况,那么此时就重新选择一次。对于Replicated Pool和EC Pool,重新选择的算法是略有不同的。Replicated Pool是直接再选一个即可(r' = r + f,f为总失败的次数),而EC Pool则需令r值增加n的倍数后(r' = fr*n, fr为在这个副本上失败的次数),再运用hash(PG_ID, r', bucket_id)来进行重新选择。
下图显示了两种Pool在失败的情况下是如何决定r'的值:

最后一步,第三步,emit,即输出结果。所谓结果,即一组OSD.
参考文献:
1. 《Ceph源码分析》第四章 CRUSH数据分布算法
2. CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data
3. 大话Ceph - CRUSH那点事儿
4. Ceph剖析:数据分布之CRUSH算法与一致性Hash