深度学习(DL)与卷积神经网络(CNN)学习笔记随笔-02-基于Python的卷积运算
原文地址可以查看更多信息:http://blog.csdn.net/niuwei22007/article/details/48025939
源代码分析:(注意,如果直接保存以下代码,一定要另存为UTF8格式,否则报错)个人理解,欢迎批评指正。
代码中会用到一个名叫dimshuffle()的函数。dimshuffle()是一个很强大的工具,但是对于初学者来说可能会搞不懂到底有什么用,一开始我也是。但是经过多次实验,终于弄懂了dimshuffle()的作用是什么,参见dimshuffle的作用详解
import theano
import numpy
import pylab
from theano import tensor as T
from theano.tensor.nnet import conv
from PIL import Image
# 生成一个随机数生成类rng,其seed为23455(随机数种子)。
rng = numpy.random.RandomState(23455)
# 实例化一个4D的输入tensor,是一个象征性的输入,相当于形参,需要调用时传入一个实参
input = T.tensor4(name='input')
# 权值数组的shape(可以理解为权值的数组大小),用来确定需要产生的随机数个数,
#(该大小可以理解为是一个 2行3列 的矩阵,其中每个矩阵元素又是一个 9行9列的 矩阵)
w_shp = (2, 3, 9, 9)
# 每个权值的边界,用来确定需要产生的每个随机数的范围。
w_bound = numpy.sqrt(3 * 9 * 9)
# rng.uniform(low,hign,size)的作用是产生一个shape为size的均匀分布数组,每个数的范围为(low,high)
# numpy.asarray(a)的作用是将 类数组a 转化为array类型
# theano.shared()实例化一个权值变量(只是为了进行GPU加速时用),可以调用W.get_value()查看其value
W = theano.shared( numpy.asarray(
rng.uniform(
low=-1.0 / w_bound,
high=1.0 / w_bound,
size=w_shp),
dtype=input.dtype), name ='W')
# 下面是用同样的方法初始化一个偏置值b,b通常被初始化为0,因为它在算法中会有一个被学习的过程;
# 但是此处是需要直接用它来计算,所以用随机值给它初始化,就当做是已经经过学习后的值了。
b_shp = (2,)
b = theano.shared(numpy.asarray(
rng.uniform(low=-.5, high=.5, size=b_shp),
dtype=input.dtype), name ='b')
# conv.conv2d(input,filter) 需要2个输入,一个是input,一个是filter。
# input就是上文中的4D张量,每个张量分别代表[mini-batch size,特征图的数量,图像高度,图像宽度]。
# filter就是上文中的W。也是一个4D张量,分别代表[m层特征图数量,m-1层特征图数量,过滤器高度,过滤器宽度]。
#
# 当其他函数需要用到变量conv_out时,会先把实参input传入conv2d()中,再计算出conv_out
#
conv_out = conv.conv2d(input, W)
# dimshuffle是一个很强大的能轻松改变一个张量结构的工具。b.dimshuffle('x', 0, 'x', 'x')
# 就是把b的原始的第0列向量的左侧添加一个维度,在其右侧添加两个维度。
# b原来是个一维数据(2),经过dimshuffle之后,则变成了一个四维数据(1*2*1*1)。
# dimshuffle具体的操作,参见文章一开始。
output = T.nnet.sigmoid(conv_out + b.dimshuffle('x', 0, 'x', 'x'))
# 创建一个用来过滤图像的theano.function(可以把f编译为c,然后就可以随时拿来用了。)
#
# 当其他函数需要调用f时(调用形式为f(input)),需要传入实参input,然后将计算结果存入output中。
#
f = theano.function([input], output)
# 下面开始处理几幅图片来看一下效果
# 打开一幅图片,源代码中有2个"open",应该是在linux中的语法,我是在windows上运行的,所以改成1个open
img = Image.open('g:\\b.jpg')
# 得到图片的宽度和高度(注意,顺序一定不要弄反)
img_w, img_h = img.size
# 将图片像素按照(高度,宽度,通道数量)格式化为array数组
# 其实就是将图片数据格式化为一个数组,因为每个像素点包括3个字节,B,G,R,且其范围为0-255,
# 这个地方最后将其除以256是为了归一化,归一化后的数据是float64类型
img = numpy.asarray(img, dtype='float32') / 256.
# 图片的原始数据是一个3D数据【高,宽,通道数量】,
# 经过数据置换(transpose(2,0,1))之后,变成了【通道数量,高,宽】,
# 因为f中传入参数需要4D,因此需要将图片数据reshape成为一个【1, 通道数量, 高, 宽】这样的4D张量,
# reshape的参数一定要注意,1就是最外的那一维度,3就是通道数量,然后是【高】和【宽】,
# 这样结果的 img_.shape =【1, 3, 宽, 高】
#
# 为什么reshape为这样的size呢?因为调用f时需要传入一个input,而这个input就是4D,最终的这个input是传入到
# conv2d中的第一个参数,而那个参数的格式是什么呢?[mini-batch size,特征图的数量,图像高度,图像宽度]
# 这样就串起来了吧,第一个参数是batch size,是每次训练的样本数量,此处为1的话,就是最普通的每次训练一个样本。
# 第二个参数代表输入层的特征图数量,这个地方是3,其实就是把一张彩色图片按照3个通道作为3个特征图进行输入;
# 最后两个是图像的高度和宽度,正好一一对应。
#
img_ = img.transpose(2, 0, 1).reshape(1, 3, img_h, img_w)
# 将img_作为f的参数,经过计算得到输出
filtered_img = f(img_)
# 将原始图片显示出来
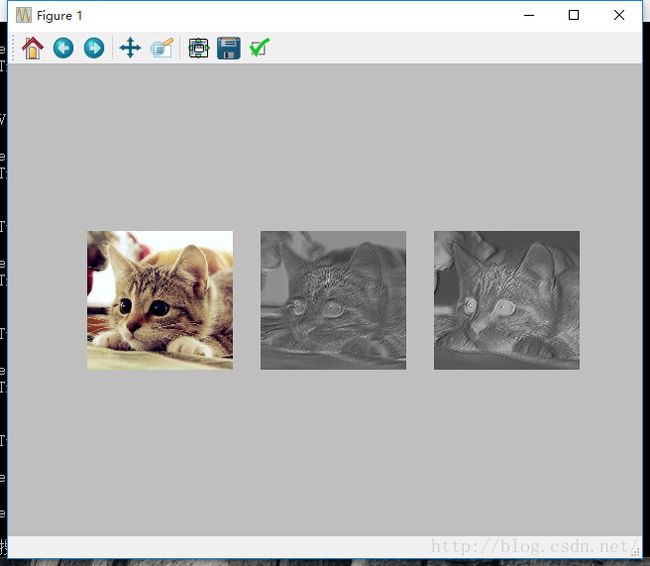
pylab.subplot(1, 3, 1); pylab.axis('off'); pylab.imshow(img)
# 图片灰度化
pylab.gray();
# 分别显示不同处理后的图片
pylab.subplot(1, 3, 2); pylab.axis('off'); pylab.imshow(filtered_img[0, 0, :, :])
pylab.subplot(1, 3, 3); pylab.axis('off'); pylab.imshow(filtered_img[0, 1, :, :])
pylab.show()运行结果:
参考资料:
1.原始教程
2.小白安装Theano