Alex 的 Hadoop 菜鸟教程: 第19课 华丽的控制台 HUE 安装以及使用教程
原文地址: http://blog.csdn.net/nsrainbow/article/details/43677077 最新课程请关注原作者博客,获得更好的显示体验
声明
- 本文基于Centos 6.x + CDH 5.x
HUE
Hadoop也有web管理控制台,而且还很华丽,它的名字叫HUE。通过HUE可以管理Hadoop常见的组件。下面用一幅图说明HUE能管理哪些组件
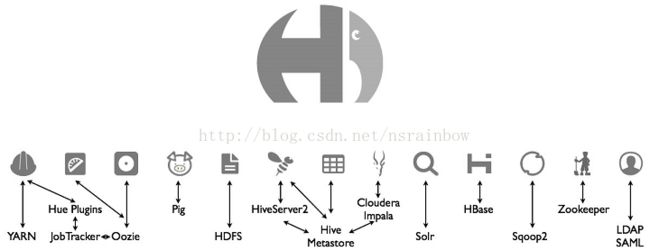
除了Oozie,LDAP SAML和Solr以外,前面的课程都说过了,Oozie是一个工作流组件,在下一课讲解,LDAP是一个用户密码的管理中心,负责用户的登陆。Solr是一个全文检索的引擎,不过其实Solr也不算Hadoop系专有的,Solr在很早以前就出现了,要算的话应该算Lucene系。
如果是根据课程来的同学,大家的机器上应该已经装了这些组件
- YARN
- Pig
- Hive
- Impala
- HBase
- Sqoop1(我们装的是Sqoop1这边管理的是Sqoop2)
- Zookeeper
安装HUE
可以在随便一台机器上安装HUE,官方建议在master机器上安装,我现在就俩虚拟机host1和host2,master是host1,但是我觉得host1的负担太重了,所以我决定吧HUE装host2上
在host2上执行
$ sudo yum install hue配置HUE
配置Hadoop和HttpFs
HUE使用两种方式 WebHDFS 和 HttpFS 来访问HDFS,由于我们采用的是HA方式,所以只能用HttpFS。没有装过的同学可以看这个教程 Alex 的 Hadoop 菜鸟教程: 第18课 用Http的方式访问HDFS - HttpFs 教程
接下来我们要打开hue用户对hdfs的访问权限
编辑 /etc/hadoop-httpfs/conf/httpfs-site.xml
httpfs.proxyuser.hue.hosts
*
httpfs.proxyuser.hue.groups
*
[hadoop]
# Configuration for HDFS NameNode
# ------------------------------------------------------------------------
[[hdfs_clusters]]
# HA support by using HttpFs
[[[default]]]
# Enter the filesystem uri
fs_defaultfs=hdfs://mycluster
# NameNode logical name.
## logical_name=
# Use WebHdfs/HttpFs as the communication mechanism.
# Domain should be the NameNode or HttpFs host.
# Default port is 14000 for HttpFs.
webhdfs_url=http://host2:14000/webhdfs/v1fs_defaultfs 的值配置成你在 /etc/hadoop/conf/core-site.xml 里面配置的 fs.defaultFS 属性值
配置YARN
继续编辑hue.ini ,找到 [[yarn_clusters]] 编辑一下
[[yarn_clusters]]
[[[default]]]
# Enter the host on which you are running the ResourceManager
resourcemanager_host=host1
# The port where the ResourceManager IPC listens on
## resourcemanager_port=8032
# Whether to submit jobs to this cluster
submit_to=True
# Resource Manager logical name (required for HA)
## logical_name=
# Change this if your YARN cluster is Kerberos-secured
## security_enabled=false
# URL of the ResourceManager API
resourcemanager_api_url=http://host1:8088
# URL of the ProxyServer API
proxy_api_url=http://host1:8088
# URL of the HistoryServer API
history_server_api_url=http://host1:19888因为我的 resoucemanager , history-server 都装在host1上,所以我修改了resourcemanager_host, resourcemanager_api_url, proxy_api_url, history_server_api_url 这些属性
配置Zookeeper
找到 [zookeeper] 节点
[zookeeper]
[[clusters]]
[[[default]]]
# Zookeeper ensemble. Comma separated list of Host/Port.
# e.g. localhost:2181,localhost:2182,localhost:2183
host_ports=host1:2181,host2:2181配置上 host_ports
配置Hbase
HUE跟Hbase通讯是通过 hbase-thrift , Alex 的 Hadoop 菜鸟教程: 第6课 Hbase 安装教程 中已经安装过hbase-thrift,当时是安装在 host1 上,所以我们先在 host1 上启动 hbase-thrift 服务
service hbase-thrift start
继续编辑 /etc/hue/conf/hue.ini 找到 [hbase] 段落,去掉 hbase_clusters 的注释,并修改 hbase_clusters 的地址
[hbase]
# Comma-separated list of HBase Thrift servers for clusters in the format of '(name|host:port)'.
# Use full hostname with security.
hbase_clusters=(Cluster|host1:9090)
# HBase configuration directory, where hbase-site.xml is located.
## hbase_conf_dir=/etc/hbase/conf
# Hard limit of rows or columns per row fetched before truncating.
## truncate_limit = 500
# 'buffered' is the default of the HBase Thrift Server and supports security.
# 'framed' can be used to chunk up responses,
# which is useful when used in conjunction with the nonblocking server in Thrift.
## thrift_transport=buffered- 这边的 (Cluster|host1:9090) 里面的 Cluster并不是你的HDFS集群名字,只是一个显示在HUE界面上的文字,所以可以随便写,我这边保留 Cluster字样,后面的host1:9090是thrift的访问地址,如果有多个用逗号分隔
配置Hive
编辑 hue.ini ,找到 [beeswax] 段落,为什么叫[beeswax]而不是[hive]这是历史原因
[beeswax]
# Host where HiveServer2 is running.
# If Kerberos security is enabled, use fully-qualified domain name (FQDN).
hive_server_host=host1
# Port where HiveServer2 Thrift server runs on.
## hive_server_port=10000
# Hive configuration directory, where hive-site.xml is located
## hive_conf_dir=/etc/hive/conf- 把 hive_server_host的注释去掉,并写上hive-server2 所在服务器名字
- 如果你改了hive的默认端口,就修改hive_server_port
- 如果你这台机器有装hive,就配置上hive_conf_dir
配置Impala
编辑 hue.ini 找到 [impala] 段落
[impala]
# Host of the Impala Server (one of the Impalad)
server_host=host2
其实这边的 server_host 可以写任意一台impalad所在的服务器,我在所有的datanode上都装了impalad ( Alex 的 Hadoop 菜鸟教程: 第15课 Impala 安装使用教程),所以我这里写host2或者host1都无所谓
配置Pig
由于我在 Alex 的 Hadoop 菜鸟教程: 第16课 Pig 安装使用教程 只在 host1 上安装了pig,所以我先在host2上补装上pig
配置Spark
要在HUE中使用Spark还需要安装spark-jobserver,但是这个东西没在CDH中,所以我们必须手动安装spark-jobserver
先要安装SBT。SBT = (not so) Simple Build Tool,是scala的构建工具,与java的maven地位相同
curl https://bintray.com/sbt/rpm/rpm > bintray-sbt-rpm.repo
sudo mv bintray-sbt-rpm.repo /etc/yum.repos.d/
sudo yum install sbt安装好SBT后,安装spark-jobserver
git clone https://github.com/ooyala/spark-jobserver.git
cd spark-jobserver
sbt
re-start
修改master属性
master = "spark://xmseapp03:7077"
找到 [spark] 段落,修改 server_url 为正确的地址
[spark]
# URL of the REST Spark Job Server.
server_url=http://host1:8090/配置secret_key
设置一个secret_key的目的是加密你的cookie让你的hue更安全。找到 secret_key 这个项,然后随便设置一串字符串(官方建议30-60个字符长度)这里举个例子
secret_key=qpbdxoewsqlkhztybvfidtvwekftusgdlofbcfghaswuicmqp启动HUE
配置完毕后确保你的 HttpFs 服务启动了。然后启动HUE
service hue starthue的运行日志在 /var/log/hue/runcpserver.log
使用HUE
启动后,访问 http://host2:8888 可以看到
第一个访问这个地址的人就会成为超级用户,输入用户名和密码后会进入快速启动
快速启动
步骤1 检查配置
检查完会给你报错,然后你根据这些错误去修正配置
当然也不是每个项都一定要修改好才可以用,比如Oozie我们就没装,就放着就好了,等以后装了Oozie再回来配置
步骤2 示例
下一步,安装示例,继续点击下一页
步骤3 用户
直接点击下一页
步骤4 执行
点击 "HUE主页" 就会跳到 HUE的控制台了
在HUE中管理HDFS
点击右上角的 File Browser
进入了HDFS管理界面
这个界面下,你可以
- 上传文件
- 建立文件夹
- 删除文件
等操作
在HUE中查询Hbase
我们用HUE最重要的就是可以用它来直接跟各个hadoop组价交互,作为各个组件的UI使用。
选择最上面工具栏的 Data Browser 下拉菜单,选择Hbase
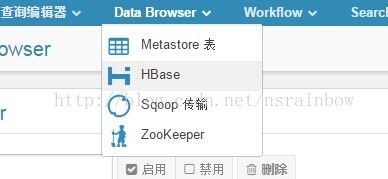
可以看到Hbase中表的列表
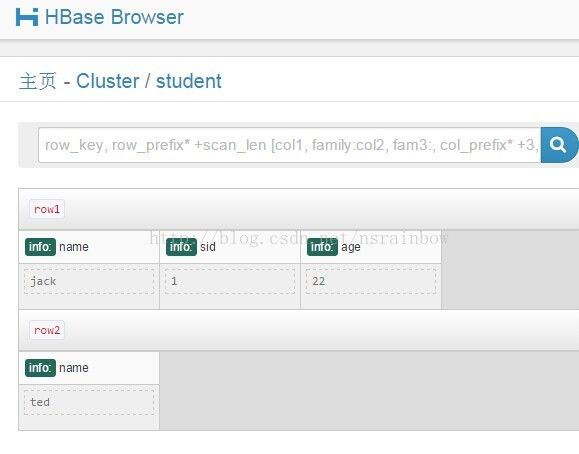
点击其中一个表可以看到数据
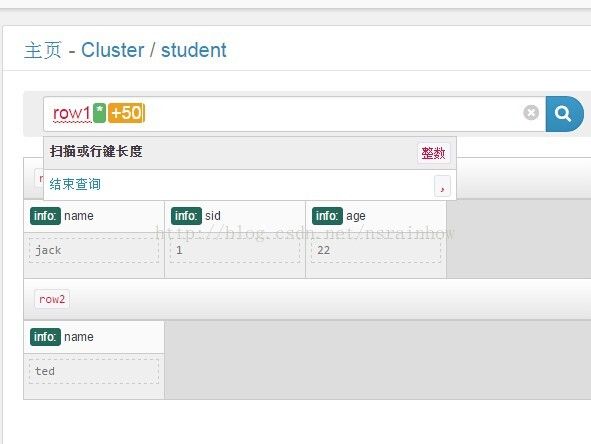
HUE支持一个Hbase的查询语法,比如像下面这幅图我是查所有以row1打头的rowkey,并往下看50条
在HUE中查询Hive
选择Hive
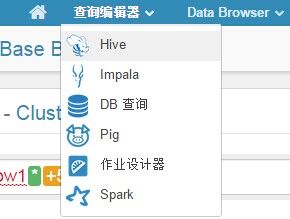
输入SQL后点击“执行”
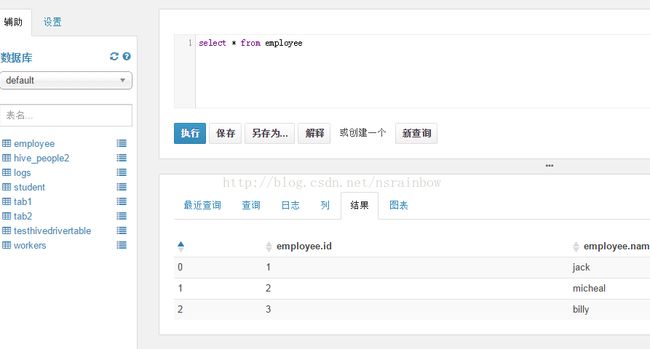
是不是很方便?
在HUE中使用Spark

HUE还有其他功能,比如 可以直接建立Metatable ,查询Impala等,就自己探索把,这些功能都很简单明了。