Caffe2 - (十一)ResNet50 Multi-GPU 训练
Caffe2 - Multi-GPU 训练
1. 概要
- ResNet50 model
- ImageNet 数据集 - 14 million 张图片, 大概需要 300GB SSD 存储空间,2000 个磁盘分片;两张 GPUs 耗时一周.
这里以 ImageNet 中的一部分为例:
- 640 种 cars 和 640 种 boats 图片集作为训练数据集;
- 48 种 cars 和 48 种 boats 图片集作为训练数据集;
- 数据集图片大概 130 MB.
ResNet50 模型训练主要包括:
- 采用
brew创建训练网络和测试网络; - 采用
model helper的CreateDB来创建图片数据集读取器(database reader); - 创建训练函数来基于一张或多张 GPU 进行 ResNet50 模型训练;
- 创建并行化(parallelized)模型;
- 循环训练多个 epoches,每个 epoch 中,包括:
- 对其每个 batch 图片进行模型训练;
- 运行测试模型;
- 计算时间,精度,并显示结果.
2. 数据集准备与训练配置
2.1 数据集准备
网络训练前,需要准备训练和测试图片数据集.
下载 Caffe2 提供的 boats 和 cars 的数据集 resnet_trainer,其选取自 ImageNet,并被转化为 lmdb 格式:
https://download.caffe2.ai/databases/resnet_trainer.zip数据加载与python模块导入:
import numpy as np import time import os from caffe2.python import core, workspace, model_helper, net_drawer, memonger, brew from caffe2.python import data_parallel_model as dpm from caffe2.python.models import resnet from caffe2.proto import caffe2_pb2 workspace.GlobalInit(['caffe2', '--caffe2_log_level=2']) # 训练数据集和测试数据集加载 data_folder = '/path/to/resnet_trainer' train_data_db = os.path.join(data_folder, "imagenet_cars_boats_train") train_data_db_type = "lmdb" # 640 cars and 640 boats = 1280 train_data_count = 1280 test_data_db = os.path.join(data_folder, "imagenet_cars_boats_val") test_data_db_type = "lmdb" # 48 cars and 48 boats = 96 test_data_count = 96 assert os.path.exists(train_data_db) assert os.path.exists(test_data_db)
2.2 训练配置
主要是 gpus,batch_size,num_labels,base_learning_rate,stepsize 及 weight_decay 等设置.
# 训练模型用到的 GPUs 数量
# 如, gpus = [0, 1, 2, n]
gpus = [0]
# Batch size of 32 sums up to roughly 5GB of memory per device
# 每张 GPU 的图片 Batch size 数,每张 GPU 大概需要 5GB 显存
batch_per_device = 32
# 总 Batch size
total_batch_size = batch_per_device * len(gpus)
# 两种 labels: car 和 boat
num_labels = 2
# 初始学习率,缩放因子 - total_batch_size
base_learning_rate = 0.0004 * total_batch_size
# 每 10 个 epochs 改变一次学习率
stepsize = int(10 * train_data_count / total_batch_size)
# Weight decay (L2 regularization)
weight_decay = 1e-43. 模型创建与训练
3.1 创建 CNN 网络
采用 Caffe2 Operators - ModelHelper 创建CNN网络:
# model helpe object 仅需要一个参数,即网络名,可以任意命名,主要是对 workspace 网络的引用
# 如:
catos_model = model_helper.ModelHelper(name="catos")
# 创建网络前,清空 workspace
workspace.ResetWorkspace()3.2 从 DB 读取数据
reader = catos_model.CreateDB(name, db, db_type)3.3 图片变换
- Caffe2 编译时需要有 opencv
在实际场景中,图片可能有不同的尺寸(size),长宽比(aspect ratios) 以及旋转角度(orientations),因此训练时需要尽可能的使图片包含更多的情况.
ImageNet 的平均分辨率是 496×387 496 × 387 .
为了便于训练,需要将图片转化为标准尺寸;最直接的做法是简单 resize 到 256×256 256 × 256 ,可参考 Caffe2 - 图像加载与预处理,有对其缺点的介绍.
因此,为了更精确的结果,需要对图片进行合理的 rescale,crop等处理. 虽然也会存在一定的原始图片信息的丢失.
可以围绕图片进行随机裁剪,以得到原始图片的更多变形,扩增训练数据集,增强模型鲁棒性.
如果一张图片中只存在 car 或 boat 的一半,模型最好仍能检测到. 如:
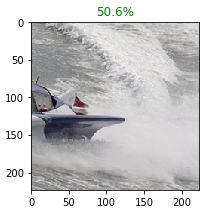
图片中仅有 boat 的一半,模型仍得到 50% 的置信度.
Caffe2 提供了 C++ 的图像变换 operator - ImageInput operator,其 Caffe2 的 Python API 使用:
def add_image_input_ops(model):
# 使用 ImageInput operator 来处理图片
data, label = model.ImageInput(reader,
["data", "label"],
batch_size=batch_per_device,
mean=128., # mean: 去除常见 color 均值
std=128., # std: 随机添加对减均值的影响
scale=256, # scale: 将图片 rescale 到通用 size
crop=224, # crop: 裁剪方形图片,提取图片维度信息
is_test=False, # 测试时,不进行图像变换
mirror=1 # 随机进行图片镜像
)
# 不进行 BP 梯度数值计算
data = model.StopGradient(data, data)3.4 创建 Residual 网络
Caffe2 提供了 resnet 的创建函数:from caffe2.python.models import resnet
ResNet50 模型创建:resnet.create_resnet50()函数
create_resnet50(
model,
data,
num_input_channels,
num_labels,
label=None,
is_test=False,
no_loss=False,
no_bias=0,
conv1_kernel=7,
conv1_stride=2,
final_avg_kernel=7
)create_resnet50_model_ops对该函数的调用:
def create_resnet50_model_ops(model, loss_scale):
# 创建 Residual 网络
[softmax, loss] = resnet.create_resnet50(model,
"data",
num_input_channels=3,
num_labels=num_labels,
label="label", )
prefix = model.net.Proto().name
loss = model.Scale(loss, prefix + "_loss", scale=loss_scale)
model.Accuracy([softmax, "label"], prefix + "_accuracy")
return [loss]3.5 网络初始化
Caffe2 model helper 对象提供了内在函数,用于采用 BP 算法进行网络学习:
- AddWeightDecay
- Iter
- net.LearningRate
def add_parameter_update_ops(model):
model.AddWeightDecay(weight_decay)
iter = model.Iter("iter")
lr = model.net.LearningRate([iter],
"lr",
base_lr=base_learning_rate,
policy="step",
stepsize=stepsize,
gamma=0.1, )
# Momentum SGD update
for param in model.GetParams():
param_grad = model.param_to_grad[param]
param_momentum = model.param_init_net.ConstantFill([param],
param + '_momentum', value=0.0)
# 更新 param_grad and param_momentum in place
model.net.MomentumSGDUpdate([param_grad, param_momentum, lr, param],
[param_grad, param_momentum, param],
momentum=0.9,
# Nesterov Momentum works slightly better than standard
nesterov=1, )3.6 梯度优化
如果不采用内存优化,可以减少 batch size,但这里进行了内存优化.
Caffe2 提供了 memonger函数来进行内存优化,重用计算的梯度.
def optimize_gradient_memory(model, loss):
model.net._net = memonger.share_grad_blobs(model.net,
loss,
set(model.param_to_grad.values()),
# memonger 需要有 namescape 参数,这里进行创建,后面会用到
namescope="imonaboat",
share_activations=False)3.7 单 GPU 网络训练
workspace.ResetWorkspace()
train_model = model_helper.ModelHelper(name="train",)
reader = train_model.CreateDB("train_reader",
db=train_data_db,
db_type=train_data_db_type, )
#
def add_image_input_ops(model):
# input
data, label = brew.image_input(model,
reader,
["data", "label"],
batch_size=batch_per_device,
mean=128.,
std=128.,
scale=256,
crop=224,
is_test=False,
mirror=1)
data = model.net.StopGradient(data, data)
#
def create_resnet50_model_ops(model, loss_scale=1.0):
# residual network
[softmax, loss] = resnet.create_resnet50(model,
"data",
num_input_channels=3,
num_labels=num_labels,
label="label", )
prefix = model.net.Proto().name
loss = model.net.Scale(loss, prefix + "_loss", scale=loss_scale)
brew.accuracy(model, [softmax, "label"], prefix + "_accuracy")
return [loss]
#
def add_parameter_update_ops(model):
brew.add_weight_decay(model, weight_decay)
iter = brew.iter(model, "iter")
lr = model.net.LearningRate([iter],
"lr",
base_lr=base_learning_rate,
policy="step",
stepsize=stepsize,
gamma=0.1, )
for param in model.GetParams():
param_grad = model.param_to_grad[param]
param_momentum = model.param_init_net.ConstantFill(
[param], param + '_momentum', value=0.0 )
model.net.MomentumSGDUpdate(
[param_grad, param_momentum, lr, param],
[param_grad, param_momentum, param],
momentum=0.9,
nesterov=1, )
#
def optimize_gradient_memory(model, loss):
model.net._net = memonger.share_grad_blobs(
model.net,
loss,
set(model.param_to_grad.values()),
namescope="imonaboat",
share_activations=False, )
#
# 设置 GPU 模式,GPUID
device_opt = core.DeviceOption(caffe2_pb2.CUDA, gpus[0])
# 梯度优化中创建的 namespace - imonaboat
with core.NameScope("imonaboat"):
# 选择使用一个 GPU
with core.DeviceScope(device_opt):
# 读取训练数据,并创建数据变换层
add_image_input_ops(train_model)
# 生成 residual 网络,返回 losses 值
losses = create_resnet50_model_ops(train_model)
# 创建每个 loss 的梯度
blobs_to_gradients = train_model.AddGradientOperators(losses)
# 开始网络权重的学习
add_parameter_update_ops(train_model)
# 梯度优化
optimize_gradient_memory(train_model, [blobs_to_gradients[losses[0]]])
# 启动网络
workspace.RunNetOnce(train_model.param_init_net)
# 加载初始化网络权重
workspace.CreateNet(train_model.net, overwrite=True)
# 训练一个 epoch
num_epochs = 1
for epoch in range(num_epochs):
# 设置训练迭代次数:total images / batch size
num_iters = int(train_data_count / total_batch_size)
for iter in range(num_iters):
t1 = time.time()
# 进行迭代
workspace.RunNet(train_model.net.Proto().name)
t2 = time.time()
dt = t2 - t1
print((
"Finished iteration {:>" + str(len(str(num_iters))) + "}/{}" +
" (epoch {:>" + str(len(str(num_epochs))) + "}/{})" +
" ({:.2f} images/sec)").
format(iter+1, num_iters, epoch+1, num_epochs, total_batch_size/dt))WARNING:memonger:NOTE: Executing memonger to optimize gradient memory
INFO:memonger:Memonger memory optimization took 0.0121657848358 secs
Finished iteration 1/40 (epoch 1/1) (24.75 images/sec)
Finished iteration 2/40 (epoch 1/1) (102.15 images/sec)
Finished iteration 3/40 (epoch 1/1) (103.12 images/sec)
……
3.8 多 GPU 并行化
Caffe2 的 data_parallel_model及函数 Parallelize_GPU 来实现多 GPU 并行化.
Parallelize_GPU - caffe2.python.data_parallel_model:
Parallelize_GPU(model_helper_obj,
input_builder_fun,
forward_pass_builder_fun,
param_update_builder_fun,
devices=range(0, workspace.NumCudaDevices()),
rendezvous=None,
net_type='dag',
broadcast_computed_params=True,
optimize_gradient_memory=False)
input_builder_fun - 添加 input operators. 在该函数外,需要先将数据读取 reader 实例化,以使全部的 GPUs 能够共享 reader 对象. 用法: input_builder_fun(model)
forward_pass_builder_fun - 添加 operators 到模型. 必须返回 loss-blob 列表,用于构建梯度. 传递 loss scale 参数,模型 loss scale 是 (1.0 / gpus 数). 用法:forward_pass_builder_fun(model, loss_scale)
- param_update_builder_fun - 在更新梯度后,添加 operators,如更新权重(weights)和 weight decaying。 用法: param_update_builder_fun(model)
前面已经 from caffe2.python import data_parallel_model as dpm,即可直接调用 dpm.Parallelize_GPU()来使用 Parallize_GPU函数.
dpm.Parallelize_GPU(train_model,
input_builder_fun=add_image_input_ops,
forward_pass_builder_fun=create_resnet50_model_ops,
param_update_builder_fun=add_parameter_update_ops,
devices=gpus,
optimize_gradient_memory=True,)实现:
gpus = [0, 1] # 假设有两张 GPUs.
batch_per_device = 32
total_batch_size = batch_per_device * len(gpus)
num_labels = 2
base_learning_rate = 0.0004 * total_batch_size
stepsize = int(10 * train_data_count / total_batch_size)
weight_decay = 1e-4
workspace.ResetWorkspace()
train_model = model_helper.ModelHelper(name="train",)
reader = train_model.CreateDB("train_reader",
db=train_data_db,
db_type=train_data_db_type, )
dpm.Parallelize_GPU(train_model,
input_builder_fun=add_image_input_ops,
forward_pass_builder_fun=create_resnet50_model_ops,
param_update_builder_fun=add_parameter_update_ops,
devices=gpus,
optimize_gradient_memory=True, )
workspace.RunNetOnce(train_model.param_init_net)
workspace.CreateNet(train_model.net)3.9 创建测试模型
类似于训练网络的创建:
ModelHelper- 创建 model helper object,命名为 “test”;CreateDB- 创建数据读取 reader,命名为 “test_reader”;Parallelize_GPU- 并行化模型,设置param_update_builder_fun=None,以跳过 BP;workspace.RunNetOnce和workspace.CreateNet- 启动测试网络
test_model = model_helper.ModelHelper(name="test",)
reader = test_model.CreateDB("test_reader",
db=test_data_db,
db_type=test_data_db_type,)
# Validation is parallelized across devices as well
dpm.Parallelize_GPU(test_model,
input_builder_fun=add_image_input_ops,
forward_pass_builder_fun=create_resnet50_model_ops,
param_update_builder_fun=None,
devices=gpus,)
workspace.RunNetOnce(test_model.param_init_net)
workspace.CreateNet(test_model.net)3.10 显示过程信息
在每个 epoch 结束后,对网络表现进行检查,记录训练模型和测试模型的精度.
from caffe2.python import visualize
from matplotlib import pyplot as plt
def display_images_and_confidence():
images = []
confidences = []
n = 16
data = workspace.FetchBlob("gpu_0/data")
label = workspace.FetchBlob("gpu_0/label")
softmax = workspace.FetchBlob("gpu_0/softmax")
for arr in zip(data[0:n], label[0:n], softmax[0:n]):
# CHW to HWC, normalize to [0.0, 1.0], and BGR to RGB
bgr = (arr[0].swapaxes(0, 1).swapaxes(1, 2) + 1.0) / 2.0
rgb = bgr[...,::-1]
images.append(rgb)
confidences.append(arr[2][arr[1]])
# Create grid for images
fig, rows = plt.subplots(nrows=4, ncols=4, figsize=(12, 12))
plt.tight_layout(h_pad=2)
# Display images and the models confidence in their label
items = zip([ax for cols in rows for ax in cols], images, confidences)
for (ax, image, confidence) in items:
ax.imshow(image)
if confidence >= 0.5:
ax.set_title("RIGHT ({:.1f}%)".format(confidence * 100.0), color='green')
else:
ax.set_title("WRONG ({:.1f}%)".format(confidence * 100.0), color='red')
plt.show()
def accuracy(model):
accuracy = []
prefix = model.net.Proto().name
for device in model._devices:
accuracy.append(
np.asscalar(workspace.FetchBlob("gpu_{}/{}_accuracy".format(device, prefix))))
return np.average(accuracy)3.11 Multi-GPU 训练及测试
# 训练的 epoch
num_epochs = 2
for epoch in range(num_epochs):
# 每个 epoch 迭代次数
num_iters = int(train_data_count / total_batch_size)
for iter in range(num_iters):
t1 = time.time()
# 进行一次迭代
workspace.RunNet(train_model.net.Proto().name)
t2 = time.time()
dt = t2 - t1
print((
"Finished iteration {:>" + str(len(str(num_iters))) + "}/{}" +
" (epoch {:>" + str(len(str(num_epochs))) + "}/{})" +
" ({:.2f} images/sec)").
format(iter+1, num_iters, epoch+1, num_epochs, total_batch_size/dt))
# 训练模型的平均精度
train_accuracy = accuracy(train_model)
# 网络测试,精度估计
test_accuracies = []
for _ in range(test_data_count / total_batch_size):
# 运行测试网络
workspace.RunNet(test_model.net.Proto().name)
test_accuracies.append(accuracy(test_model))
test_accuracy = np.average(test_accuracies)
print(
"Train accuracy: {:.3f}, test accuracy: {:.3f}".
format(train_accuracy, test_accuracy))
# Output images with confidence scores as the caption
display_images_and_confidence()4. resnet50_trainer.py
'''
ResNet50 的 multi-GPU 分布式计算
例如,可以在 imagenet data 上训练
单机多卡(single-machine multi-gpu) 时,可以设置 num_shards = 1.
多机多卡时,M 台机器,在所有的机器运行相同程序,指定 num_shards = M,shard_id = a,a是 [0, M-1] 内的整数
进行数据收集时,(训练进程互相已知),可以使用一个对所有进程都可见的目录路径,如,NFS目录,传递`file_store_path`参数; 或使用 Redis instance,传递 `redis_host` 和 `redis_port` 参数.
'''
# Module caffe2.python.examples.resnet50_trainer
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
import argparse
import logging
import numpy as np
import time
import os
from caffe2.python import core, workspace, experiment_util, data_parallel_model
from caffe2.python import data_parallel_model_utils, dyndep, optimizer
from caffe2.python import timeout_guard, model_helper, brew
from caffe2.proto import caffe2_pb2
import caffe2.python.models.resnet as resnet
from caffe2.python.modeling.initializers import Initializer, pFP16Initializer
import caffe2.python.predictor.predictor_exporter as pred_exp
import caffe2.python.predictor.predictor_py_utils as pred_utils
from caffe2.python.predictor_constants import predictor_constants as predictor_constants
logging.basicConfig()
log = logging.getLogger("resnet50_trainer")
log.setLevel(logging.DEBUG)
dyndep.InitOpsLibrary('@/caffe2/caffe2/distributed:file_store_handler_ops')
dyndep.InitOpsLibrary('@/caffe2/caffe2/distributed:redis_store_handler_ops')
def AddImageInput(model, reader, batch_size, img_size, dtype, is_test):
'''
The image input operator loads image and label data from the reader and
applies transformations to the images (random cropping, mirroring, ...).
'''
data, label = brew.image_input(model,
reader, ["data", "label"],
batch_size=batch_size,
output_type=dtype,
use_gpu_transform=True if model._device_type == 1 else False,
use_caffe_datum=True,
mean=128.,
std=128.,
scale=256,
crop=img_size,
mirror=1,
is_test=is_test,)
data = model.StopGradient(data, data)
def AddNullInput(model, reader, batch_size, img_size, dtype):
'''
The null input function uses a gaussian fill operator to emulate real image input.
A label blob is hardcoded to a single value. This is useful if you
want to test compute throughput or don't have a dataset available.
'''
suffix = "_fp16" if dtype == "float16" else ""
model.param_init_net.GaussianFill([],
["data" + suffix],
shape=[batch_size, 3, img_size, img_size],)
if dtype == "float16":
model.param_init_net.FloatToHalf("data" + suffix, "data")
model.param_init_net.ConstantFill([],
["label"],
shape=[batch_size],
value=1,
dtype=core.DataType.INT32, )
def SaveModel(args, train_model, epoch):
prefix = "[]_{}".format(train_model._device_prefix, train_model._devices[0])
predictor_export_meta = pred_exp.PredictorExportMeta(predict_net=train_model.net.Proto(),
parameters=data_parallel_model.GetCheckpointParams(train_model),
inputs=[prefix + "/data"],
outputs=[prefix + "/softmax"],
shapes={prefix + "/softmax": (1, args.num_labels),
prefix + "/data": (args.num_channels, args.image_size, args.image_size)})
# save the train_model for the current epoch
model_path = "%s/%s_%d.mdl" % (args.file_store_path,
args.save_model_name,
epoch,)
# set db_type to be "minidb" instead of "log_file_db", which breaks
# the serialization in save_to_db. Need to switch back to log_file_db
# after migration
pred_exp.save_to_db(db_type="minidb",
db_destination=model_path,
predictor_export_meta=predictor_export_meta,)
def LoadModel(path, model):
'''
Load pretrained model from file
'''
log.info("Loading path: {}".format(path))
meta_net_def = pred_exp.load_from_db(path, 'minidb')
init_net = core.Net(pred_utils.GetNet(meta_net_def, predictor_constants.GLOBAL_INIT_NET_TYPE))
predict_init_net = core.Net(
pred_utils.GetNet(meta_net_def, predictor_constants.PREDICT_INIT_NET_TYPE))
predict_init_net.RunAllOnGPU()
init_net.RunAllOnGPU()
assert workspace.RunNetOnce(predict_init_net)
assert workspace.RunNetOnce(init_net)
# Hack: fix iteration counter which is in CUDA context after load model
itercnt = workspace.FetchBlob("optimizer_iteration")
workspace.FeedBlob("optimizer_iteration", itercnt,
device_option=core.DeviceOption(caffe2_pb2.CPU, 0))
def RunEpoch(args, epoch, train_model, test_model, total_batch_size, num_shards, expname, explog, ):
'''
Run one epoch of the trainer.
TODO: add checkpointing here.
'''
# TODO: add loading from checkpoint
log.info("Starting epoch {}/{}".format(epoch, args.num_epochs))
epoch_iters = int(args.epoch_size / total_batch_size / num_shards)
for i in range(epoch_iters):
# This timeout is required (temporarily) since CUDA-NCCL
# operators might deadlock when synchronizing between GPUs.
timeout = 600.0 if i == 0 else 60.0
with timeout_guard.CompleteInTimeOrDie(timeout):
t1 = time.time()
workspace.RunNet(train_model.net.Proto().name)
t2 = time.time()
dt = t2 - t1
fmt = "Finished iteration {}/{} of epoch {} ({:.2f} images/sec)"
log.info(fmt.format(i + 1, epoch_iters, epoch, total_batch_size / dt))
prefix = "{}_{}".format(train_model._device_prefix,
train_model._devices[0])
accuracy = workspace.FetchBlob(prefix + '/accuracy')
loss = workspace.FetchBlob(prefix + '/loss')
train_fmt = "Training loss: {}, accuracy: {}"
log.info(train_fmt.format(loss, accuracy))
num_images = epoch * epoch_iters * total_batch_size
prefix = "{}_{}".format(train_model._device_prefix, train_model._devices[0])
accuracy = workspace.FetchBlob(prefix + '/accuracy')
loss = workspace.FetchBlob(prefix + '/loss')
learning_rate = workspace.FetchBlob(
data_parallel_model.GetLearningRateBlobNames(train_model)[0])
test_accuracy = 0
if (test_model is not None):
# Run 100 iters of testing
ntests = 0
for _ in range(0, 100):
workspace.RunNet(test_model.net.Proto().name)
for g in test_model._devices:
test_accuracy += np.asscalar(workspace.FetchBlob(
"{}_{}".format(test_model._device_prefix, g) + '/accuracy'
))
ntests += 1
test_accuracy /= ntests
else:
test_accuracy = (-1)
explog.log(
input_count=num_images,
batch_count=(i + epoch * epoch_iters),
additional_values={
'accuracy': accuracy,
'loss': loss,
'learning_rate': learning_rate,
'epoch': epoch,
'test_accuracy': test_accuracy,
}
)
assert loss < 40, "Exploded gradients :("
# TODO: add checkpointing
return epoch + 1
def Train(args):
# Either use specified device list or generate one
if args.gpus is not None:
gpus = [int(x) for x in args.gpus.split(',')]
num_gpus = len(gpus)
else:
gpus = list(range(args.num_gpus))
num_gpus = args.num_gpus
log.info("Running on GPUs: {}".format(gpus))
# Verify valid batch size
total_batch_size = args.batch_size
batch_per_device = total_batch_size // num_gpus
assert total_batch_size % num_gpus == 0, \
"Number of GPUs must divide batch size"
# Round down epoch size to closest multiple of batch size across machines
global_batch_size = total_batch_size * args.num_shards
epoch_iters = int(args.epoch_size / global_batch_size)
args.epoch_size = epoch_iters * global_batch_size
log.info("Using epoch size: {}".format(args.epoch_size))
# Create ModelHelper object
train_arg_scope = {'order': 'NCHW',
'use_cudnn': True,
'cudnn_exhaustive_search': True,
'ws_nbytes_limit': (args.cudnn_workspace_limit_mb * 1024 * 1024),}
train_model = model_helper.ModelHelper(
name="resnet50", arg_scope=train_arg_scope)
num_shards = args.num_shards
shard_id = args.shard_id
# Expect interfaces to be comma separated.
# Use of multiple network interfaces is not yet complete,
# so simply use the first one in the list.
interfaces = args.distributed_interfaces.split(",")
# Rendezvous using MPI when run with mpirun
if os.getenv("OMPI_COMM_WORLD_SIZE") is not None:
num_shards = int(os.getenv("OMPI_COMM_WORLD_SIZE", 1))
shard_id = int(os.getenv("OMPI_COMM_WORLD_RANK", 0))
if num_shards > 1:
rendezvous = dict(kv_handler=None,
num_shards=num_shards,
shard_id=shard_id,
engine="GLOO",
transport=args.distributed_transport,
interface=interfaces[0],
mpi_rendezvous=True,
exit_nets=None)
elif num_shards > 1:
# Create rendezvous for distributed computation
store_handler = "store_handler"
if args.redis_host is not None:
# Use Redis for rendezvous if Redis host is specified
workspace.RunOperatorOnce(
core.CreateOperator("RedisStoreHandlerCreate", [], [store_handler],
host=args.redis_host,
port=args.redis_port,
prefix=args.run_id,) )
else:
# Use filesystem for rendezvous otherwise
workspace.RunOperatorOnce(
core.CreateOperator("FileStoreHandlerCreate", [], [store_handler],
path=args.file_store_path,
prefix=args.run_id,) )
rendezvous = dict(kv_handler=store_handler,
shard_id=shard_id,
num_shards=num_shards,
engine="GLOO",
transport=args.distributed_transport,
interface=interfaces[0],
exit_nets=None )
else:
rendezvous = None
# Model building functions
def create_resnet50_model_ops(model, loss_scale):
initializer = (pFP16Initializer if args.dtype == 'float16'
else Initializer)
with brew.arg_scope([brew.conv, brew.fc],
WeightInitializer=initializer,
BiasInitializer=initializer,
enable_tensor_core=args.enable_tensor_core,
float16_compute=args.float16_compute):
pred = resnet.create_resnet50(model,
"data",
num_input_channels=args.num_channels,
num_labels=args.num_labels,
no_bias=True,
no_loss=True,)
if args.dtype == 'float16':
pred = model.net.HalfToFloat(pred, pred + '_fp32')
softmax, loss = model.SoftmaxWithLoss([pred, 'label'],
['softmax', 'loss'])
loss = model.Scale(loss, scale=loss_scale)
brew.accuracy(model, [softmax, "label"], "accuracy")
return [loss]
def add_optimizer(model):
stepsz = int(30 * args.epoch_size / total_batch_size / num_shards)
if args.float16_compute:
# TODO: merge with multi-prceision optimizer
opt = optimizer.build_fp16_sgd(model,
args.base_learning_rate,
momentum=0.9,
nesterov=1,
weight_decay=args.weight_decay, # weight decay included
policy="step",
stepsize=stepsz,
gamma=0.1 )
else:
optimizer.add_weight_decay(model, args.weight_decay)
opt = optimizer.build_multi_precision_sgd(model,
args.base_learning_rate,
momentum=0.9,
nesterov=1,
policy="step",
stepsize=stepsz,
gamma=0.1 )
return opt
# Define add_image_input function.
# Depends on the "train_data" argument.
# Note that the reader will be shared with between all GPUS.
if args.train_data == "null":
def add_image_input(model):
AddNullInput(model,
None,
batch_size=batch_per_device,
img_size=args.image_size,
dtype=args.dtype, )
else:
reader = train_model.CreateDB("reader",
db=args.train_data,
db_type=args.db_type,
num_shards=num_shards,
shard_id=shard_id, )
def add_image_input(model):
AddImageInput(model,
reader,
batch_size=batch_per_device,
img_size=args.image_size,
dtype=args.dtype,
is_test=False, )
def add_post_sync_ops(model):
"""Add ops applied after initial parameter sync."""
for param_info in model.GetOptimizationParamInfo(model.GetParams()):
if param_info.blob_copy is not None:
model.param_init_net.HalfToFloat(param_info.blob,
param_info.blob_copy[core.DataType.FLOAT] )
# Create parallelized model
data_parallel_model.Parallelize(train_model,
input_builder_fun=add_image_input,
forward_pass_builder_fun=create_resnet50_model_ops,
optimizer_builder_fun=add_optimizer,
post_sync_builder_fun=add_post_sync_ops,
devices=gpus,
rendezvous=rendezvous,
optimize_gradient_memory=False,
cpu_device=args.use_cpu,
shared_model=args.use_cpu, )
if args.model_parallel:
# Shift half of the activations to another GPU
assert workspace.NumCudaDevices() >= 2 * args.num_gpus
activations = data_parallel_model_utils.GetActivationBlobs(train_model)
data_parallel_model_utils.ShiftActivationDevices(
train_model,
activations=activations[len(activations) // 2:],
shifts={g: args.num_gpus + g for g in range(args.num_gpus)},
)
data_parallel_model.OptimizeGradientMemory(train_model, {}, set(), False)
workspace.RunNetOnce(train_model.param_init_net)
workspace.CreateNet(train_model.net)
# Add test model, if specified
test_model = None
if (args.test_data is not None):
log.info("----- Create test net ----")
test_arg_scope = {'order': "NCHW",
'use_cudnn': True,
'cudnn_exhaustive_search': True, }
test_model = model_helper.ModelHelper(
name="resnet50_test", arg_scope=test_arg_scope, init_params=False
)
test_reader = test_model.CreateDB("test_reader",
db=args.test_data,
db_type=args.db_type, )
def test_input_fn(model):
AddImageInput(model,
test_reader,
batch_size=batch_per_device,
img_size=args.image_size,
dtype=args.dtype,
is_test=True, )
data_parallel_model.Parallelize(
test_model,
input_builder_fun=test_input_fn,
forward_pass_builder_fun=create_resnet50_model_ops,
post_sync_builder_fun=add_post_sync_ops,
param_update_builder_fun=None,
devices=gpus,
cpu_device=args.use_cpu,
)
workspace.RunNetOnce(test_model.param_init_net)
workspace.CreateNet(test_model.net)
epoch = 0
# load the pre-trained model and reset epoch
if args.load_model_path is not None:
LoadModel(args.load_model_path, train_model)
# Sync the model params
data_parallel_model.FinalizeAfterCheckpoint(train_model)
# reset epoch. load_model_path should end with *_X.mdl,
# where X is the epoch number
last_str = args.load_model_path.split('_')[-1]
if last_str.endswith('.mdl'):
epoch = int(last_str[:-4])
log.info("Reset epoch to {}".format(epoch))
else:
log.warning("The format of load_model_path doesn't match!")
expname = "resnet50_gpu%d_b%d_L%d_lr%.2f_v2" % (args.num_gpus,
total_batch_size,
args.num_labels,
args.base_learning_rate, )
explog = experiment_util.ModelTrainerLog(expname, args)
# Run the training one epoch a time
while epoch < args.num_epochs:
epoch = RunEpoch(args,
epoch,
train_model,
test_model,
total_batch_size,
num_shards,
expname,
explog )
# Save the model for each epoch
SaveModel(args, train_model, epoch)
model_path = "%s/%s_" % (args.file_store_path,
args.save_model_name )
# remove the saved model from the previous epoch if it exists
if os.path.isfile(model_path + str(epoch - 1) + ".mdl"):
os.remove(model_path + str(epoch - 1) + ".mdl")
def main():
# TODO: use argv
parser = argparse.ArgumentParser(description="Caffe2: Resnet-50 training")
parser.add_argument("--train_data", type=str, default=None, required=True,
help="Path to training data (or 'null' to simulate)")
parser.add_argument("--test_data", type=str, default=None,
help="Path to test data")
parser.add_argument("--db_type", type=str, default="lmdb",
help="Database type (such as lmdb or leveldb)")
parser.add_argument("--gpus", type=str,
help="Comma separated list of GPU devices to use")
parser.add_argument("--num_gpus", type=int, default=1,
help="Number of GPU devices (instead of --gpus)")
parser.add_argument("--model_parallel", type=bool, default=False,
help="Split model over 2 x num_gpus")
parser.add_argument("--num_channels", type=int, default=3,
help="Number of color channels")
parser.add_argument("--image_size", type=int, default=227,
help="Input image size (to crop to)")
parser.add_argument("--num_labels", type=int, default=1000,
help="Number of labels")
parser.add_argument("--batch_size", type=int, default=32,
help="Batch size, total over all GPUs")
parser.add_argument("--epoch_size", type=int, default=1500000,
help="Number of images/epoch, total over all machines")
parser.add_argument("--num_epochs", type=int, default=1000,
help="Num epochs.")
parser.add_argument("--base_learning_rate", type=float, default=0.1,
help="Initial learning rate.")
parser.add_argument("--weight_decay", type=float, default=1e-4,
help="Weight decay (L2 regularization)")
parser.add_argument("--cudnn_workspace_limit_mb", type=int, default=64,
help="CuDNN workspace limit in MBs")
parser.add_argument("--num_shards", type=int, default=1,
help="Number of machines in distributed run")
parser.add_argument("--shard_id", type=int, default=0,
help="Shard id.")
parser.add_argument("--run_id", type=str,
help="Unique run identifier (e.g. uuid)")
parser.add_argument("--redis_host", type=str,
help="Host of Redis server (for rendezvous)")
parser.add_argument("--redis_port", type=int, default=6379,
help="Port of Redis server (for rendezvous)")
parser.add_argument("--file_store_path", type=str, default="/tmp",
help="Path to directory to use for rendezvous")
parser.add_argument("--save_model_name", type=str, default="resnet50_model",
help="Save the trained model to a given name")
parser.add_argument("--load_model_path", type=str, default=None,
help="Load previously saved model to continue training")
parser.add_argument("--use_cpu", type=bool, default=False,
help="Use CPU instead of GPU")
parser.add_argument('--dtype', default='float',
choices=['float', 'float16'],
help='Data type used for training')
parser.add_argument('--float16_compute', action='store_true',
help="Use float 16 compute, if available")
parser.add_argument('--enable-tensor-core', action='store_true',
help='Enable Tensor Core math for Conv and FC ops')
parser.add_argument("--distributed_transport", type=str, default="tcp",
help="Transport to use for distributed run [tcp|ibverbs]")
parser.add_argument("--distributed_interfaces", type=str, default="",
help="Network interfaces to use for distributed run")
args = parser.parse_args()
Train(args)
if __name__ == '__main__':
workspace.GlobalInit(['caffe2', '--caffe2_log_level=2'])
main()