深度学习与图像识别 图像检测
1、深度学习的优势
(1)从统计,计算的角度看,DL特别适合处理大数据
a、用较为复杂的模型降低模型偏差
b、用大数据提升统计估计的准确度
c、用可扩展的梯度下降算法求解大规模优化问题
这个大数据是除了数量上的大,还有更重要的是维度的大,很多算法本身是无法处理高纬度数据的,例如Kernel学习机相关的算法, 虽然理论上是先将数据向高维空间映射,然后在高维空间进行线性的求解,实际上在处理的时候还是回到原空间处理。传统的BP算法针对高维的数据也是效果不佳。
CNN等为什么对图像领域更加有效,因为其不但关注了全局特征,更是利用了图像识别领域非常重要的局部特征,应该是将局部特征抽取的算法融入到了神经网络中。图像本身的局部数据存在关联性,而这种局部关联性的特征是其他算法无法提取的。深度学习很重要的是对全局和局部特征的综合把握
(2)深度学习不是一个黑箱系统。它像概率模型一样,提供一套丰富的、基于联接主义的建模语言。利用这套语言系统,我们可以表达数据内在的丰富关系和结构。比如用卷积处理图像中的二维空间结构,用递归神经网络(Recurrent Neural Network)处理自然语言等数据中的时序结构
(3)深度学习几乎是唯一的端到端的学习系统
它直接作用于原始数据,自动逐层进行特征学习,整个过程直接优化目标函数。
2、深度学习在图像识别中的发展趋势
(1)模型层次不断加深
2012Alex 获得ImageNet 冠军,其所用的AlexNet5个卷积层 3个pool层 和2个全连接层
2014年获得ImageNet的GoogleNet,使用了59个卷积层,16个pool层和2个全连接层。
2016年微软的ResNet深度残差网络,用了152层的架构
(2)模型结构日趋复杂
传统的卷积神经网络都是简单的 conv-pool-FC
后来NIN 用mlpconv 代替传统的 conv层(mlp 实际上是卷积加传统的多层感知器 )。这样做一方面降低过拟合程度提高模型的推广能力,另一方面为大规模并行训练提供非常有利的条件
(3)海量的标注数据和适当的数据扰动
DL需要大量的数据,现有的图像数据不能满足需求,结合图像数据的特点,通过平移、水平翻转、旋转、缩放等数据扰动方式可以产生更多的有效数据,普遍提高识别模型的推广能力。
3、如何应用深度学习
(1) 将ImageNet上训练得到的模型作为起点,利用目标训练集和反向传播对其进行继续训练,将模型适应到特定的应用
(2) 如果目标训练集不够大,可以将底层的网络参数固定,沿用ImageNet上的训练集结果,只对上层进行更新。
(3) 直接采用ImageNet上训练得到的模型,把最高的隐含层的输出作为特征表达,代替常用的手工设计的特征。
4、卷积神经网络
(1)什么是卷积神经网络
卷积神经网络是一种为了处理二维输入数据而特殊设计的多层人工神经网络。网络中的每层都由多个二维平面组成,而每个平面由多个独立的神经元组成。相邻两层的神经元之间互相连接。
A、 卷积特征提取(局部连接,权值共享)
从图像中随机选取一小块局域作为训练样本,从该样本中学习到一些特征,然后将这些特征作为滤波器,与原始整个图像作卷积运算,从而得到原始图像中任意位置上的不同特征的激活值(见动图)
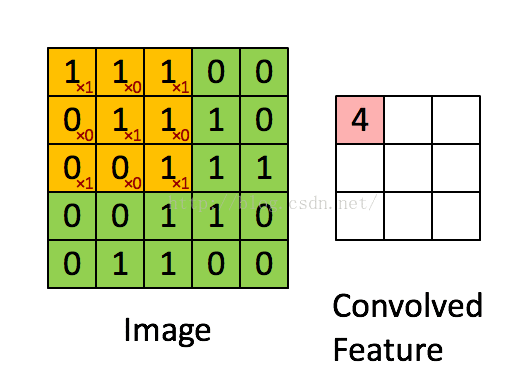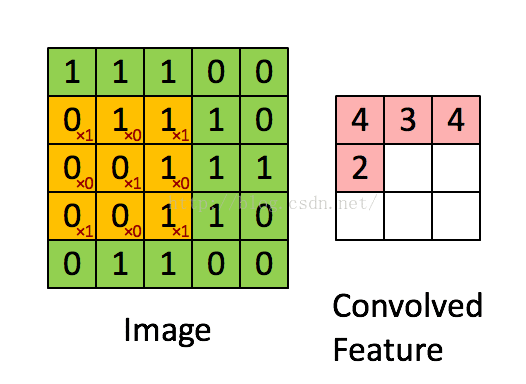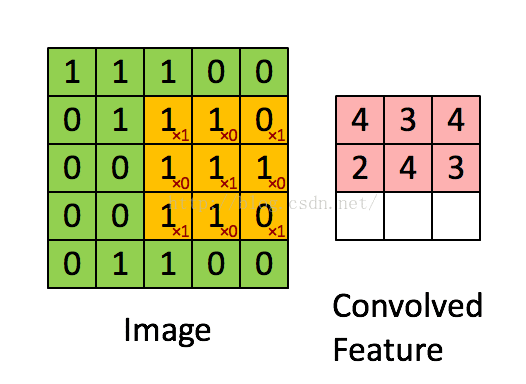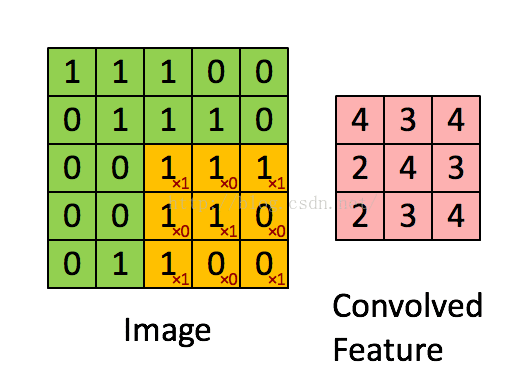
B、 池化
通过将卷积层提取的特征输入至分类器中进行训练,可以实现输出最终的分类结果。理论上可以直接输出,然而这将需要非常大的计算开销,特别是对于大尺寸高分辨率图像
由于图像具有一种“静态性”的属性,在图像的一个局部区域得到的特征极有可能在另一个局部区域同样适用。因此,对图像的一个局部区域中不同位置的特征进行聚合统计操作,这种操作统称为池化
(2)卷积神经网络的发展
A、 1990年,LeCun等在研究手写体数字识别问题时,首先提出来使用梯度反向传播算法训练的卷积神经网络模型,并在MNIST手写数字数据集上表现出了好的性能。
B、 2012年ImageNet比赛中 AlexKrizhevsky等提出的AlexNet首次将深度学习应用到大规模图像分类,并获得了冠军。
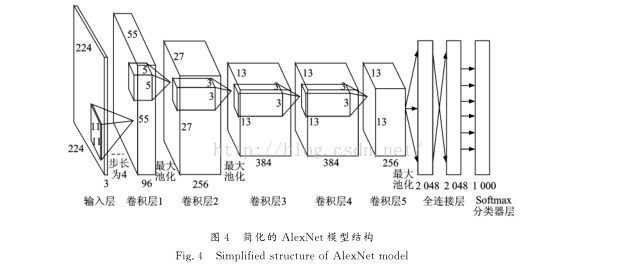
AlexNet用了5层卷积层和3层全连接层,最后用softmax进行分类。
改进点:
a、 采用dropout训练策略,在训练过程中将输入层和中间层的一些神经元随机置零。这模拟了噪声对输入数据的各种干扰使一些神经元对一些视觉模式产生漏检的情况。使得训练过程收敛过慢,但得到的网络模型更加鲁棒。
b、 采用ReLU(修正线性单元)作为激励函数,降低了计算的复杂度
c、 通过对训练样本镜像映射和加入随机平移扰动,产生了更多的训练样本,减少了过拟合
C、 2013 ImageNet的获胜队伍Clarifai 提出了卷积神经网络的可视化方法,运用反卷积网络对AlexNet的每个卷积层进行可视化,以此来分析每一层所学习到的特征从而加深了对于卷积神经网络为什么能在图像分类上取得好的效果的理解,并据此改进了该模型。
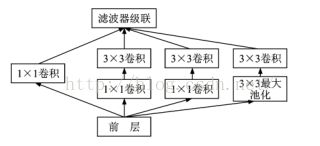
D、 2014 ImageNet Google团队
网络有22 层,受到赫布学习规则的启发,同时基于多尺度处理的方法对卷积神经网络作出改进。该文基于Network in Network思想提出了Inception模块。Inception 模块的结构如图所示,它的主要思想是想办法找出图像的最优局部稀疏结构,并将其近似地用稠密组件替代。这样做一方面可以实现有效的降维,从而能够在计算资源同等的情况下增加网络的宽度与深度;另一方面也可以减少需要训练的参数,从而减轻过拟合问题,提高模型的推广能力。
E、 2015年微软亚洲研究院所提出的152层的深度残差网络以绝对的优势获得图像检测、图像分类和图像定位3个项目的冠军
5、物体检测
(1)物体分类与检测的难点与挑战
物体分类与检测是视觉研究中的基本问题,也是一个非常具有挑战性的问题.物体分类与检测的难点与挑战在本文中分为3个层次:实例层次、类别
层次和语义层次,如图所示

a) 实例层次
针对单个物体实例而言,通常由于图像采集过程中光照条件、拍摄视角、距离的不同、物体自身的非刚体形变以及其他物体的部分遮挡,使得物体实例的表观特征产生很大的变化,给视觉识别算法带来了极大的困难
b) 类别层次
困难与挑战通常来自3个方面,
类内差大,也即属于同一类的物体表观特征差别比较大,其原因有前面提到的各种实例层次的变化,但这里更强调的是类内不同实例的差别,例如图(a)所示
类间模糊性,即不同类的物体实例具有一定的相似性,如图(b)背景的干扰在实际场景下,物体不可能出现在一个非常干净的背景下,往往相反,背景可能是非常复杂的、对我们感兴趣的物体存在干扰的,这使得识别问题的难度大大增加
c) 语义层次.
困难和挑战与图像的视觉语义相关,这个层次的困难往往非常难处理,特别是对现在的计算机视觉理论水平而言,一个典型的问题称为多重稳定性.如图(C)左边既可以看成是两个面对面的人,也可以看成是一个燃烧的蜡烛;右边则同时可以解释为兔子或者小鸭.同样的图像,不同的解释,这既与人的观察视角、关注点等物理条件有关,也与人的性格、经历等有关,而这恰恰是视觉识别系统难以处理的部分

(2)物体检测的发展(详细算法介绍见后续)
较有影响力的工作包括:
A、 RCNN (2013)
B、 Fast RCNN
C、 Faster RCNN
D、 R-FCN
E、 YOLO
F、 SSD
参考文献
【1】 基于深度学习的图像识别进展:百度的若干实践 (2015 百度公司)
【2】 图像识别中的深度学习 (2015 香港中文大学 王晓刚)
【3】 图像无图分类与检测算法综述 (2014 中国科学院自动化研究所模式识别国家重点实验室智能感知与计算研究中心)
【4】 深度卷积神经网络在计算机视觉中的应用研究综述 (2016 上海交通大学)
【5】 Rich feature hierarchies foraccurate object detection and semantic segmentation (2014)
【6】 Fast R-CNN (2015)
【7】 Faster R-CNN :Towards Real-Time Object Detection with Region Proposal Networks (2016)
【8】 Detection(网址上面描述各种检测算法)