这是对《Tensorflow实战google深度学习框架》整理的学习笔记。
一、TensorBoard的基础知识
TensorBoard是Tensorflow的可视化工具,它可以通过Tensorflow程序运行过程中输出的日志文件可视化Tensorflow程序的运行状态。TensorBoard和Tensorflow程序跑在不同的进程中,TensorBoard会自动读取最新的TensorFlow日志文件,并呈现当前TensorFlow程序运行的最新状态。
以下代码展示了一个简单的TensorFlow程序,在这个程序中完成了TensorBoard日志输出功能
import tensorflow as tf
# 定义一个简单的计算图,实现向量加法操作
input1 = tf.constant([1.0, 2.0, 3.0], name="input1")
input2 = tf.Variable(tf.random_uniform([3]), name="input2")
output = tf.add_n([input1, input2], name="add")
# 生成一个写日志的writer,并将当前的TensorFlow计算图写入日志。
# TensorFlow提供多种写日志文件API
writer = tf.summary.FileWriter("test_log", tf.get_default_graph())
writer.close()
运行下面的命令可以启动TensorBoard.
# 运行TensorBoard,并将日志的地址指向上面程序输出的地址
tensorboard --logdir=./test_log
运行上面的命令会启动一个服务,这个父母的端口默认为6006。通过浏览器打开localhost:6006。使用--port参数可以改变启动服务的端口。
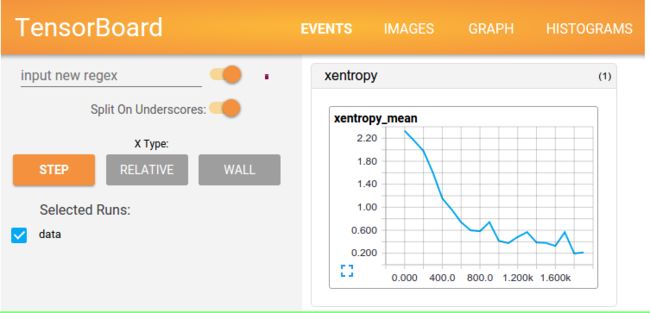
打开TensorBoard如下:
二、TensorFlow计算图可视化
- 2.1、命令空间与Tensorflow图上节点的关系
为了更好的组织可视化效果图中的计算节点,TensorBoard支持通过TensorFlow命名空间来整理可视化效果图上的节点。在TensorBoard的默认视图中,TensorFlow计算图中同一个命名空间中所有节点会被缩略成一个节点,只有顶层命名空间中的节点才会被显示在TensorBoard可视化效果图上。
除了tf.variable_scope函数可以管理命名空间外,tf.name_scope函数也提供了命名空间管理功能。这两个函数在大部分情况下是等价的,唯一的区别在于tf.get_varibale函数。
下例展示了这两个函数的区别:
import tensorflow as tf
# 建立命名空间"foo"
with tf.variable_scope("foo"):
a = tf.get_variable("bar", [1])
print a.name # 输出:foo/bar:0
# 建立命名空间"bar"
with tf.variable_scope("bar"):
b = tf.get_variable("bar", [1])
print b.name # 输出:bar/bar:0
# 建立命名空间"a"
with tf.name_scope("a"):
# 使用tf.Variable函数生成变量会受到tf.name_scope影响,
# 于是这个变量的名称为"a/Variable"
a = tf.Variable([1])
print a.name # 输出a/Variable:0
# tf.get_variable函数不受tf.name_scope函数的影响
# 于是变量并不在a这个命名空间中
a = tf.get_variable("b", [1])
print a.name # 输出的是b:0
# 建立命名空间"b"
with tf.name_scope("b"):
# 因为tf.get_variable不受tf.name_scope函数影响,所以这里将试图
# 获取名称为"a"的变量。然而,这个变量已经被申明,于是这里会报重
# 复申明的错误
tf.get_variable("b", [1])
通过对命名空间的管理,修改上述代码:
import tensorflow as tf
# 将输入定义放入各自的命名空间,从而使得TensorBoard可以根据命名空间
# 来整理可视化效果图上的节点
with tf.name_scope("input1"):
input1 = tf.constant([1.0, 2.0, 3.0], name="input1")
with tf.name_scope("input2"):
input2 = tf.Variable(tf.random_uniform([3]), name="input2")
output = tf.add_n([input1, input2], name="add")
writer = tf.summary.FileWriter("./test_log", tf.get_default_graph())
writer.close()
结果如下:
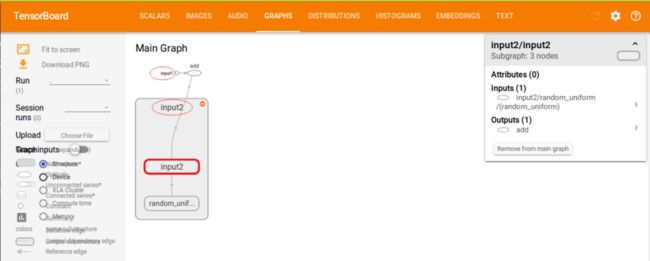
下例将给出一个样例来展示如何很好的可视化一个真实的神经网络结构图:
mnist_inference.py文件,主要用于定义神经网络节点个数、获取各层权重、神经网络的前向计算。
# mnist-inference.py
import tensorflow as tf
INPUT_NODE = 784 # 输入层节点
OUTPUT_NODE = 10 # 输出层节点
LAYER1_NODE = 500 # 隐含层节点
def get_weight_variable(shape, regularizer):
'''
函数意义:
获取指定shape的权重数据,并根据regularizer
确定是否把该权重加入正则损失集合
参数意义:
shape:网络连接层结构
regularizer:正则化方法
返回值:
返回获取的权重数据
'''
weights = tf.get_variable("weights", shape, initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None:
tf.add_to_collection('losses', regularizer(weights))
return weights
def inference(input_tensor, regularizer):
'''
函数意义:
计算神经网络的前向传播
参数意义:
input_tensor:输入数据的tensor
regularizer:正则化方法
返回值:
返回前向传播结果数据,注意此结果在最后一层是未经过激活的
'''
with tf.variable_scope('layer1'):
# 建立命名空间'layer1'
weights = get_weight_variable([INPUT_NODE, LAYER1_NODE], regularizer)
biases = tf.get_variable("biases", [LAYER1_NODE], initializer=tf.constant_initializer(0.0))
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights) + biases)
with tf.variable_scope('layer2'):
# 建立命名空间'layer2'
weights = get_weight_variable([LAYER1_NODE, OUTPUT_NODE], regularizer)
biases = tf.get_variable("biases", [OUTPUT_NODE], initializer=tf.constant_initializer(0.0))
layer2 = tf.matmul(layer1, weights) + biases
# 返回前向传播计算结果
return layer2
mnist_train.py文件展示了可视化一个真实的神经网络结构图。
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
"""
Created on Thu Aug 10 22:06:32 2017
@author: zhengbiao
"""
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_inference
import sys
reload(sys)
sys.setdefaultencoding('utf8')
# 定义神经网络的参数
BATCH_SIZE = 100 # Batch_Size的大小
LEARNING_RATE_BASE = 0.8 # 初始学习率
LEARNING_RATE_DECAY = 0.99 # 学习率衰减系数
REGULARIZATION_RATE = 0.0001 # 正则化率
TRAING_STEPS = 3000 # 迭代总步数
MOVING_AVERAGE_DECAY = 0.99 # 滑动平均率
def train(mnist):
# 输入数据的命名空间。
with tf.name_scope('input'):
x = tf.placeholder(tf.float32,
[None, mnist_inference.INPUT_NODE],
name='x-input')
y_ = tf.placeholder(tf.float32,
[None, mnist_inference.OUTPUT_NODE],
name='y-input')
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
y = mnist_inference.inference(x, regularizer)
global_step = tf.Variable(0, trainable=False)
# 处理滑动平均的命名空间。
with tf.name_scope("moving_average"):
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variables_averages_op = variable_averages.apply(tf.trainable_variables())
# 计算损失函数的命名空间。
with tf.name_scope("loss_function"):
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
# 定义学习率、优化方法及每一轮执行训练的操作的命名空间。
with tf.name_scope("train_step"):
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY,
staircase=True)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, variables_averages_op]):
train_op = tf.no_op(name='train')
# 训练模型。
with tf.Session() as sess:
tf.global_variables_initializer().run()
writer = tf.summary.FileWriter("./modified_mnist_train.log", tf.get_default_graph())
for i in range(TRAING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
if i % 1000 == 0:
# 配置运行时需要记录的信息。
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
# 运行时记录运行信息的proto。
run_metadata = tf.RunMetadata()
_, loss_value, step = sess.run(
[train_op, loss, global_step], feed_dict={x: xs, y_: ys},
options=run_options, run_metadata=run_metadata)
# 将节点在运行时的信息写入日志文件中
writer.add_run_metadata(run_metadata, "step%03d" % i)
print "After %d training step(s), loss on training batch is %g." % (step, loss_value)
else:
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys})
writer.close()
def main(argv=None):
mnist = input_data.read_data_sets("../datasets/MNIST_data", one_hot=True)
train(mnist)
if __name__ == '__main__':
main()
其中需要解释的几个函数如下:
with tf.control_dependencies([train_step, variables_averages_op]):
train_op = tf.no_op(name='train')
上述函数的作用指定了更新参数滑动平均值的操作和通过反向传播更新变量的操作同时进行。
函数tf.control_dependencies()的意义如下:
函数原型:
tf.control_dependencies(control_inputs)
函数意义:
使用the default graph对Graph.control_dependencies()函数的包装
参数意义:
control_inputs:A list of Operation or Tensor Object.
函数tf.Graph.control_dependencies()意义
函数原型:
tf.Graph.control_dependencies(control_inputs)
函数意义:
返回一个上下文管理器,这个上下文管理器指定了控制的依赖关系
例子:
with g.control_dependencies([a, b, c]):
# `d` and `e` will only run after `a`, `b`, and `c` have executed.
d = ...
e = ...
函数tf.no_op()
函数原型:
tf.no_op(name=None)
函数意义:
Does nothing. Only useful as a placeholder for control edges
函数参数:
A name for the operation (optional)
返回值:
The created Operation
TensorBoard截图如下:
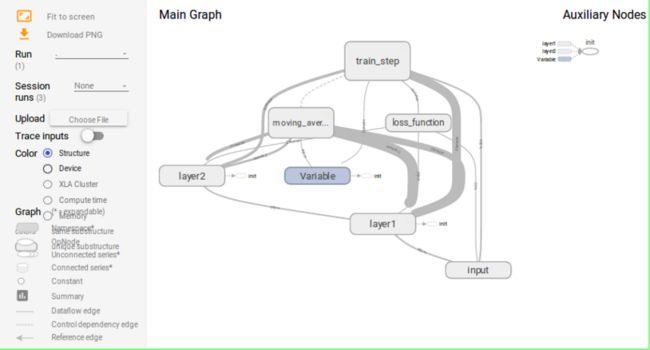
TensorBoard可以很好的展示整个神经网络的结构。
如上图所示,input节点代表了神经网络需要的输入数据;input节点的数据传输给layer1节点;layer1节点的数据传输给layer2节点,经过layer2的计算得到前向传播的结果。loss_function节点表示计算损失函数的过程,这个过程既依赖前向传播的结果来计算交叉熵(layer2到loss_function),又依赖于每一层所定义的变量来计算L2正则化损失(layer1和layer2到loss_function的边)。loss_function的计算结果会提供给神经网络的优化过程,也就是图中train_step所代表的节点。
效果图上的粗细表示的是两个节点之间传输的标量维度的总大小,而不是传输的标量个数(其实不太理解)。
效果图上的虚边表示计算之间的依赖关系,通过tf.control_dependencies函数指定了更新参数滑动平均值的操作和通过反向传播更新变量的操作需要同时进行,于是moving_average与train_step之间存在一条虚边。
TensorBoard将TensorFlow计算图分成主图(Main Graph)和辅助图(Auxiliary nodes)两个部分来呈现。TensorBoard会自动将连接比较多的节点放在辅助图中,使得主图的结构更加清晰。
TensorBoard不仅支持自动调整的方式,也支持手动调整的方式。
- 2.2、Tensorflow图上节点的可视化信息
TensorBoard还可以展示TensorFlow计算图上每个节点的基本信息以及运行时消耗的时间和空间。
以下代码将不同迭代轮数时每一个TensorFlow计算节点的运行时间和消耗的内存写入TensorFlow的日志文件。
with tf.Session() as sess:
tf.global_variables_initializer().run()
writer = tf.summary.FileWriter("./modified_mnist_train.log", tf.get_default_graph())
for i in range(TRAING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
if i % 1000 == 0:
# 配置运行时需要记录的信息。
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
# 运行时记录运行信息的proto。
run_metadata = tf.RunMetadata()
_, loss_value, step = sess.run(
[train_op, loss, global_step], feed_dict={x: xs, y_: ys},
options=run_options, run_metadata=run_metadata)
# 将节点在运行时的信息写入日志文件中
writer.add_run_metadata(run_metadata, "step%03d" % i)
print "After %d training step(s), loss on training batch is %g." % (step, loss_value)
else:
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys})
writer.close()
在TensorBoard的GRAPHS中,在页面Session runs选项中会出现一个下来菜单,这个下来菜单会显示所有通过writer.add_run_metadata函数记录的运行数据。下图显示的是,运行次数为2000次,各个节点所消耗的运行时间

在TensorBoard界面左侧的Color栏中,除了Computer time和Memory外,还有Structure和Device两个选项。
其中,展示的可视化效果图都是使用默认的Structure选项。在这个试视图中,灰色的节点表示没有其他节点和它拥有相同的结构。如果有两个节点的结果相同,他们会涂上相同的颜色。Device选项表示运算的设备,在使用GPU时,可以通过这种方式直观的看哪些节点被放到了那个GPU上或者CPU上。
TensorBoard上各项监控指标
TensorBoard除了可以可视化TensorFlow的计算图,还可以可视化EVENTS、IMAGES、AUDIO和HISTOGRAM等栏目。

可视化各项监控指标的流程:
SUMMARY_DIR = "log" # 日志路径
TRAINS_STEPS = 3000 # 训练的总步数
# 1.添加生成日志操作
tf.summary.scalar(name_scalar, scalar)
tf.summary.image(name_image, image_shape_input, image_num)
tf.summary.histogram(name_his, tensor)
# 2.统一日志生成操作
merged = tf.summary.merge_all()
with tf.Session() as sess:
# 3.初始化写日志类
summary_writer = tf.summary.FileWriter(SUMMARY_DIR, sess.graph)
for i in xrange(TRAIN_STEPS):
summary, _ = sess.run([merged, train_step], feed_dict={x: xs, y_:ys})
# 4.将所有日志写入日志文件
summary_writer.add_summary(summary, i)
# 5.关闭日志文件
summary_writer.close()
以下代码展示了神经网络训练mnist训练集时监控指标可视化。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
SUMMARY_DIR = "supervisor.log"
BATCH_SIZE = 100
TRAIN_STEPS = 3000
# 生成Tensor var的统计信息、均值信息和均方差信息
def variable_summaries(var, name):
# 通过tf.summary.histogram函数记录张量var中元素取值分布。
# tf.summary.histogram函数会生成一个Summary protocol buffer.
# 将Summary写入TensorBoard日志文件之后,可以在HISTOGRAM栏下看到对应名称的
# 图表
# tf.summary.histogram函数不会立刻执行,只有当sess.run函数明确调用这个操
# 作,TensorFlow才会真正生成并输出Summary protocol buffer
tf.summary.histogram(name, var)
# 计算张量var的平均值,并定义生成平均值信息日志操作
mean = tf.reduce_mean(var)
tf.summary.scalar(name+'/mean', mean)
# 计算张量var的标准差, 并定义生成其日志的操作
stddev = tf.sqrt(tf.reduce_mean(tf.square(var-mean)))
tf.summary.scalar(name+'/stddev', stddev)
# 定义生成一层全连接层的神经网络
def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):
# 将同一层神经网络放在同一个命名空间下
with tf.name_scope(layer_name):
# 申明神经网络边上的权重weights,并生成weights的监控项目
weights = tf.Variable(tf.truncated_normal([input_dim, output_dim], stddev=0.1))
variable_summaries(weights, 'weights')
# 定义biases、并生成biases的监控项目
biases = tf.Variable(tf.constant(0.0, shape=[output_dim]))
variable_summaries(biases, 'biases')
# 定义激活前的值、并生成激活前的值的监控项目
preactivate = tf.matmul(input_tensor, weights) + biases
tf.summary.histogram('pre_activations', preactivate)
# 计算preactivate的激活值
activations = act(preactivate, name='activation')
# 记录神经网络节点输出在经过激活函数之后的分布
tf.summary.histogram('activations', activations)
return activations
# 定义main函数
def main():
# 下载并加载MNIST_DATA,并one_hot化
mnist = input_data.read_data_sets("../datasets/MNIST_data", one_hot=True)
# 定义输入值x, y_
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x-input')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')
# 生成image监控
with tf.name_scope('input_reshape'):
image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', image_shaped_input, 10)
# 计算前向传播结果
hidden1 = nn_layer(x, 784, 500, 'layer1')
y = nn_layer(hidden1, 500, 10, 'layer2', act=tf.identity)# 计算前向传播结果
'''
tf.identity(input, name=None)
返回一个与输入张量或值相同的张量和内容
Args:
input: A Tensor.
name: A name for the operation(optional)
Returns:
A Tensor. Has the same type as input.
'''
# 计算交叉熵、并生成交叉熵的监控项目
with tf.name_scope('cross_entropy'):
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=y_))
tf.summary.scalar('cross_entropy', cross_entropy)
# 定义优化操作
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
# 定义模型在当前给定的数据上的正确率,并定义生成正确率的监控项目。
# 如果在sess.run时给定的数据是训练的batch,那么得到的准确率就是在这个训练batch上的正确率;
# 如果给定的数据为验证或者测试数据,那么得到的正确率就是当前模型在验证或测试集数据上的正确率。
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
'''
tf.equal(x, y, name=None)
Args:
x,y: all are Tensor.
returns:
Returns the truth value of (x == y) element-wise
'''
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
'''
tf.cast(x, dtype, name=None)
Casts a tensor to a new type
Args:
x: A Tensor or SparseTensor.
dtype: The destination type.
name: A name for the operation(optional)
returns:
A Tensor or SparseTensor with sanme shape as x.
For example:
# tensor 'a' is [1.8, 2.2], dtype=tf.float32
tf.cast(a, tf.int32) ==> [1, 2] # dtype=tf.int32
'''
tf.summary.scalar('accuracy', accuracy)
# 和tf.summary.scalar、tf.summary.histogram和tf.summary.image类似,这些函数不会立即执行
# 除非通过sess.run来明确调用这些函数。因为程序中定义的写日志操作比较多,一一调用很麻烦,所以
# Tensorflow提供了tf.summary.merge_all()整理所有的日志生成操作。在Tensorflow中,只要运行
# 这个操作就可以将代码中所有定义的日志生成操作执行一遍,从而将所有日志写入文件。
merged = tf.summary.merge_all()
with tf.Session() as sess:
# 初始化写日志的writer,并将当前Tensorflow计算图写入日志
summary_writer = tf.summary.FileWriter(SUMMARY_DIR, sess.graph)
# 初始化所有的变量
tf.global_variables_initializer().run()
for i in range(TRAIN_STEPS):
# 按BATCH_SIZE取出样本数据
xs, ys = mnist.train.next_batch(BATCH_SIZE)
# 运行训练步骤以及所有的日志生成操作,得到这次运行的日志。
summary, _ = sess.run([merged, train_step], feed_dict={x: xs, y_: ys})
# 将得到的所有日志写入日志文件,
# 这样TensorBoard程序就可以拿到这次运行所对应的运行信息。
summary_writer.add_summary(summary, i)
'''
add_summary(summary, global_step=None)
Adds a Summary protocol buffer to the event file
Ags:
summary: A Summary protocol buffer, optionally serialized as a string.
global_step:Number. Optional global step value to record with the summary.
'''
summary_writer.close()
if __name__ == '__main__':
main()
显示项目:

可视化结果如下:
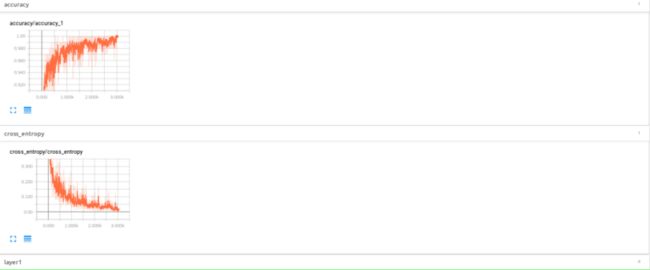
SCALAR结果如下:
IMAGE的结果如下:只显示最后一步的前四张

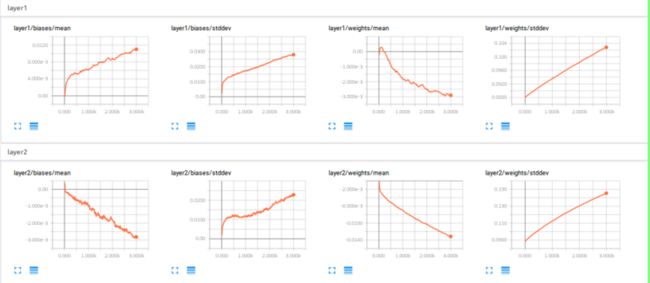
DISTRIBUTION结果如下:
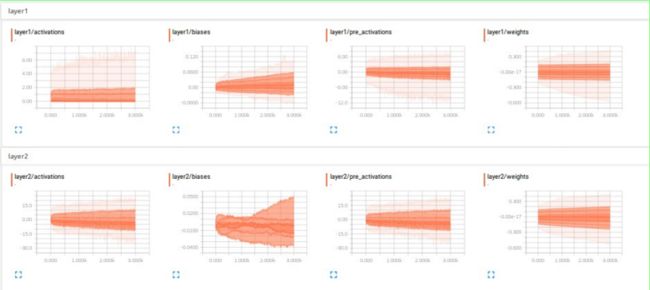
HISTOGRAM结果如下:
