Hive Sql列转行 行专列 及Spark Dataframe Api使用
文章目录
- 1.列转行
- 1.1 Hive Sql
- 1.2 Dataframe Api使用
- 2.行转列
- 2.1 Hive Sql
- 2.2Dataframe Api使用
spark dataframe api 1.6并不支持使用 2.0后才支持使用
1.列转行
1.1 Hive Sql
基础数据
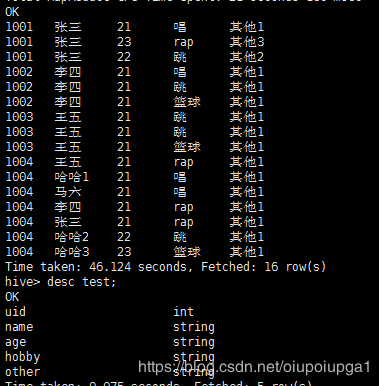
单列转行(去重)
select uid,concat_ws(',',collect_set(name))from test group by uid;
结果:
1001 张三
1002 李四
1003 王五
1004 马六,王五,哈哈2,张三,李四,哈哈1,哈哈3
单列转行(不去重)
select uid,concat_ws(',',collect_list(name)) from test group by uid;
结果:
1001 张三,张三,张三
1002 李四,李四,李四
1003 王五,王五,王五
1004 哈哈3,张三,马六,李四,王五,哈哈2,哈哈1
多列转行(去重)
select uid,concat_ws('、',collect_set(concat("name:",name,"a age:",age," hobby:",hobby))) from test group by uid;
结果:
1001 name:张三a age:21 hobby:唱、name:张三a age:23 hobby:rap、name:张三a age:22 hobby:跳
1002 name:李四a age:21 hobby:跳、name:李四a age:21 hobby:唱、name:李四a age:21 hobby:篮球
1003 name:王五a age:21 hobby:跳、name:王五a age:21 hobby:篮球
1004 name:马六a age:21 hobby:唱、name:哈哈1a age:21 hobby:唱、name:李四a age:21 hobby:rap、name:王五a age:21 hobby:rap、name:张三a age:21 hobby:rap、name:哈哈2a age:22 hobby:跳、name:哈哈3a age:23 hobby:篮球
多列转行(不去重)
select uid,concat_ws('、',collect_list(concat("name:",name,"a age:",age," hobby:",hobby))) from test group by uid;
结果:
1001 name:张三a age:23 hobby:rap、name:张三a age:21 hobby:唱、name:张三a age:22 hobby:跳
1002 name:李四a age:21 hobby:跳、name:李四a age:21 hobby:唱、name:李四a age:21 hobby:篮球
1003 name:王五a age:21 hobby:跳、name:王五a age:21 hobby:跳、name:王五a age:21 hobby:篮球
1004 name:李四a age:21 hobby:rap、name:哈哈1a age:21 hobby:唱、name:张三a age:21 hobby:rap、name:马六a age:21 hobby:唱、name:王五a age:21 hobby:rap、name:哈哈2a age:22 hobby:跳、name:哈哈3a age:23 hobby:篮球
1.2 Dataframe Api使用
spark一些初始化的对象就不写了
单列转行(去重)
val data=spark.sql("select *from default.test")
import org.apache.spark.sql.functions._
data.withColumn("a", concat_ws(",", collect_set(data("name")).over(Window.partitionBy("uid"))))
.select("uid","a").distinct().foreach(item=>println(item.getInt(0)+"\t"+item.getString(1)))
结果:
1001 张三
1002 李四
1003 王五
1004 王五,哈哈2,哈哈1,李四,哈哈3,张三,马六
单列转行(不去重)
data.withColumn("a", concat_ws(",", collect_list(data("name")).over(Window.partitionBy("uid"))))
.select("uid","a").distinct().foreach(item=>println(item.getInt(0)+"\t"+item.getString(1))
结果:
1001 张三,张三,张三
1002 李四,李四,李四
1003 王五,王五,王五
1004 李四,王五,马六,哈哈1,哈哈2,哈哈3,张三
多列转行(去重)
data.withColumn("a", concat_ws("、", collect_set(concat(lit("name:"), data("name"),
lit(" age:"), data("age"), lit(" hobby:"), data("hobby"))).
over(Window.partitionBy("uid")))).select("uid", "a").distinct().foreach(item => println(item.getInt(0) + "\t" + item.getString(1)))
结果:
1001 name:张三 age:21 hobby:唱、name:张三 age:23 hobby:rap、name:张三 age:22 hobby:跳
1002 name:李四 age:21 hobby:篮球、name:李四 age:21 hobby:唱、name:李四 age:21 hobby:跳
1003 name:王五 age:21 hobby:篮球、name:王五 age:21 hobby:跳
1004 name:马六 age:21 hobby:唱、name:哈哈1 age:21 hobby:唱、name:哈哈2 age:22 hobby:跳、name:哈哈3 age:23 hobby:篮球、name:李四 age:21 hobby:rap、name:王五 age:21 hobby:rap、name:张三 age:21 hobby:rap
多列转行(不去重)
data.withColumn("a", concat_ws("、", collect_list(concat(lit("name:"), data("name"),
lit(" age:"), data("age"), lit(" hobby:"), data("hobby"))).
over(Window.partitionBy("uid")))).select("uid", "a").distinct().foreach(item => println(item.getInt(0) + "\t" + item.getString(1)))
结果:
1001 name:张三 age:21 hobby:唱、name:张三 age:22 hobby:跳、name:张三 age:23 hobby:rap
1002 name:李四 age:21 hobby:篮球、name:李四 age:21 hobby:跳、name:李四 age:21 hobby:唱
1003 name:王五 age:21 hobby:跳、name:王五 age:21 hobby:跳、name:王五 age:21 hobby:篮球
1004 name:李四 age:21 hobby:rap、name:王五 age:21 hobby:rap、name:马六 age:21 hobby:唱、name:哈哈1 age:21 hobby:唱、name:哈哈2 age:22 hobby:跳、name:哈哈3 age:23 hobby:篮球、name:张三 age:21 hobby:rap
2.行转列
2.1 Hive Sql
基础数据

单行转列
select uid,username from test2 lateral view explode(split(name,','))a as username ;
结果:
1001 张三
1001 李四
1001 王五
1001 哈哈1
1001 哈哈2
1001 哈哈3
1002 张三
1002 李四
1002 王五
1002 哈哈1
1002 哈哈2
1002 哈哈3
1003 张三
1003 李四
1003 王五
1003 哈哈1
1003 哈哈2
1003 哈哈3
......
多行转列
select uid,username,userage from test2
lateral view explode(split(name,','))a as username
lateral view explode(split(age,','))b as userage ;
结果:
1001 张三 18
1001 张三 12
1001 张三 15
1001 张三 16
1001 张三 19
1001 张三 20
1001 李四 18
1001 李四 12
1001 李四 15
1001 李四 16
1001 李四 19
1001 李四 20
1001 王五 18
1001 王五 12
1001 王五 15
1001 王五 16
1001 王五 19
1001 王五 20
1001 哈哈1 18
1001 哈哈1 12
1001 哈哈1 15
1001 哈哈1 16
1001 哈哈1 19
1001 哈哈1 20
1001 哈哈2 18
1001 哈哈2 12
1001 哈哈2 15
1001 哈哈2 16
1001 哈哈2 19
1001 哈哈2 20
1001 哈哈3 18
1001 哈哈3 12
1001 哈哈3 15
1001 哈哈3 16
1001 哈哈3 19
1001 哈哈3 20
1002 张三 18
1002 张三 12
......
2.2Dataframe Api使用
单列转行
val data=spark.sql("select *from default.test2")
import org.apache.spark.sql.functions._
data.withColumn("a", explode(split(data("name"), ","))).select("uid", "a").show()
结果:
+----+---+
| uid| a|
+----+---+
|1001| 张三|
|1001| 李四|
|1001| 王五|
|1001|哈哈1|
|1001|哈哈2|
|1001|哈哈3|
|1002| 张三|
|1002| 李四|
|1002| 王五|
|1002|哈哈1|
|1002|哈哈2|
|1002|哈哈3|
|1003| 张三|
|1003| 李四|
|1003| 王五|
|1003|哈哈1|
|1003|哈哈2|
|1003|哈哈3|
|1004| 张三|
|1004| 李四|
+----+---+
only showing top 20 rows
多列转行
data.withColumn("a", explode(split(data("name"), ",")))
.withColumn("b", explode(split(data("age"), ",")))
.select("uid", "a","b").show()
结果:
+----+---+---+
| uid| a| b|
+----+---+---+
|1001| 张三| 18|
|1001| 张三| 12|
|1001| 张三| 15|
|1001| 张三| 16|
|1001| 张三| 19|
|1001| 张三| 20|
|1001| 李四| 18|
|1001| 李四| 12|
|1001| 李四| 15|
|1001| 李四| 16|
|1001| 李四| 19|
|1001| 李四| 20|
|1001| 王五| 18|
|1001| 王五| 12|
|1001| 王五| 15|
|1001| 王五| 16|
|1001| 王五| 19|
|1001| 王五| 20|
|1001|哈哈1| 18|
|1001|哈哈1| 12|
+----+---+---+
only showing top 20 rows