李宏毅学习笔记19.Transfer Learning
文章目录
- 前言
- Overview概述
- 左上格
- Model Fine-tuning
- Conservative Training
- Layer Transfer
- Multitask Learning
- 左下格
- Domain-adversarial training
- Zero-shot learning
- Example of Zero-shot Learning
- 右上格+右下格
- Self-taught learning
前言
以具体搞笑的实例切入迁移学习的概念,然后给出了迁移学习的概述,在概述中描述了一张可以看到不同种类迁移学习的类型,然后再从表格中每一个类型展开进行讲解。比ng的课程讲的更加细,毕竟ng那里只有几分钟,ng只讲了fine-tune和多任务,其他不知道后面有没有讲(因为我还没看完,捂脸。。。)。
公式输入请参考:在线Latex公式
Overview概述
迁移学习有很多种方法,下面给出一个表格来进行一个大概说明,但是老师提前给了一个warning :different terminology in different literature.
假设我们现在有一个想要做(实现)的task,和这个task直接相关的data,称为target data(有可能有标签也可能无标签),和task无关(没有直接相关)的data,称为source data(有可能有标签也可能无标签)
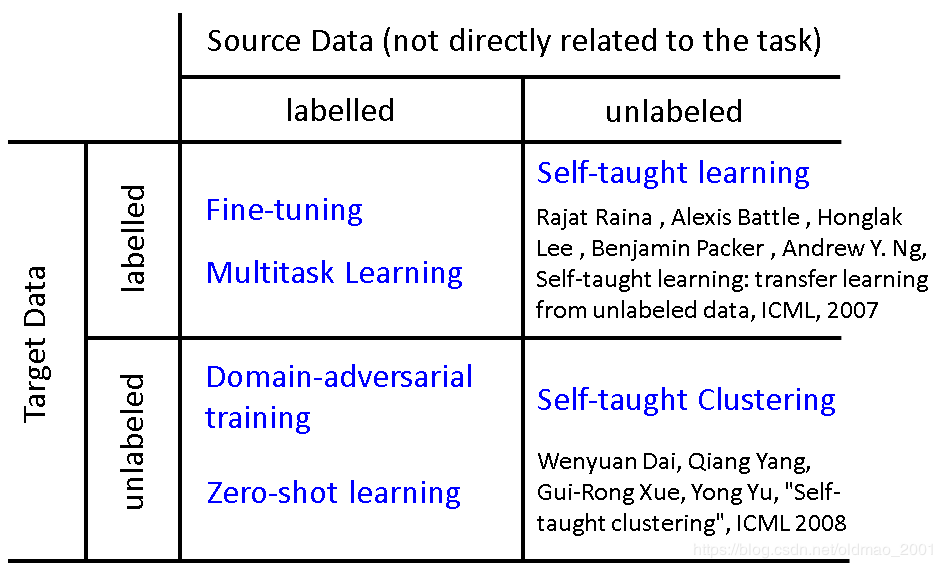
则迁移学习的类型可以从上表中看出来,下面就按照表中的不同类别进行讲解。根据表中四个格子来划分章节。
左上格
任务中,Target data和Source data都是有标签的。我们用不同的上标来表示,啰嗦一下,x是输入,y是输出:
Target data: ( x t , y t ) (x^t,y^t) (xt,yt)←←量很小(这个量如果很大就不需要迁移学习了)
Source data: ( x s , y s ) (x^s,y^s) (xs,ys)←←量很大
PS: One-shot learning: only a few examples in target domain.
举个栗子:(supervised) speaker adaption
Target data: audio data and its transcriptions of specific user
Source data: audio data and transcriptions from many speakers
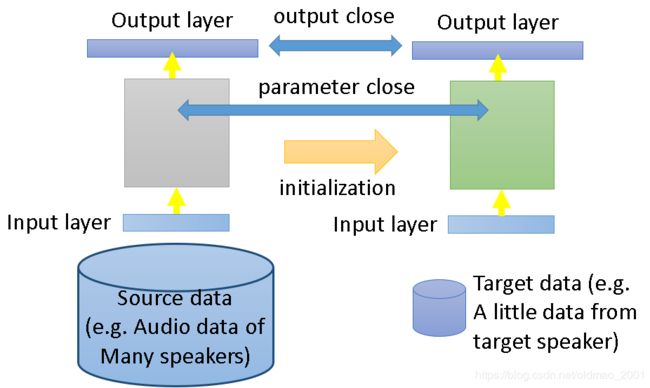
Idea: training a model by source data, then fine-tune the model by target data
Challenge: only limited target data, so be careful about overfitting
Model Fine-tuning
这里的fine-tune特别说明一下,就是把Source data丢到model里面训练一下,作为初始化,然后再丢Target data进行正式训练。但是如果Source data的量太大,可能会造成对traing data过拟合。咋整?往下看:
Conservative Training
Conservative Training,是先用source data训练做初始化,然后target data正式训练,然后为了防止对于training data过拟合,就会加限制,例如source data的output和targe data 的output不能差太远。这个限制就有点类似正则化。
一般有三种方法(支书语录):
1、source data的output和target data 的output不能差太远;
2、模型的参数不要变化太多;
3、只对最后几层进行微调。
第一种方法有很多种做法,其中一种为:先用target data在原始模型上输出预测值,保存原始模型参数记为A,用target data对原始模型进行训练微调,输出的结果跟原始模型A的输出结果进行对比,如果差太大就。。。?
Layer Transfer
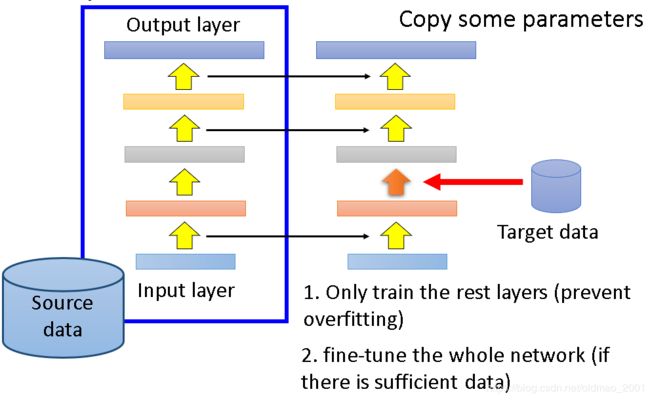
用Source data训练好模型之后,把参数copy到新模型中,然后用Target data在训练剩下的层,如果Target data足够多,则可以整个模型进行fine-tune。但是要copy那些层?不同task要copy的层往往是不一样的。例如:
- 语音识别:copy后几层,每个人发音不太一样,前面几层提取的特征太细与个人相关度较高,而后面几层则代表了发音的一般特征;
- 图像识别:copy前几层,前面几层包含的往往是纹理,线条等最简单的特征 ,可以用于其他物体的识别,后面几层则和识别的具体物体相关性较强不能用于其他物体的识别。
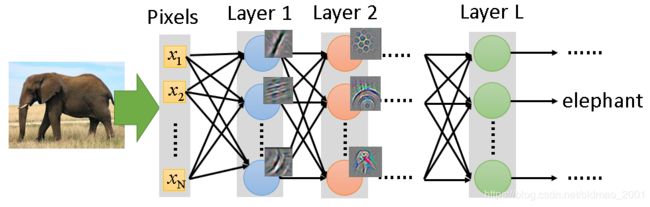
论文控给出了Bengio14年发在NIPS的实验:
实验把ImageNet的500个类归到Source data另外500个归为target data,横坐标是在做迁移学习的过程中copy的layer数量,数量为0代表完全没有做迁移学习。也就是图中的虚线(baseline),纵轴是Top 1 accuracy, 越高越好。
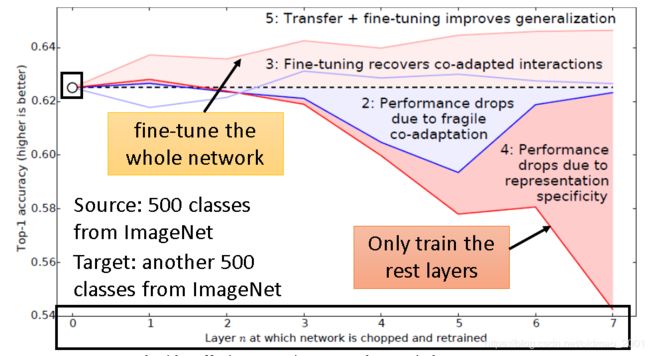
实验结果表明,copy的layer越多,结果是越差。但是copy前面几个layer性能没有很大改变,所以说前面几个layer是可以共用的。如果copy之后加上fine-tune整个model,结果是会变好的。当然这里的targe data是很多的。
Multitask Learning
整个ng课有讲,直接上图:
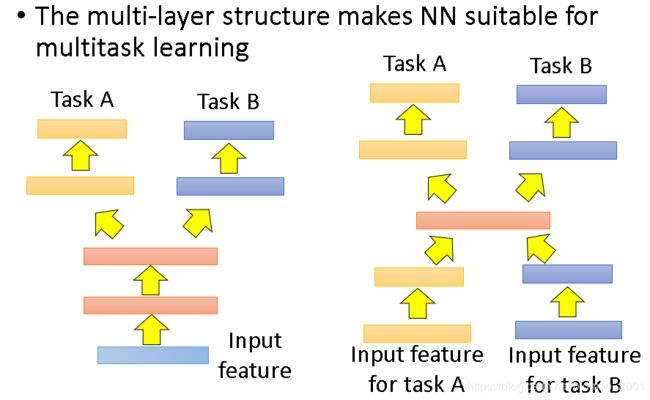
右边的结构ng是没有讲过。多任务学习比较成功的案例就是多语言识别:
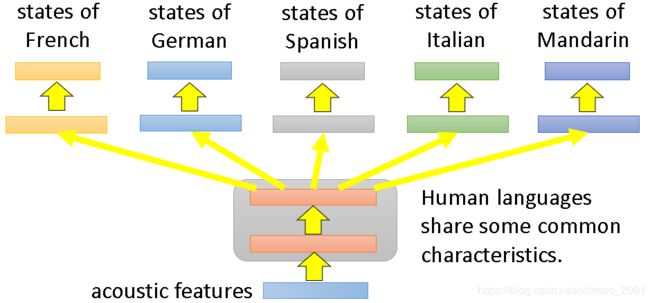
论文控请看:Similar idea in translation: Daxiang Dong, Hua Wu, Wei He, Dianhai Yu and Haifeng Wang, "Multi-task learning for multiple language translation.“, ACL 2015
老师强调,目前所有的语言,不分语系都可以混在一起训练,已有文章发表相关研究:
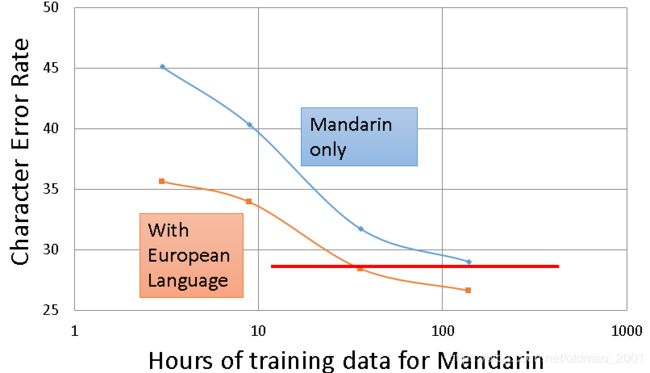
蓝色线条是只用普通话进行训练的结果,看到随着traning data时长(数据量)变大,错误率下降;
下面的橙色是用大量的欧洲语言作为source data 进行迁移学习后的结果。
论文控请看:Huang, Jui-Ting, et al. “Cross-language knowledge transfer using multilingual deep neural network with shared hidden layers.” ICASSP, 2013
左下格
任务描述:
Source data: ( x s , y s ) (x^s,y^s) (xs,ys),看做training data
Target data: x t x^t xt,这里只有input没有output,看做testing data
这两者是非常不匹配(一样)的,下面是一个栗子:

一般而言,不同domain的数据,在NN中提取出来的特征都是不一样的。例如:
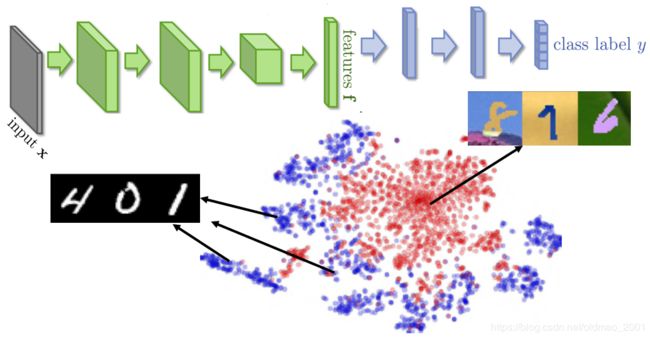
MINST是蓝色特征,MINST-M是红色特征,因此要想迁移学习就要把domain的feature去除掉。
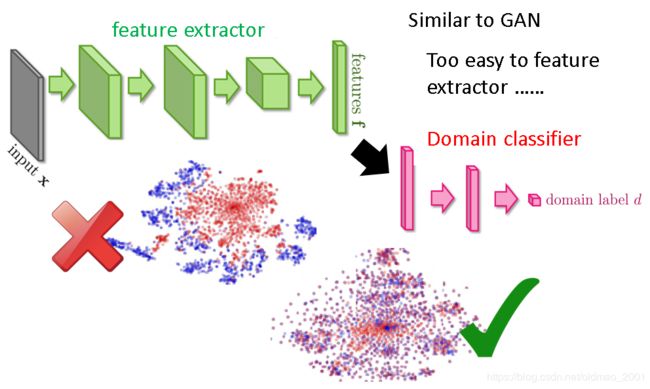
Domain-adversarial training
里面的adversarial和GAN里面A比较像。Domain-adversarial training就是要把domain的特征去掉,然后把所有的domain混合在一起,做法是在feature extractor后面接一个Domain classifier:
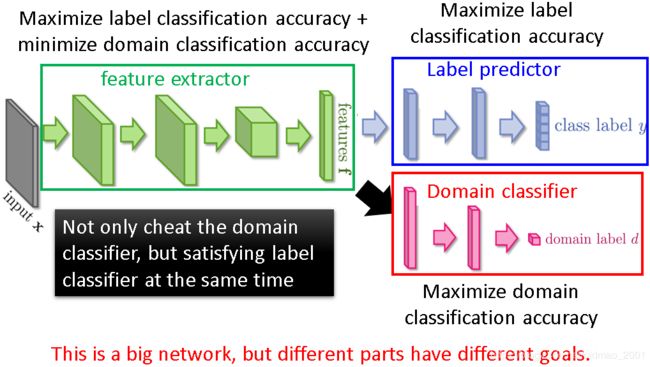
feature extractor不但要减少(minimize)domain feature,还要尽量(maximize)准确预测图片所属类别(这里是对应的数字)
上图的三个网络合在一起和传统的大的NN不一样的地方在于三个网络有各自的目标,传统的大网络一般都只有一个目标(最小化cost function),这里注意一下绿色和红色网络的目标是相反的。这个相反的目标在进行计算很简单,就加一个反向梯度层即可,如下图所示:
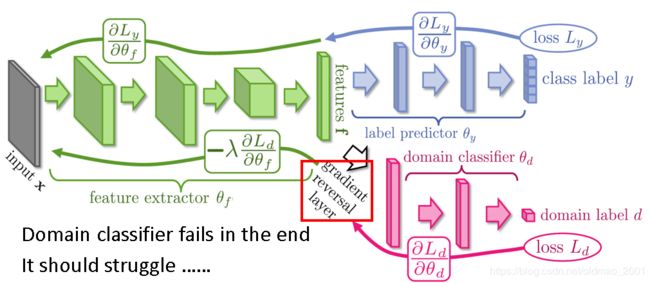
上图中的struggle的意思是domain classifer要奋力挣扎,不然就没有办法把domain feature混在一起(去除)。
论文控:Yaroslav Ganin, Victor Lempitsky, Unsupervised Domain Adaptation by Backpropagation, ICML, 2015
Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, Domain-Adversarial Training of Neural Networks, JMLR, 2016
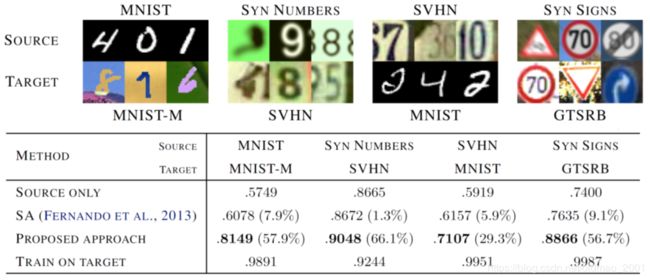
下图是论文结果,表格最左列代表不同方法,第一种是source only,第二种是13年的一种迁移学习方法,第三种就是Domain-adversarial training,第四种是用target data直接训练(这个其实是upper bound)
Zero-shot learning
任务描述:
Source data: ( x s , y s ) (x^s,y^s) (xs,ys),看做training data
Target data: x t x^t xt,这里只有input没有output,看做testing data
与上一小节不一样的是这里更加BT,两个data是不一样的task,例如:

其实这个问题在语音识别上有遇到,我们不可能在source data里面包含所有的单词,而是预测的时候常常会要预测相应的生词。
这个问题的解决在讲RNN里面有讲:RNN PART I
简单来说就是不要用词来衡量语音识别的最小单位,而是用音素来进行识别。根据语音识别的原理,来看在图像识别上是如何做?
将每个类别用它的属性来表示,而且属性要足够多,使得每个属性组合起来能够唯一表达某个分类。
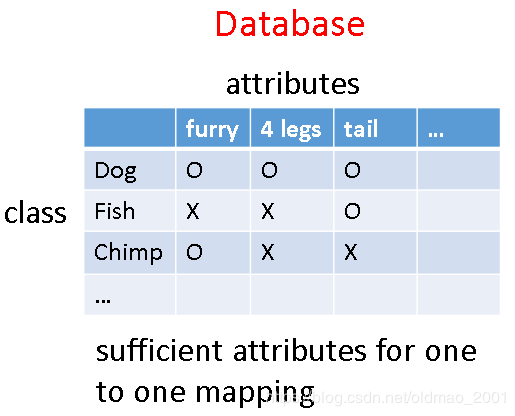
在训练时,不去分辨图片中的物体属于哪个类,而是去判断图片中有哪些属性,然后再根据属性来判断是哪类物体。
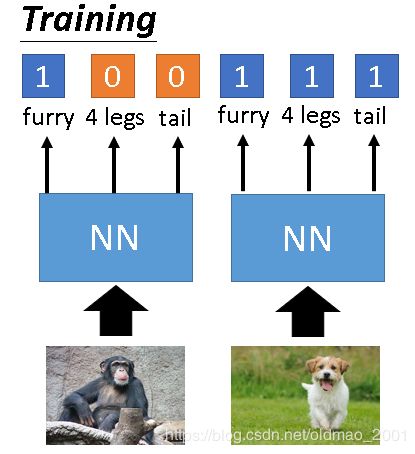
在testing时,则根据检测出来的属性来查询数据库,看属性和那个动物最像(接近)
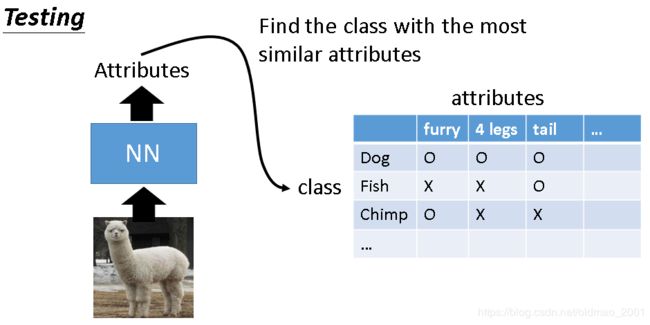
有的时候属性集会比较复杂,可以使用Attribute embedding,其中 f ( ∗ ) f(∗) f(∗) and g ( ∗ ) g(∗) g(∗) can be NN. 图片x和属性y都可以通过不同的函数 f ( x n ) f(x^n) f(xn)和 g ( y n ) g(y^n) g(yn)投影(降维)到embedding空间中,变成一个向量。训练的目标是 f ( x n ) f(x^n) f(xn)和 g ( y n ) g(y^n) g(yn)越接近越好。
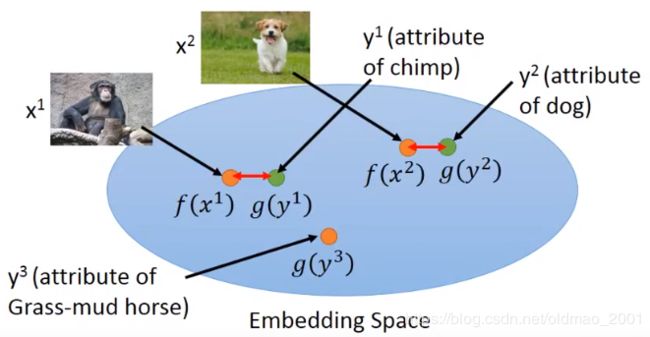
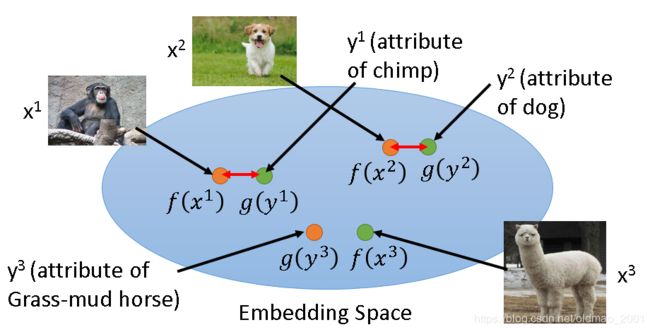
找到 f ( x n ) f(x^n) f(xn)和 g ( y n ) g(y^n) g(yn) 之后,现在有一个没有见过的图片 x 3 x^3 x3,然后可以通过 f ( x 3 ) f(x^3) f(x3)投影到embedding空间,找到和它最接近的vector: g ( y 3 ) g(y^3) g(y3)并得到对应的动物:草泥马。。。
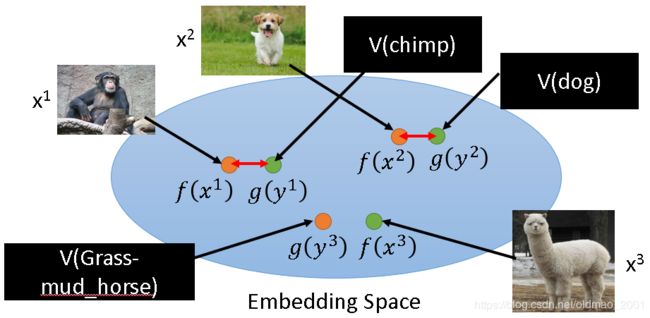
如果没有数据库,可以直接使用word vector替换属性
按照算法思想,要使得 f ( x n ) f(x^n) f(xn)和 g ( y n ) g(y^n) g(yn) 最近,则将损失函数设置为如下形式:
f ∗ , g ∗ = a r g m i n f , g ∑ n ∥ f ( x n ) − g ( y n ) ∥ 2 f^*,g^*=arg\underset{f,g}{min}\sum_n\left \| f(x^n)-g(y^n)\right \|_2 f∗,g∗=argf,gminn∑∥f(xn)−g(yn)∥2
意思是求 f ( x n ) f(x^n) f(xn)和 g ( y n ) g(y^n) g(yn) 的距离,并且最短,但是这样的形式是有问题的,这样模型会把所有的x和所有的y都投影到同一个点,这样就会距离最短,但是这样就会无法进行分类。因为xy是一个pair的话当然是要距离最短,但是这里的x和另外一个y’不是一个pair,这个时候需要距离越大越好,因此损失函数要改为:
f ∗ , g ∗ = a r g m i n f , g ∑ n m a x ( 0 , k − f ( x n ) ⋅ g ( y n ) + m a x m < > n f ( x n ) ⋅ g ( y m ) ) f^*,g^*=arg\underset{f,g}{min}\sum_nmax\left(0,k-f(x^n)\cdot g(y^n)+\underset{m<>n}{max}f(x^n)\cdot g(y^m)\right) f∗,g∗=argf,gminn∑max(0,k−f(xn)⋅g(yn)+m<>nmaxf(xn)⋅g(ym))
上式中 k k k是自定义的margin常量,来看max里面的内容,当max整个式子为0时:
k − f ( x n ) ⋅ g ( y n ) + m a x m < > n f ( x n ) ⋅ g ( y m ) < 0 k-f(x^n)\cdot g(y^n)+\underset{m<>n}{max}f(x^n)\cdot g(y^m)<0 k−f(xn)⋅g(yn)+m<>nmaxf(xn)⋅g(ym)<0
f ( x n ) ⋅ g ( y n ) − m a x m < > n f ( x n ) ⋅ g ( y m ) > k f(x^n)\cdot g(y^n)-\underset{m<>n}{max}f(x^n)\cdot g(y^m)>k f(xn)⋅g(yn)−m<>nmaxf(xn)⋅g(ym)>k
上式的意思是 f ( x n ) f(x^n) f(xn)和 g ( y n ) g(y^n) g(yn) 的内积要很大,大过其他所有 g ( y m ) g(y^m) g(ym)和 f ( x n ) f(x^n) f(xn)的内积,而且要大过一个margin k k k.
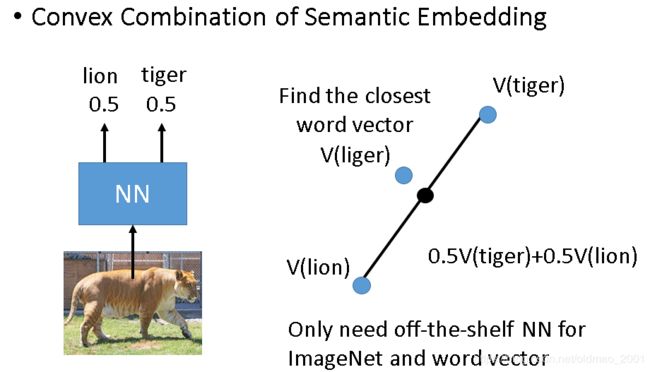
还有一种类似的算法,算法思想如下,先将图片丢入神经网络(这个网络可以是之前别人已经训练好的)中,得到分类概率结果,然后将两个分类对应的词向量按概率进行结合,得到一个新的词向量,然后找到最接近的词向量就是对应的结果。
以下是论文结果

第一个方法是普通的CNN,第二方法就是投影到embedding空间的算法,第三个就是NN加词向量的方法。
https://arxiv.org/pdf/1312.5650v3.pdf
Example of Zero-shot Learning
关于多语言投影为词向量后互译的结果。

右上格+右下格
这里讲得很简略
Self-taught learning
Learning to extract better representation from the source data (unsupervised approach)
Extracting better representation for target data