用隐马尔可夫模型(HMM)做命名实体识别——NER系列(二)
上一篇文章里《用规则做命名实体识别——NER系列(一)》,介绍了最简单的做命名实体识别的方法–规则。这一篇,我们循序渐进,继续介绍下一个模型——隐马尔可夫模型。
隐马尔可夫模型,看上去,和序列标注问题是天然适配的,所以自然而然的,早期很多做命名实体识别和词性标注的算法,都采用了这个模型。
这篇文章我将基于码农场的这篇文章《层叠HMM-Viterbi角色标注模型下的机构名识别》,来做解读。但原文中的这个算法实现是融入在HanLP里面的。不过他也有相应的训练词典,所以我在这篇文章里面也给出一个python实现,做一个简单的单层HMM模型,来识别机构名。
代码地址:https://github.com/lipengfei-558/hmm_ner_organization
1.隐马尔可夫模型(HMM)
隐马尔可夫模型(Hidden Markov Model,HMM),是一个统计模型。
关于这个模型,这里有一系列很好的介绍文章:http://www.52nlp.cn/category/hidden-markov-model
隐马尔可夫模型有三种应用场景,我们做命名实体识别只用到其中的一种——求观察序列的背后最可能的标注序列。
即根据输入的一系列单词,去生成其背后的标注,从而得到实体。
2.在序列标注中应用隐马尔可夫模型
HMM中,有5个基本元素:{N,M,A,B,π},我结合序列标志任务对这5个基本元素做一个介绍:
- N:状态的有限集合。在这里,是指每一个词语背后的标注。
- M:观察值的有限集合。在这里,是指每一个词语本身。
- A:状态转移概率矩阵。在这里,是指某一个标注转移到下一个标注的概率。
- B:观测概率矩阵,也就是发射概率矩阵。在这里,是指在某个标注下,生成某个词的概率。
- π:初始概率矩阵。在这里,是指每一个标注的初始化概率。
而以上的这些元素,都是可以从训练语料集中统计出来的。最后,我们根据这些统计值,应用维特比(viterbi)算法,就可以算出词语序列背后的标注序列了。
命名实体识别本质上就是序列标注,只需要自己定义好对应的标签以及模式串,就可以从标注序列中提取出实体块了。
3.实战:用HMM实现中文地名识别
3.1 参考论文以及网站
- 张华平, 刘群. 基于角色标注的中国人名自动识别研究[J]. 计算机学报, 2004, 27(1):85-91.
- 俞鸿魁, 张华平, 刘群. 基于角色标注的中文机构名识别[C]// Advances in Computation of Oriental Languages–Proceedings of the, International Conference on Computer Processing of Oriental Languages. 2003.
- 俞鸿魁, 张华平, 刘群,等. 基于层叠隐马尔可夫模型的中文命名实体识别[J]. 通信学报, 2006, 27(2):87-94.
-
码农场:层叠HMM-Viterbi角色标注模型下的机构名识别
3.2 任务
命名实体识别之中文机构名的识别。
3.3 语料
HanLP(https://github.com/hankcs/HanLP/releases)提供的语料:
我用的是data-for-1.3.3.zip,百度网盘下载地址:
https://pan.baidu.com/s/1o8Rri0y
下载后解压,我们要用的语料路径如下:
\data-for-1.3.3\data\dictionary\organization
其中,里面有两个我们要用到的语料文件,nt.txt和nt.tr.txt。这两个文件的数据统计自人民日报语料库。
① nt.txt:
词语标注统计词典,比如里面有一行是这样的:
会议 B 163 C 107 A 10
意思是,会议这个词作为B标签出现了163次,作为C标签出现了107次,作为A标签出现了10次.
② nt.tr.txt:
标签转移矩阵。如下图:
即,每一个标签转移到另一个标签的次数。比如第二行第四列的19945,代表着【A标签后面接着是C标签】出现了19945次。
以上语料我都提取出来放到代码目录的./data下了。
3.4 代码实现
代码的思路很直观,只要按照上面第2部分所说的,准备好5元组数据,然后用viterbi算法解码即可。
3.4.1 N:状态的有限集合
在机构名识别的这个任务中,论文《基于角色标注的中文机构名识别》把状态(角色)定义为以下集合: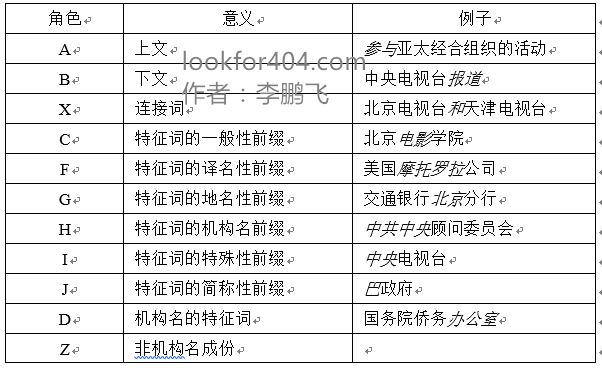
然而在HanLP的语料中,只有以下的标签,有多出来的,又不一样的:
A,B,C,D,F,G,I,J,K,L,M,P,S,W,X,Z
经过我的整理,完整的状态(角色)集合如下:
| 角色 | 意义 | 例子 |
| A | 上文 | 参与亚太经合组织的活动 |
| B | 下文 | 中央电视台报道 |
| X | 连接词 | 北京电视台和天津电视台 |
| C | 特征词的一般性前缀 | 北京电影学院 |
| F | 特征词的人名前缀 | 何镜堂纪念馆 |
| G | 特征词的地名性前缀 | 交通银行北京分行 |
| K | 特征词的机构名、品牌名前缀 | 中共中央顾问委员会
美国摩托罗拉公司 |
| I | 特征词的特殊性前缀 | 中央电视台
中海油集团 |
| J | 特征词的简称性前缀 | 巴政府 |
| D | 机构名的特征词 | 国务院侨务办公室 |
| Z | 非机构成分 | |
| L | 方位词 | 上游
东 |
| M | 数量词 | 36 |
| P | 数量+单位(名词) | 三维
两国 |
| W | 特殊符号,如括号,中括号 | ()
【】 |
| S | 开始标志 | 始##始 |
本程序以上面我整理的这个表格的状态角色为准(因为HanLP的语料词典里面就是这样定义的)。
3.4.2 M:观察值的有限集合
在这里,观察值就是我们看到的每个词。
不过有一个地方要注意一下,在语料词典nt.txt中,除了所有词语之外,还有下面8个特殊词语:
- 始##始
- 末##末
- 未##串
- 未##人
- 未##团
- 未##地
- 未##数
- 未##时
这些词语可以在层叠HMM中发挥作用,加进去可以提高识别精度,因为很多机构名里面都有人名和地名。
在使用我的这份代码之前,你可以用分词工具先识别出相关的词性,然后将对应命中的词语替换为上面的8个特殊词语,再调用函数,精确率会大大提高。
3.4.3 A:状态转移概率矩阵
在这里,它是指某一个标注转移到下一个标注的概率。
generate_data.py的generate_transition_probability()函数就是干这事的,它会生成一个transition_probability.txt,即转移概率矩阵。
3.4.4 B:观测概率矩阵(发射概率矩阵)
在这里,他是指在某个标注下,生成某个词的概率。
generate_data.py的generate_emit_probability()函数就是干这事的,它会生成一个emit_probability.txt,即观测概率矩阵(发射概率矩阵)。
3.4.5 π:初始概率矩阵
在这里,它是指每一个标注的初始化概率。
generate_data.py的genertate_initial_vector()函数就是干这事的,它会生成一个initial_vector.txt,即初始概率矩阵。
3.4.6 维特比(viterbi)算法解码
这部分代码是参考《统计方法》里面的实现写的,做了些调整,使之可以适用于这个机构名识别的任务。函数为viterbi() ,位于OrgRecognize.py里面。
使用这个函数,就能获得最佳标注序列。
3.4.7 匹配标注序列,得到机构名
在3.4.6里面,我们可以得到一个标注序列,哪些标注代表着实体呢?
HanLP作者整理了一个nt.pattern.txt(我也放置在./data/nt.pattern.txt下了),里面是所有可能是机构名的序列模式串(有点粗暴,哈哈),然后用Aho-Corasick算法来进行匹配。
为了简单起见突出重点,我的代码实现里,用的是循环遍历匹配,具体的实现在OrgRecognize.py里面的get_organization,函数的作用是,输入原词语序列、识别出来的标注序列和序列模式串,输出识别出来的机构名实体。
3.4.8 使用程序
代码地址:https://github.com/lipengfei-558/hmm_ner_organization
环境以及依赖:
- python2.7
- jieba分词(可选)
首先,运行以下脚本,生成transition_probability.txt,emit_probability.txt以及initial_vector.txt:
| 1 |
|
然后,运行
| 1 |
|
就可以了,不出意外,“中海油集团在哪里”这句话,会识别出“中海油集团”这个机构实体。
具体输入的句子逻辑,可以在main函数里面灵活修改,也可以结合jieba一起用。另外,python2.7的中文编码问题要注意了,如果你的输出序列很奇怪,很有可能是编码问题。
4.总结、待改进
用HMM来实现的命名实体识别算法,关键在于标签的自定义,你需要人工定义尽可能多的标签,然后在训练语料集里面自动标注这些标签,这也是最麻烦的地方。标注完语料集,生成HMM中的转移概率、初始概率、发射概率就很简单了,就是纯粹的统计。
整个模型也没什么参数,用这些统计的数字即可计算。
算法可能可以改进的点如下:
- 针对命名实体的维特比(viterbi)算法中,如果遇到未登录词,默认发射概率为0。我们可以额外引入相似度机制来解决这个问题,比如利用同义词表或者词向量相似度,我们找到和未登录词相似、同时也在观测概率矩阵里面出现的词语,用这个词语的发射概率(或者对其乘一个缩放系数),来代替未登录词的发射概率。
- 初始化概率对最终效果的影响有待考证。因为初始化概率影响着单词序列第一个词的标注,假如,仅仅用发射概率来决定第一个词的标注,效果会不会更好?
HMM算法默认只考虑前一个状态(词)的影响,忽略了更多上下文信息(特征)。后来的MEMM、CRF,都是循序渐进的改进方法。传统机器学习方法里面,CRF是主流,下一篇我会继续介绍CRF在命名实体识别任务上的应用。
代码和语料:
https://www.lookfor404.com/命名实体识别的语料和代码/
https://www.lookfor404.com/%e7%94%a8%e9%9a%90%e9%a9%ac%e5%b0%94%e5%8f%af%e5%a4%ab%e6%a8%a1%e5%9e%8bhmm%e5%81%9a%e5%91%bd%e5%90%8d%e5%ae%9e%e4%bd%93%e8%af%86%e5%88%ab-ner%e7%b3%bb%e5%88%97%e4%ba%8c/