Flume 1.8.0 开发者指南(中文教程)-个人翻译版
(为了方便学习利用周末翻译出来的,现在拿出来和大家免费分享,欢迎转载,但请尊重我个人的劳动成果,请标明来源)
(欢迎在评论中交流。如果觉得我翻译的还可以欢迎赞美和鼓励,如果发现了翻译不当之处也欢迎您无须客气的指出。谢谢!)
介绍
概览
Apache Flume 是一个分布式的,可靠、可用的系统,能够用来将大量的日志数据从很多不同的源收集、聚集和移动到中心化的数据存储中。
Apache Flume 是Apache基金会的顶级项目。目前在线上有两个release版本可用,分别是0.9.x和1.x。这篇文档适用于1.x的版本。对于0.9.x版本的代码,请参考Flume 0.9.x Developer Guide。
架构
数据流模型
“Event”是在Flume 代理上流动的数据单元。Event从Source流向Channel再流向Sink,并由Event接口的实现来呈现。一个Event会携带附有一组可选标头(字符串属性)的字节属性的有效载荷(payload https://baike.baidu.com/item/payload/3386751)。一个Flume代理是一个JVM进程,持有着允许Events从外部源流向外部目标的组件。
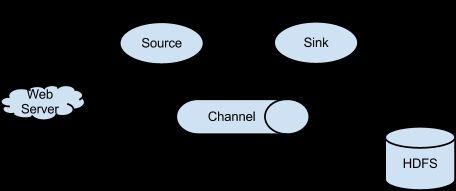
Source消费的Events有特定的格式,这些Events由外部源(如web服务)传递而来。例如,一个AvroSource实例可以用来从代理或是其他Flume客户端接收Avro类型的Events。Source在接收到Event后,会把Event保存到一个或多个Channels上。Channel是一种被动的存储,直到Sink消费之前会一直保存Event。在Flume中有一种Channel叫FileChannel,它使用本地文件系统作为后备存储。Sink负责从Channel中移除Event并将其放入像HDFS这样的外部存储中,或是交给下一流程的Source中。在一个客户端中的,Source和Sink会异步执行处理暂存在Channel上的Events。
可靠性
Event会被暂存在Flume代理的Channel中。在一个流程中,Sink负责将Event传递给下一个代理或是像HDFS这样的最终存储。只有当Event被存储到下一个代理或是最终存储后才会从Channel被Sink移除。这就是Flume中的单跳消息传递语义如何提供流的端到端可靠性。Flume使用事务性的方法来保证Events传递的可靠性。Sources和Sink封装了Channel提供的在一个事务中存储、取出Events的操作。这就保证了Events在流中通过点时的可靠性。在多过程流动的场景中,上一过程的Sink和下一个过程Source都会开启他们各自的事务来保证Event数据是安全的存储到了下一过程的Channel中。
Flume的构建
获取源码
使用Git检出。点击这里获取the git repository root。
Flume1.x的开发工作在“trunk”分支上进行,所以会用到这行命令:
git clone https://git-wip-us.apache.org/repos/asf/flume.git
编译、测试
Flume构建是maven化的,可以使用标准Maven命令来编译Flume:
- 仅仅编译:mvn clean compile
- 编译并运行单元测试:mvn clean test
- 运行单个测试:mvn clean test -Dtest=
, ,... -DfailIfNoTests=false - 打包:mvn clean install
- 打包并跳过测试:mvn clean install -DskipTests
请注意,Flume的构建需要在路径中有Google Protocol Buffers编译器。你可以根据这个教程(here)下载和安装它。
升级Protocol Buffer的版本
File channel依赖于Protocol Buffer。当升级由Flume使用的Protocol Buffer的版本时,有必要使用Protocol Buffer的protoc编译器来重新生成数据访问类,步骤如下:
- 在你的机器上安装需要版本的Protocol Buffer
- 更新pom.xml文件中Protocol Buffer的版本
- 在Flume中生成新的Protocol Buffer数据访问类,命令为:cd flume-ng-channels/flume-file-channel; mvn -P compile-proto clean package -DskipTests
- 给生成的文件加上缺失的Apache许可头
- 重新构建并测试Flume:cd ../..; mvn clean install
开发自定义组件
客户端(Client)
客户端在Events的起源点进行操作,并将它们递交给Flume代理。客户端通常会运行在正在使用数据的应用程序的空间中。Flume目前支持 Avro、log4j、syslog和带有JSON体的Http POST作为从外部源转移数据的方式。另外,ExecSource可以消费本地程序的输出,来作为Flume的输入。
当然很有可能会有这些可选项不支持的场景。在这种场景下,我们需要构建自定义机制来将数据喂给Flume。有两种方法来实现这点。第一种方法是创建自定义客户端,用来与Flume已有的Sources(比如AvroSource或是SyslogTcpSource)通信。自定义的客户端就需要将数据转换成能够被Flume这些Sources理解的消息。另一种方式是写一个自定义的Flume Source,能够直接与已存在的像使用了IPC或是RPC协议的应用程序通信,并将客户端的数据转换成Flume Events,然后推送到下游。请注意,要在Flume代理的Channel中存储的Events只能以Flume Events的格式存在。
客户端 SDK
尽管Flume包含许多内置机制(即Sources)来获取数据,但通常需要能够直接从自定义应用程序与Flume进行通信。Flume Client SDK是是能够使应用程序通过RPC连接到Flume并向Flume数据流发送数据的类库。
RPC客户端接口
对Flume的RPC客户端接口的实现,封装了由Flume支持的RPC机制。用户的应用程序可以简单地调用Flume Client SDK的append(Event)或appendBatch(List
RPC 客户端 - Avro 和 Thrift
从Flume 1.4.0开始,Avro成为默认的RPC协议。NettyAvroRpcClient和ThriftRpcClient实现了RpcClient接口。客户端需要先使用目标Flume代理的host和端口创建对象,然后才能使用RpcClient将数据发送到代理上。下面是一个示例,来说明如何在用户生成数据的应用程序中使用Flume Client SDK API:
import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.api.RpcClient;
import org.apache.flume.api.RpcClientFactory;
import org.apache.flume.event.EventBuilder;
import java.nio.charset.Charset;
public class MyApp {
public static void main(String[] args) {
MyRpcClientFacade client = new MyRpcClientFacade();
// Initialize client with the remote Flume agent's host and port
client.init("host.example.org", 41414);
// Send 10 events to the remote Flume agent. That agent should be
// configured to listen with an AvroSource.
String sampleData = "Hello Flume!";
for (int i = 0; i < 10; i++) {
client.sendDataToFlume(sampleData);
}
client.cleanUp();
}
}
class MyRpcClientFacade {
private RpcClient client;
private String hostname;
private int port;
public void init(String hostname, int port) {
// Setup the RPC connection
this.hostname = hostname;
this.port = port;
this.client = RpcClientFactory.getDefaultInstance(hostname, port);
// Use the following method to create a thrift client (instead of the above line):
// this.client = RpcClientFactory.getThriftInstance(hostname, port);
}
public void sendDataToFlume(String data) {
// Create a Flume Event object that encapsulates the sample data
Event event = EventBuilder.withBody(data, Charset.forName("UTF-8"));
// Send the event
try {
client.append(event);
} catch (EventDeliveryException e) {
// clean up and recreate the client
client.close();
client = null;
client = RpcClientFactory.getDefaultInstance(hostname, port);
// Use the following method to create a thrift client (instead of the above line):
// this.client = RpcClientFactory.getThriftInstance(hostname, port);
}
}
public void cleanUp() {
// Close the RPC connection
client.close();
}
}远程的Flume代理需要有相应的Source实现来监听某个端口,比如AvroSource或如果使用的Thrift客户端则需要ThriftSource。下面是等待从MyApp连接的Flume代理配置示例:
a1.channels = c1
a1.sources = r1
a1.sinks = k1
a1.channels.c1.type = memory
a1.sources.r1.channels = c1
a1.sources.r1.type = avro
# For using a thrift source set the following instead of the above line.
# a1.source.r1.type = thrift
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 41414
a1.sinks.k1.channel = c1
a1.sinks.k1.type = logger为了更加灵活,默认的Flume客户端实现(NettyAvroRpcClient和ThriftRpcClient)可以使用这些配置:
client.type = default (for avro) or thrift (for thrift)
hosts = h1 # default client accepts only 1 host
# (additional hosts will be ignored)
hosts.h1 = host1.example.org:41414 # host and port must both be specified
# (neither has a default)
batch-size = 100 # Must be >=1 (default: 100)
connect-timeout = 20000 # Must be >=1000 (default: 20000)
request-timeout = 20000 # Must be >=1000 (default: 20000)安全RPC客户端 - Thrift
从Flume 1.6.0开始,Thrift Source和Sink支持基于kerberos的授权认证。客户端使用SecureRpcClientFactory类的getThriftInstance方法获得SecureThriftRpcClient对象。SecureThriftRpcClient继承自实现了RpcClient接口的ThriftRpcClient类。kerberos 认证模块位于flume-ng-auth模块中,在使用SecureRpcClientFactory时要求这一模块在classpath中。客户端主体和客户端密钥表都应作为参数通过属性传递,它们反映客户端的凭据以对kerberos KDC进行身份验证。此外,还应提供此客户端连接到的目标Thrift源的服务器主体。接下来的示例展示了如何在用户生成数据的应用程序中使用SecureRpoClientFactory:
import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.event.EventBuilder;
import org.apache.flume.api.SecureRpcClientFactory;
import org.apache.flume.api.RpcClientConfigurationConstants;
import org.apache.flume.api.RpcClient;
import java.nio.charset.Charset;
import java.util.Properties;
public class MyApp {
public static void main(String[] args) {
MySecureRpcClientFacade client = new MySecureRpcClientFacade();
// Initialize client with the remote Flume agent's host, port
Properties props = new Properties();
props.setProperty(RpcClientConfigurationConstants.CONFIG_CLIENT_TYPE, "thrift");
props.setProperty("hosts", "h1");
props.setProperty("hosts.h1", "client.example.org"+":"+ String.valueOf(41414));
// Initialize client with the kerberos authentication related properties
props.setProperty("kerberos", "true");
props.setProperty("client-principal", "flumeclient/[email protected]");
props.setProperty("client-keytab", "/tmp/flumeclient.keytab");
props.setProperty("server-principal", "flume/[email protected]");
client.init(props);
// Send 10 events to the remote Flume agent. That agent should be
// configured to listen with an AvroSource.
String sampleData = "Hello Flume!";
for (int i = 0; i < 10; i++) {
client.sendDataToFlume(sampleData);
}
client.cleanUp();
}
}
class MySecureRpcClientFacade {
private RpcClient client;
private Properties properties;
public void init(Properties properties) {
// Setup the RPC connection
this.properties = properties;
// Create the ThriftSecureRpcClient instance by using SecureRpcClientFactory
this.client = SecureRpcClientFactory.getThriftInstance(properties);
}
public void sendDataToFlume(String data) {
// Create a Flume Event object that encapsulates the sample data
Event event = EventBuilder.withBody(data, Charset.forName("UTF-8"));
// Send the event
try {
client.append(event);
} catch (EventDeliveryException e) {
// clean up and recreate the client
client.close();
client = null;
client = SecureRpcClientFactory.getThriftInstance(properties);
}
}
public void cleanUp() {
// Close the RPC connection
client.close();
}
}远程的ThriftSource将会开启kerberos模式。下面是Flume代理配置的例子:
a1.channels = c1
a1.sources = r1
a1.sinks = k1
a1.channels.c1.type = memory
a1.sources.r1.channels = c1
a1.sources.r1.type = thrift
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 41414
a1.sources.r1.kerberos = true
a1.sources.r1.agent-principal = flume/[email protected]
a1.sources.r1.agent-keytab = /tmp/flume.keytab
a1.sinks.k1.channel = c1
a1.sinks.k1.type = logger故障转移客户端
此类包装默认的Avro RPC客户端,以便为客户端提供故障转移处理功能。这需要一个代表Flume代理的以空格分割的
// Setup properties for the failover
Properties props = new Properties();
props.put("client.type", "default_failover");
// List of hosts (space-separated list of user-chosen host aliases)
props.put("hosts", "h1 h2 h3");
// host/port pair for each host alias
String host1 = "host1.example.org:41414";
String host2 = "host2.example.org:41414";
String host3 = "host3.example.org:41414";
props.put("hosts.h1", host1);
props.put("hosts.h2", host2);
props.put("hosts.h3", host3);
// create the client with failover properties
RpcClient client = RpcClientFactory.getInstance(props);为了更加灵活,Flume故障转移客户端的实现类FailoverRpcClient能够通过以下属性来配置:
client.type = default_failover
hosts = h1 h2 h3 # at least one is required, but 2 or
# more makes better sense
hosts.h1 = host1.example.org:41414
hosts.h2 = host2.example.org:41414
hosts.h3 = host3.example.org:41414
max-attempts = 3 # Must be >=0 (default: number of hosts
# specified, 3 in this case). A '0'
# value doesn't make much sense because
# it will just cause an append call to
# immmediately fail. A '1' value means
# that the failover client will try only
# once to send the Event, and if it
# fails then there will be no failover
# to a second client, so this value
# causes the failover client to
# degenerate into just a default client.
# It makes sense to set this value to at
# least the number of hosts that you
# specified.
batch-size = 100 # Must be >=1 (default: 100)
connect-timeout = 20000 # Must be >=1000 (default: 20000)
request-timeout = 20000 # Must be >=1000 (default: 20000)负载平衡 RPC 客户端
Flume客户端SDK也支持在多个主机之间负载均衡的RpcClient。这一类型的客户端需要能代表Flume的用空格分隔的
如果启用了backoff,那么客户端将会临时把连接失败的主机放入黑名单中,直到给定的超时之前都不会将这些机器作为故障转移主机之选。当超时过去时,如果主机仍然没有响应,则认为这是顺序故障,并且超时会以指数方式增加,以避免在无响应主机上长时间等待。
backoff时长的最大值可以由maxBackoff来设置,单位毫秒。默认值是30秒(在类OrderSelector中指定,它也是两个负载均衡策略类的父类)。backoff超时时长会在每次连续失败后成倍上升到可能的最大值,这个值得最大限制是65536秒(大约18.2小时)。例如:
// Setup properties for the load balancing
Properties props = new Properties();
props.put("client.type", "default_loadbalance");
// List of hosts (space-separated list of user-chosen host aliases)
props.put("hosts", "h1 h2 h3");
// host/port pair for each host alias
String host1 = "host1.example.org:41414";
String host2 = "host2.example.org:41414";
String host3 = "host3.example.org:41414";
props.put("hosts.h1", host1);
props.put("hosts.h2", host2);
props.put("hosts.h3", host3);
props.put("host-selector", "random"); // For random host selection
// props.put("host-selector", "round_robin"); // For round-robin host
// // selection
props.put("backoff", "true"); // Disabled by default.
props.put("maxBackoff", "10000"); // Defaults 0, which effectively
// becomes 30000 ms
// Create the client with load balancing properties
RpcClient client = RpcClientFactory.getInstance(props);为了更加灵活,负载均衡的Flume客户端实现类(LoadBalancingRpcClient)可以使用如下配置:
client.type = default_loadbalance
hosts = h1 h2 h3 # At least 2 hosts are required
hosts.h1 = host1.example.org:41414
hosts.h2 = host2.example.org:41414
hosts.h3 = host3.example.org:41414
backoff = false # Specifies whether the client should
# back-off from (i.e. temporarily
# blacklist) a failed host
# (default: false).
maxBackoff = 0 # Max timeout in millis that a will
# remain inactive due to a previous
# failure with that host (default: 0,
# which effectively becomes 30000)
host-selector = round_robin # The host selection strategy used
# when load-balancing among hosts
# (default: round_robin).
# Other values are include "random"
# or the FQCN of a custom class
# that implements
# LoadBalancingRpcClient$HostSelector
batch-size = 100 # Must be >=1 (default: 100)
connect-timeout = 20000 # Must be >=1000 (default: 20000)
request-timeout = 20000 # Must be >=1000 (default: 20000)嵌入代理
Flume提供了嵌入代理api,允许用户将代理嵌入到他们自己的应用程序中。这个代理程序应该是轻量级的,因此不能带有所有的Sources、Sinks和Channels。只嵌入特定的使用的source,通过put、putAll方法将events发送给嵌入代理对象。只允许文件通道和内存通道作为通道,而Avro Sink是唯一支持的sink。嵌入代理也支持拦截器(Interceptors)。
注意:嵌入代理依赖hadoop-core.jar。
嵌入代理和完整代理在配置上是相似的。下面是配置项目的详细列表:
加粗的是必选项。
| Property Name | Default | Description |
|---|---|---|
| source.type | embedded | The only available source is the embedded source. |
| channel.type | – | Either memory or file which correspond to MemoryChannel and FileChannel respectively. |
| channel.* | – | Configuration options for the channel type requested, see MemoryChannel or FileChannel user guide for an exhaustive list. |
| sinks | – | List of sink names |
| sink.type | – | Property name must match a name in the list of sinks. Value must be avro |
| sink.* | – | Configuration options for the sink. See AvroSink user guide for an exhaustive list, however note AvroSink requires at least hostname and port. |
| processor.type | – | Either failover or load_balance which correspond to FailoverSinksProcessor and LoadBalancingSinkProcessor respectively. |
| processor.* | – | Configuration options for the sink processor selected. See FailoverSinksProcessor and LoadBalancingSinkProcessor user guide for an exhaustive list. |
| source.interceptors | – | Space-separated list of interceptors |
| source.interceptors.* | – | Configuration options for individual interceptors specified in the source.interceptors property |
Transaction接口
Transaction接口是Flume可靠性的基础。所有主要的组件(也就是Sources、Sinks和Channels)必须使用一个FlumeTransaction。
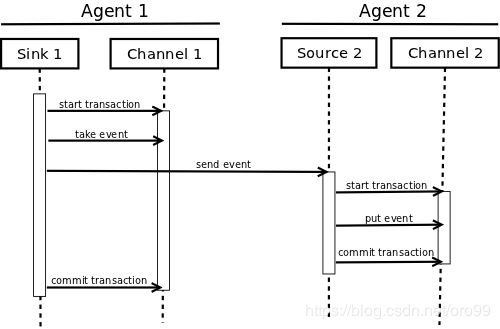
Transaction在Channels的实现类中进行实现。每个连接到Channel的Source和Sink必须获得Transaction对象。Sources使用ChannelProcessor来管理Transactions,Sinks通过其配置的Channel显式管理他们。将事件(将其放入Channel)或提取事件(将其从Channel中取出)的操作在活动事务内部完成。例如:
Channel ch = new MemoryChannel();
Transaction txn = ch.getTransaction();
txn.begin();
try {
// This try clause includes whatever Channel operations you want to do
Event eventToStage = EventBuilder.withBody("Hello Flume!",
Charset.forName("UTF-8"));
ch.put(eventToStage);
// Event takenEvent = ch.take();
// ...
txn.commit();
} catch (Throwable t) {
txn.rollback();
// Log exception, handle individual exceptions as needed
// re-throw all Errors
if (t instanceof Error) {
throw (Error)t;
}
} finally {
txn.close();
}这里我们从Channel中获取Transaction。在begin() 返回后,Transaction(状态)就成为active/open,然后Event放入Channel中。如果放入成功了,然后Transaction进行提交和关闭。
Sink
Sink的目标就是从Channel中抽取Events并把他们推给下一个Flume代理或是把他们保存到外部存储上。根据Flume属性的配置文件,Sink只与一个Channels关联。每个已配置的Sink都有一个SinkRunner实例,当Flume框架调用SinkRunner.start()时,会创建一个新线程来驱动Sink(使用SinkRunner.PollingRunner作为线程的Runnable)。这个线程管理Sink的生命周期。Sink需要实现作为LifecycleAware接口一部分的start()和stop()方法。Sink.start()方法应初始化Sink并将其置于可将事件转发到其下一个目标的状态。Sink.process()方法应该执行从Channel提取Event并转发它的核心处理。Sink.stop()方法应该做必要的清理工作(比如释放资源)。Sink的实现类也需要实现Configurable接口来处理自己的配置设置。例如:
public class MySink extends AbstractSink implements Configurable {
private String myProp;
@Override
public void configure(Context context) {
String myProp = context.getString("myProp", "defaultValue");
// Process the myProp value (e.g. validation)
// Store myProp for later retrieval by process() method
this.myProp = myProp;
}
@Override
public void start() {
// Initialize the connection to the external repository (e.g. HDFS) that
// this Sink will forward Events to ..
}
@Override
public void stop () {
// Disconnect from the external respository and do any
// additional cleanup (e.g. releasing resources or nulling-out
// field values) ..
}
@Override
public Status process() throws EventDeliveryException {
Status status = null;
// Start transaction
Channel ch = getChannel();
Transaction txn = ch.getTransaction();
txn.begin();
try {
// This try clause includes whatever Channel operations you want to do
Event event = ch.take();
// Send the Event to the external repository.
// storeSomeData(e);
txn.commit();
status = Status.READY;
} catch (Throwable t) {
txn.rollback();
// Log exception, handle individual exceptions as needed
status = Status.BACKOFF;
// re-throw all Errors
if (t instanceof Error) {
throw (Error)t;
}
}
return status;
}
}Source
Source的目的就是从外部客户端中接收数据,并将数据保存到配置的Channel中。Source能够获取其自己的ChannelProcessor实例来串行的处理提交到Channel本地事务里的Event。在异常的情况下,所需的Channels将传播异常,所有Channels将回滚其事务,但先前在其他Channel上处理的事件将保持提交。
和SinkRunner.PollingRunner Runnable,当Flume框架调用PollableSourceRunner.start()时,PollingRunner Runnable会在创建的线程上执行。每个配置的PollableSource都有其自己的线程运行PollingRunner。这个线程管理PollableSource的生命周期,如开始和停止。PollableSource的实现类必须实现在LifecycleAware接口中定义的start()和stop()方法。PollableSource的运行器调用Source的process()方法。该方法应该能检查新数据,并能把它们以Flume Events的格式保存到Channel中。
请注意,实际上有两种类型的Sources。PollableSource已经提及。和PollableSource不一样,EventDrivenSource必须有他自己的回调机制,以捕获新的数据并保存到Channel中。EventDrivenSources并不像PollableSources那样由它们自己的线程驱动。下面是自定义一个PollableSource的示例:
public class MySource extends AbstractSource implements Configurable, PollableSource {
private String myProp;
@Override
public void configure(Context context) {
String myProp = context.getString("myProp", "defaultValue");
// Process the myProp value (e.g. validation, convert to another type, ...)
// Store myProp for later retrieval by process() method
this.myProp = myProp;
}
@Override
public void start() {
// Initialize the connection to the external client
}
@Override
public void stop () {
// Disconnect from external client and do any additional cleanup
// (e.g. releasing resources or nulling-out field values) ..
}
@Override
public Status process() throws EventDeliveryException {
Status status = null;
try {
// This try clause includes whatever Channel/Event operations you want to do
// Receive new data
Event e = getSomeData();
// Store the Event into this Source's associated Channel(s)
getChannelProcessor().processEvent(e);
status = Status.READY;
} catch (Throwable t) {
// Log exception, handle individual exceptions as needed
status = Status.BACKOFF;
// re-throw all Errors
if (t instanceof Error) {
throw (Error)t;
}
} finally {
txn.close();
}
return status;
}
}