0 前言
在平时的开发过程中大部分人应该都遇到过中文乱码问题,浏览网页时也会遇到内容显示乱码的情况,一般遇到这种情况我们想到的可能是编码问题。那我们说的编码具体是指什么,乱码问题的根本原因是什么,又该如何解决呢?
答案的关键就是本文接下来要介绍的字符集与字符编码。
1 概述
首先介绍一下字符,字节,字符串,字符集和字符编码等基本概念。
- 字符(Character): 各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
- 字节(Byte): 计算机信息技术用于计量存储容量的一种计量单位,也表示一些计算机编程语言中的数据类型和语言字符。
- 字符串(string): 一个连续的字符序列,在存储上类似于字符数组。
- 字符集(Character Set): 多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同。
- 字符编码(Character encoding): 也称字集码,是把字符集中的字符编码为指定集合中某一对象(例如:比特模式、自然数序列、8位组或者电脉冲),以便文本在计算机中存储和通过通信网络的传递。
- 单字节字符集(Single Byte Character Set, SBCS): 所有字符都只用一个字节表示。用一个字节表示的0来标志SBCS字符串的结束。
- 多字节字符集(Multi-Byte Character Set, MBCS):部分字符用一个字节表示,部分字符用两个或更多字节表示。Windows中的MBCS包含两种字符,单字节字符(Single-Byte Characters)和双字节字符(Double-Byte Characters)。有一些特定的值被保留用来表明它们是双字节字符的一部分。MBCS字符串也使用单字节的0来标志字符串结束。
- Unicode字符集: 通常又称为宽字符集(Wide Character Set),所有字符都用两个字节来表示。 注意,不要混淆Unicode字符集与MBCS,Unicode字符串采用两个字节表示的0作为结束标志。
常见的字符集有:ASCII字符集、GB2312字符集、GBK字符集、Big5字符集、GB18030字符集、Unicode字符集等。
一般情况下一个字符集对应一种字符编码,但是Unicode比较特殊,存在多种字符编码标准,比如:UTF-7,UTF-8,UTF-16,UTF-32等。
根据各个字符集的特性及发展历程可以将其划分成三类,如下图所示:
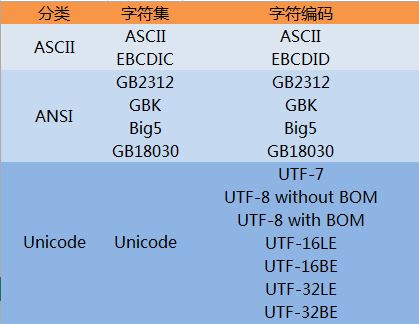
上图中只列举了几种常见的字符集与字符编码,更多内容请参阅字符编码。
注意: 平时与人沟通的时候要弄清楚自己说的是字符集还是字符编码,尤其是在谈论Unicode的时候。
2 ASCII
- ASCII(American Standard Code for Information Interchange,美国信息互换标准编码)是基于罗马字母表的一套电脑编码系统。
- 包含了英文大小写字符、阿拉伯数字和西文符号等可显示字符以及回车键、退格、换行键等控制字符。
- 主要用于显示现代英语和其他西欧语言,是现今最通用的单字节编码系统,并等同于国际标准ISO 646。
- 基本字符集采用7位(bits)表示一个字符,共128个字符,字符值从0到127,其中32到126是可打印字符。
- 扩展字符集采用8位(bits)表示一个字符,共256个字符,增加了表格符号、计算符号、希腊字母和特殊的拉丁符号,可以表示更多的欧洲常用字符。
3 ANSI(GB2312, GBK, Big5, GB18030)
随着计算机的不断普及,原来的ASCII单字节编码已经无法满足世界各地的字符表示要求,于是,各个国家和地区都设计了一系列满足于本国和地区的字符集与字符编码。
以中国为例,为了满足国内计算机使用汉字的需求,中国国家标准总局发布了一系列的汉字字符集国家标准编码,统称为GB码,或国标码。
3.1 GB2312
GB2312是一个简体中文字符集,采用了二维矩阵编码法对所有字符进行编码:
- 首先构造一个94行94列的方阵,对每一行称为一个“区”,每一列称为一个“位”,
- 然后将所有字符依照下表的规律填写到方阵中。
| 分区范围 | 符号类型 |
|---|---|
| 第01区 | 中文标点、数学符号以及一些特殊字符 |
| 第02区 | 各种各样的数学序号 |
| 第03区 | 全角西文字符 |
| 第04区 | 日文平假名 |
| 第05区 | 日文片假名 |
| 第06区 | 希腊字母表 |
| 第07区 | 俄文字母表 |
| 第08区 | 中文拼音字母表 |
| 第09区 | 制表符号 |
| 第10-15区 | 无字符 |
| 第16-55区 | 一级汉字(以拼音字母排序) |
| 第56-87区 | 二级汉字(以部首笔画排序) |
| 第88-94区 | 无字符 |
这样所有的字符在方阵中都有一个唯一的位置,这个位置可以用区号、位号合成表示,称为字符的区位码。
GB2312编码采用两个字节表示一个汉字,区码和位码分别占用一个字节。由于区码和位码的取值范围都是在1-94之间,同西文的存储表示冲突。为了与西文进行区别,存储时将区位码的每个字节分别加上A0H(160)转换为存储码。以汉字“啊”为例,区位码为1601(1001H),存储码为B0A1H,转换过程如下:
| 区位码 | 区码转换 | 位码转换 | 存储码 |
|---|---|---|---|
| 1001H | 10H+A0H=B0H | 01H+A0H=A1H | B0A1H |
3.2 GBK
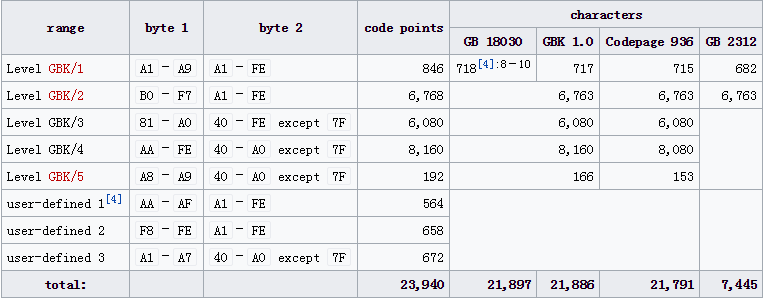
- GBK是GB2312的扩展,K为扩展的汉语拼音中“扩”字的声母。英文全称Chinese Internal Code Specification。
- 字符有一字节和双字节编码,00–7F范围内是第一个字节,和ASCII保持一致,此范围内严格上说有96个文字和32个控制符号。
- 之后的双字节中,前一字节是双字节的第一位。总体上说第一字节的范围是81–FE(也就是不含80和FF),第二字节的一部分领域在40–7E,其他领域在80–FE。编码范围如下所示:
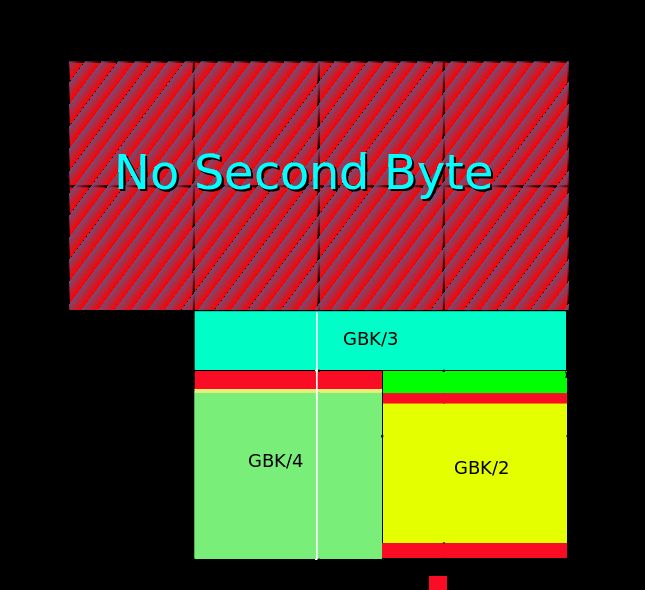
- 双字节符号可以表达的64K空间如下图所示。绿色和黄色区域是GBK的编码,红色是用户定义区域。没有颜色区域是不正确的代码组合。
3.3 Big5
- Big5又称为大五码或五大码,是一种繁体字编码,主要在台湾,香港和澳门等使用繁体字的地区使用。
- Big5采用双字节表示一个字符,第一个字节称为“高位字节”,第二个字节称为“低位字节”。
- “高位字节”范围0x81-0xFE,“低位字节”范围0x40-0x7E,及0xA1-0xFE。具体分区如下所示:
| 分区 | 备注 |
|---|---|
| 0x8140-0xA0FE | 保留给用户自定义字符(造字区) |
| 0xA140-0xA3BF | 标点符号、希腊字母及特殊符号,包括在0xA259-0xA261,安放了九个计量用汉字:兙兛兞兝兡兣嗧瓩糎。 |
| 0xA3C0-0xA3FE | 预留。此区没有开放作造字区用。 |
| 0xA440-0xC67E | 常用汉字,先按笔划再按部首排序。 |
| 0xC6A1-0xC8FE | 保留给用户自定义字符(造字区) |
| 0xC940-0xF9D5 | 次常用汉字,亦是先按笔划再按部首排序。 |
| 0xF9D6-0xFEFE | 保留给用户自定义字符(造字区) |
3.4 GB18030
GB18030是我国目前最新的变长多字节字符集,兼容GB2312,GBK以及Unicode3.1。主要特点如下:
- 采用变长多字节编码,每个字可以由1个、2个或4个字节组成。
- 编码空间庞大,最多可定义161万个字符。
- 支持中国国内少数民族文字,不需要动用造字区。
- 汉字收录范围包含繁体汉字以及日韩汉字。
GB18030包含三种长度的编码:单字节的ASCII、双字节的GBK(略带扩展)、以及用于填补所有Unicode码位的四字节UTF区段。编码范围如下图所示:

3.5 Unicode
不同的国家和地区制定了适用于本国和地区的字符表示标准,但是这些标准之间往往是不兼容的,比如用GB18030编码的文件通过阿拉伯文的编码标准去解析,肯定是显示一堆乱码。同时,随着计算机科学和互联网的不断发展,软件国际化逐渐成为了必然的趋势。在此背景下,一种包含了世界各地绝大部分文字字符的通用字符集就应运而生了-Unicode字符集。
Unicode字符集是通用多八位编码字符集(Universal Multiple-Octet Coded Character Set)的简称。它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
下面简单梳理一下Unicode的编码方式与实现方式的相关知识。
3.5.1 编码方式
Unicode存在两种编码方式,分别是UCS-2和UCS-4。
- UCS-2: 采用两个字节编码,理论上最多可以表示216(65536)个字符。
- UCS-4: 采用四个字节编码,理论上最多可以表示232(2147483648)个字符,完全可以涵盖所有语言的字符。
- UCS-4根据最高位为0的最高字节分成2^7=128个group。
- 每个group再根据次高字节分为256个plane。
- 每个plane根据第3个字节分为256行 (rows),每行包含256个cells。
- group 0的plane 0被称作Basic Multilingual Plane, 即BMP。
将UCS-4的BMP去掉前面的两个零字节就得到了UCS-2。在UCS-2的两个字节前加上两个零字节,就得到了UCS-4的BMP。而目前的UCS-4规范中还没有任何字符被分配在BMP之外。
3.5.2 实现方式
Unicode的实现方式不同于编码方式。一个字符的Unicode编码是确定的。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF)。
常见的实现方式有UTF-8,UTF-16,UTF-32等。
- UTF-8: 以8bits(1字节)为单位对UCS进行编码,可以用1到4个字节来表示一个字符,是一种字节变长度编码方式。
- UTF-16: 以16bits(2字节)为单位对UCS进行编码,可以用2字节或4字节来表示一个字符,是一种字节变长度编码方式。
- UTF-32: 以32bits(4字节)为单位对UCS进行编码,用4字节来表示一个字符,是一种字节固定长度编码方式。
UCS-2和UCS-4是编码方案,而UTF-x是编码实现方式,涉及到实际传输,所以需要考虑字节序问题。
字节序(Byte Order Mark,BOM): 用于表示字节传输过程中的存储方式,常见的实现方式及对应BOM如下所示:
| UTF | BOM |
|---|---|
| UTF-8 | EF BB BF |
| UTF-16LE | FF FE |
| UTF-16BE | FE FF |
| UTF-32LE | FF FE 00 00 |
| UTF-32BE | 00 00 FE FF |
LE表示小端字节序,BE表示大端字节序。
3.5.3 UTF-8
由于UTF-16和UTF-32都存在空间浪费的情况,而UTF-8采用字节为单位的变长编码方式,大大提高了空间利用率,因此,UTF-8也是我们平时用的最多的编码方式。
UTF-8的编码规则有两条:
- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
- 对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
下表总结了编码规则,字母x表示可用编码的位。
| Unicode符号范围(十六进制) | UTF-8编码方式(二进制) |
|---|---|
| 0000 0000-0000 007F | 0xxxxxxx |
| 0000 0080-0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
4 字符编码的应用
字符集与字符编码相关的知识非常多,上面只是简单介绍了一些常见的字符集以及字符编码。想要了解更多的知识可以点击相关概念的链接进行深入研究。
接下来介绍一下平时开发中会涉及到编码相关的一些知识点。
4.1 代码页
代码页是字符集编码的别名,最早是IBM公司首先使用。可以将代码页理解为字符和字节数据的映射表。
Windows中将支持的代码页用一个编号来表示。例如代码页936就是简体中文GBK。
可以在DOS的CMD命令行下通过chcp命令进行查看和修改系统的代码页。
# 查看代码页
C:\>chcp
活动代码页: 936
4.2 区域(Locale)设置
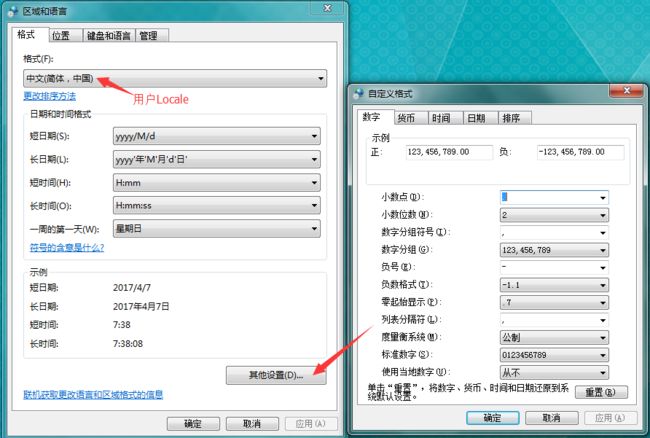
Microsoft为了适应世界各地的文化背景和使用习惯,在Winodows系统中设计了区域设置的功能。可以通过控制面板->区域与语言选项进行系统Locale和用户Locale设置,其中系统Locale决定代码页;用户Locale决定数字、货币、时间和日期格式。设置界面如下图所示:
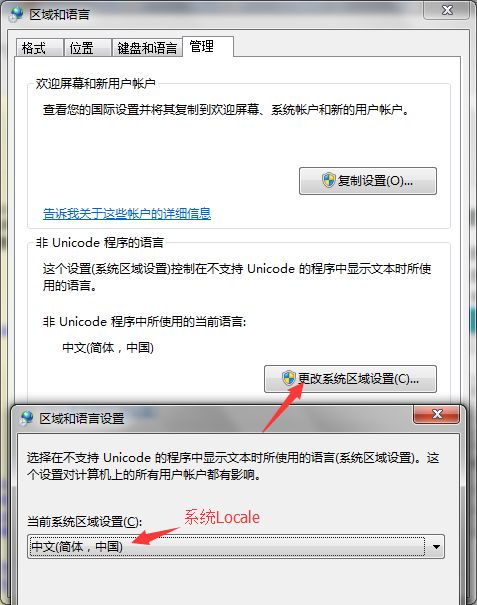
C++中有两种方式可以设置区域信息,如下:
- 通过setlocale函数在运行时设置区域信息。
- 通过#pragrma setlocale编译指定来设置区域信息,该指令在编译时起作用。
4.3 VS中字符集设置
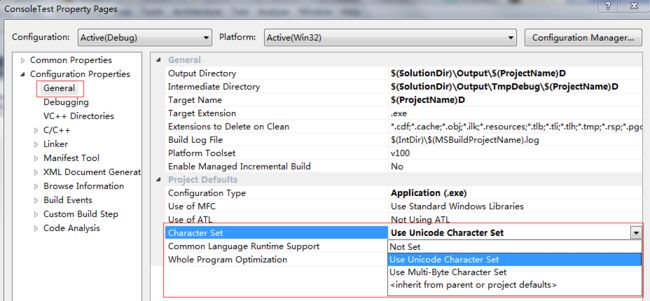
为了方便代码的移植和统一,目前的开发环境一般都会采用Uincode字符集,在VS中可以通过Project->Properties->Configuration Properities->General->Character Set进行设置,如下图所示:
4.4 C++中字符和字符串的相关知识
C++的新标准中引入了UTF-16和UTF-32编码方式的字符,分别用小写字母u和大写字母U开头来表示,同时也引入了更多的字符串类型与操作,直接看下MSDN提供的代码示例:
#include
using namespace std::string_literals; // enables s-suffix for std::string literals
int main()
{
// Character literals
auto c0 = 'A'; // char
auto c1 = u8'A'; // char
auto c2 = L'A'; // wchar_t
auto c3 = u'A'; // char16_t
auto c4 = U'A'; // char32_t
// String literals
auto s0 = "hello"; // const char*
auto s1 = u8"hello"; // const char*, encoded as UTF-8
auto s2 = L"hello"; // const wchar_t*
auto s3 = u"hello"; // const char16_t*, encoded as UTF-16
auto s4 = U"hello"; // const char32_t*, encoded as UTF-32
// Raw string literals containing unescaped \ and "
auto R0 = R"("Hello \ world")"; // const char*
auto R1 = u8R"("Hello \ world")"; // const char*, encoded as UTF-8
auto R2 = LR"("Hello \ world")"; // const wchar_t*
auto R3 = uR"("Hello \ world")"; // const char16_t*, encoded as UTF-16
auto R4 = UR"("Hello \ world")"; // const char32_t*, encoded as UTF-32
// Combining string literals with standard s-suffix
auto S0 = "hello"s; // std::string
auto S1 = u8"hello"s; // std::string
auto S2 = L"hello"s; // std::wstring
auto S3 = u"hello"s; // std::u16string
auto S4 = U"hello"s; // std::u32string
// Combining raw string literals with standard s-suffix
auto S5 = R"("Hello \ world")"s; // std::string from a raw const char*
auto S6 = u8R"("Hello \ world")"s; // std::string from a raw const char*, encoded as UTF-8
auto S7 = LR"("Hello \ world")"s; // std::wstring from a raw const wchar_t*
auto S8 = uR"("Hello \ world")"s; // std::u16string from a raw const char16_t*, encoded as UTF-16
auto S9 = UR"("Hello \ world")"s; // std::u32string from a raw const char32_t*, encoded as UTF-32
}
4.5 ANSI字符串与Unicode字符串相互转换
Windows提供了一些列的API函数来操作字符串,包括获取字符集信息,判断是否是DBCS的起始字节以及ANSI字符串与Unicode字符串之间相互转换等。用的比较多的应该就是字符串转换的API了,如下所示:
- MultiByteToWideChar: ANSI字符串转换成Unicode字符串。
- WideCharToMultiByte: Unicode字符串转换成ANSI字符串。
ANSI字符串又称为多字节字符串,Unicode字符串又称为宽字节字符串。每个人的叫法习惯不同,知道对应的关系即可。
为了操作简单,ATL提供了几个宏用于字符串转换,底层实现都是通过上述介绍的MultiByteToWideChar和WideCharToMultiByte两个API。
平时用的最多的就是CA2T和CT2A,这两个宏中各个字母代表的含义如下所示:
| 字母 | 含义 |
|---|---|
| C | 目标类型必须是Const类型 |
| A | ANSI字符串 |
| W | Unicode字符串 |
| T | 通用字符串,当定义了_UNICODE宏时T表示W,否则T表示A |
使用这两个宏的时候需要注意几点:
- 作用域问题:CA2T和CT2A的转换后的数据作用域只在当前行,即在下一行代码中再去访问转换后的数据会出现不可预知的问题。如下代码所示:
// 正确,Fun函数使用转换后的TCHAR
Fun(CA2T(szSrc, CP_UTF8));
// 正确,转换后的数据赋值给strDes
CString strDes = CA2T(szSrc, CP_UTF8);
// 错误,转换后的数据在下一行被释放,即szDes指向的数据变成未知
TCHAR *szDes = CA2T(szSrc, CP_UTF8);
- 参数问题: 转换过程中可以指定code page信息,下面是摘之winnls.h对应参数的描述:
// Code Page Default Values.
#define CP_ACP 0 // default to ANSI code page
#define CP_OEMCP 1 // default to OEM code page
#define CP_MACCP 2 // default to MAC code page
#define CP_THREAD_ACP 3 // current thread's ANSI code page
#define CP_SYMBOL 42 // SYMBOL translations
#define CP_UTF7 65000 // UTF-7 translation
#define CP_UTF8 65001 // UTF-8 translation
下面以CA2T为例,我们来看下底层实现是如何运用这些参数的。
// 1. CA2T其实转化为CA2W
#define CA2T CA2W
// 2. CA2W又是通过模板CA2WEX来实现
typedef CA2WEX<> CA2W;
// 3. 下面是CA2WEX<>的模板实现:
template< int t_nBufferLength = 128 >
class CW2AEX
{
public:
CW2AEX(_In_z_ LPCWSTR psz) throw(...)
:m_psz( m_szBuffer )
{
Init( psz, _AtlGetConversionACP() );
}
CW2AEX(_In_z_ LPCWSTR psz, _In_ UINT nCodePage) throw(...)
:m_psz( m_szBuffer )
{
Init( psz, nCodePage );
}
~CW2AEX() throw()
{
AtlConvFreeMemory(m_psz,m_szBuffer,t_nBufferLength);
}
_Ret_z_ operator LPSTR() const throw()
{
return( m_psz );
}
private:
void Init(_In_z_ LPCWSTR psz, _In_ UINT nConvertCodePage) throw(...)
{
if (psz == NULL)
{
m_psz = NULL;
return;
}
int nLengthW = lstrlenW( psz )+1;
int nLengthA = nLengthW*4;
AtlConvAllocMemory(&m_psz,nLengthA,m_szBuffer,t_nBufferLength);
BOOL bFailed=(0 == ::WideCharToMultiByte( nConvertCodePage, 0, psz, nLengthW, m_psz, nLengthA, NULL, NULL ));
if (bFailed)
{
if (GetLastError()==ERROR_INSUFFICIENT_BUFFER)
{
nLengthA = ::WideCharToMultiByte( nConvertCodePage, 0, psz, nLengthW, NULL, 0, NULL, NULL );
AtlConvAllocMemory(&m_psz,nLengthA,m_szBuffer,t_nBufferLength);
bFailed=(0 == ::WideCharToMultiByte( nConvertCodePage, 0, psz, nLengthW, m_psz, nLengthA, NULL, NULL ));
}
}
if (bFailed)
{
AtlThrowLastWin32();
}
}
public:
LPSTR m_psz;
char m_szBuffer[t_nBufferLength];
private:
CW2AEX(_In_ const CW2AEX&) throw();
CW2AEX& operator=(_In_ const CW2AEX&) throw();
};
inline UINT WINAPI _AtlGetConversionACP() throw()
{
#ifdef _CONVERSION_DONT_USE_THREAD_LOCALE
return CP_ACP;
#else
return CP_THREAD_ACP;
#endif
}
- 从上述的代码逻辑中可以看出,当没有指定转换代码页的时候默认通过_AtlGetConversionACP函数来获取转换参数。
- 注意区别CP_ACP和CP_THREAD_ACP,大多数情况下这两者对应的代码页是一样的,都是系统当前的代码页,但是如果程序在运行时指定了其它的代码页则会出现不一致的情况。
- CP_ACP代表的是系统当前的代码页,但是不同系统中当前的代码页可能是不一样的,例如A电脑设置的是936(简体中文),B电脑设置的是950(繁体中文),此时将一个简体中文字符串进行转换时在A电脑上可以成功,但是在B电脑上就出现了乱码情况。因此,建议采用CP_UTF8参数对字符串进行转换,降低出现乱码的概率。
更多详细内容请参阅ATL and MFC String Conversion Macros。
5 总结
字符集和字符编码相关的知识非常多,本文主要梳理总结了一些常用的、比较核心的概念,希望对大家有所帮助。
整理这篇文章的过程中查看了非常多的资料,主要是维基百科和MSDN文档,大部分可以通过文中超链接跳转过去,还有一些博客对字符编码的介绍,下面列举一些个人觉得总结的不错的文章作为补充阅读。
- 谈谈Unicode编码,简要解释UCS、UTF、BMP、BOM等名词
- 浅谈文字编码和Unicode(上)
- 浅谈文字编码和Unicode(下)