【树】分类树、回归树原理及代码
1.分类树 (Classification Tree)
原理:
内部节点表示一个特征或者一个属性,叶子节点表示一个类。
用决策树分类,从根节点开始,对实例的某一个特征进行分类,根据分类结果,将实例分配到子节点,这时,每一个子节点对应着该特征的一个取值;如此递归的分配下去,直到将该实例分配到叶子节点。
以C4.5分类树为例,C4.5分类树在每次分枝时,是穷举每一个feature的每一个阈值,找到使得按照feature<=阈值,和feature>阈值分成的两个分枝的熵最大的阈值(熵最大的概念可理解成尽可能每个分枝的男女比例都远离1:1),按照该标准分枝得到两个新节点,用同样方法继续分枝直到所有人都被分入性别唯一的叶子节点,或达到预设的终止条件,若最终叶子节点中的性别不唯一,则以多数人的性别作为该叶子节点的类别[1]。
需要补充:熵,信息增益,基尼指数[4]。
熵:是随机变量不确定性的度量,熵越大,随机变量的不确定性越大,换句话说,预测具有该变量的样本为正例的概率为0.5,等同随机猜。
信息增益:越大,该特征具备更强的分类能力。
基尼指数:越大,样本集合的不确定越大。
总结:分类树使用信息增益或增益比率来划分节点;每个节点样本的类别情况投票决定测试样本的类别。
code:
http://sklearn.apachecn.org/#/docs/11
#简单例子训练模型
from sklearn import tree
x = [[0,0],[1,1]]
y = [0,1]
clf = tree.DecisionTreeClassifier()
clf = clf.fit(x,y)
#预测例子
z = [[2,2]]
#预测标签
clf.predict(z) #out:array([1])
#预测属于每个类的概率
# clf.predict_proba(z) #out:array([[0., 1.]])
c = [[0,1]]
clf.predict_proba(c)# 出现这样一个现象:array([[0., 1.]]) 再运行一次array([[1., 0.]]),说明我们训练的模型,预测能力正负例子的能力50%,跟掷硬币似的。# iris 数据集上训练模型
from sklearn.datasets import load_iris
from sklearn import tree
iris = load_iris()
clf = tree.DecisionTreeClassifier()
clf = clf.fit(iris.data, iris.target)
import graphviz #用来绘制树形状的模块
dot_data = tree.export_graphviz(clf,out_file=None)
graph = graphviz.Source(dot_data)
graph.render("iris")
graph # 打印出数的形状,分裂的特征的gini指数输出的树结果:对输出结果,做一些说明:
X[3]<=0.8 :X[3]表示样本中的第四个特征,0.8表示该特征的切分点;
gini=0.667:这是X[3]<=0.8时候的gini指数;
samples=150:这是总体的样本个数;
values=[50,50,50]:我的理解是每一个元素表示三类样本的数量。
[4]中说,gini指数最小的特征,以及其对应的切分点作为最优特征和切分点。这里跟代码跑出来的结果不同啊,甚是不理解为啥。。

2.回归树(Regression Tree)
回归树总体流程也是类似,区别在于,回归树的每个节点(不一定是叶子节点)都会得一个预测值,以年龄为例,该预测值等于属于这个节点的所有人年龄的平均值。分枝时穷举每一个feature的每个阈值找最好的分割点,但衡量最好的标准不再是最大熵,而是最小化均方差即(每个人的年龄-预测年龄)^2 的总和 / N。也就是被预测出错的人数越多,错的越离谱,均方差就越大,通过最小化均方差能够找到最可靠的分枝依据。分枝直到每个叶子节点上人的年龄都唯一或者达到预设的终止条件(如叶子个数上限),若最终叶子节点上人的年龄不唯一,则以该节点上所有人的平均年龄做为该叶子节点的预测年龄。
总结:回归树使用最大均方差划分节点;每个节点样本的均值作为测试样本的回归预测值[1]。
节点的预测值是该节点下所有点的均值,这点在李航老师的《统计及旗下学习》中有体现:

code:
#https://scikit-learn.org/stable/auto_examples/tree/plot_tree_regression.html#sphx-glr-auto-examples-tree-plot-tree-regression-py
#随机生成数据,拟合曲线,并绘制数据的散点图
print(__doc__)
import numpy as np
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as plt
rng = np.random.RandomState(1)
X = np.sort(5*rng.rand(80,1),axis = 0)
y = np.sin(X).ravel()
y[::5] += 3 * (0.5 - rng.rand(16))
# Fit regression model
regr_1 = DecisionTreeRegressor(max_depth=2)
regr_2 = DecisionTreeRegressor(max_depth=5)
regr_1.fit(X, y)
regr_2.fit(X, y)
# Predict
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
y_1 = regr_1.predict(X_test)
y_2 = regr_2.predict(X_test)
# Plot the results
plt.figure()
plt.scatter(X, y, s=20, edgecolor="black",
c="darkorange", label="data")
plt.plot(X_test, y_1, color="cornflowerblue",
label="max_depth=2", linewidth=2)
plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()输出结果:
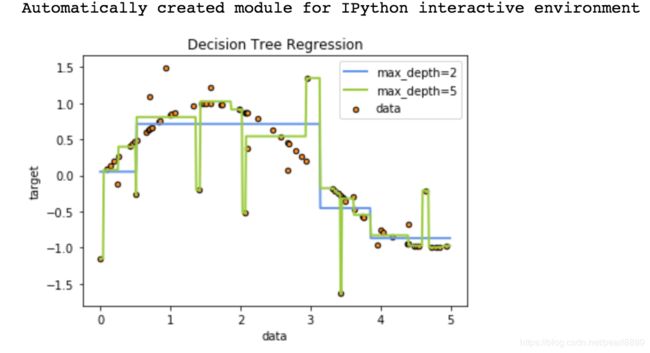
附件:
sklearn中iris介绍:
1.可以参考[6]绘制样本分布图:
部分树参数说明:
> * 使用 max_depth=3 作为初始树深度,让决策树知道如何适应您的数据,然后再增加树的深度。
> * 请记住,填充树的样本数量会增加树的每个附加级别。使用 max_depth 来控制输的大小防止过拟合。
> * 通过使用 min_samples_split 和 min_samples_leaf 来控制叶节点上的样本数量。当这个值很小时意味着生成的决策树将会过拟合,然而当这个值很大时将会不利于决策树的对样本的学习。所以尝试 min_samples_leaf=5 作为初始值。如果样本的变化量很大,可以使用浮点数作为这两个参数中的百分比。两者之间的主要区别在于 min_samples_leaf 保证叶结点中最少的采样数,而 min_samples_split 可以创建任意小的叶子,尽管在文献中 min_samples_split 更常见。
> * 在训练之前平衡您的数据集,以防止决策树偏向于主导类.可以通过从每个类中抽取相等数量的样本来进行类平衡,或者优选地通过将每个类的样本权重 (sample_weight) 的和归一化为相同的值。还要注意的是,基于权重的预修剪标准 (min_weight_fraction_leaf) 对于显性类别的偏倚偏小,而不是不了解样本权重的标准,如 min_samples_leaf 。
参考:
1.https://blog.csdn.net/puqutogether/article/details/44593647
2.https://www.jianshu.com/p/005a4e6ac775
3.https://blog.csdn.net/suranxu007/article/details/49910323
4.《统计机器学习》,李航。
5.https://scikit-learn.org/stable/auto_examples/tree/plot_iris.html#sphx-glr-auto-examples-tree-plot-iris-py
6.数据集合介绍http://www.cnblogs.com/Belter/p/8831216.html