实战LeNet-5 AlexNet ResNet 实践 Cifar-10问题
一、Cifar-10的说明
cifar10是一个32*32 的图像10分类问题,一共有60000张图片,我们拿50000张做训练数据,另外拿2000张做测试数据。

为了学习不同网络,这里统一拿这个用作实验材料,关于下载cifar10,或更多说明可以查看官网CIFAR-10
二、LeNet5模型

如图所示这个模型就是2个卷积、池化,再连3个全连接
第一个卷积层6个大小为5*5卷积核,第二卷积层为16个5*5卷积核,其他的都比较简单
def build_model_lenet5():
model = PowerCNNMode('cifar10_lenet5', is_debug=True)
model.set_input_placeholder([None, IMAGE_SIZE, IMAGE_SIZE, 3], [None, 10])
model.set_is_train()
model.set_dropout()
mode_config = [{'t': 'conv2d', 'x': 5, 'y': 5, 'n': 6, 's': 1, 'a': tf.nn.relu},
{'t': 'max_pool', 'k': 2, 's': 2},
{'t': 'dropout'},
{'t': 'conv2d', 'x': 5, 'y': 5, 'n': 16, 's': 1, 'a': tf.nn.relu},
{'t': 'max_pool', 'k': 2, 's': 2},
{'t': 'dropout'},
{'t': 'flatten'},
{'t': 'dense', 'u': 120, 'a': tf.nn.relu},
{'t': 'dropout'},
{'t': 'dense', 'u': 84, 'a': tf.nn.relu},
{'t': 'dense', 'u': 10, 'a': tf.nn.softmax},
]
model.inference(mode_config)
model.set_loss()
model.set_adamoptimizer(1e-4)
model.set_accuracy()
return model我训练了100轮,可以达到66%

三、AlexNet模型

ps:这个模型及后面的resnet原始模型都是处理imagenet那种大数据库的,cifar10图片尺寸相对比较小,所以这里都做适当的简化
这个介绍下这个模型的几个特点:
1、激活函数全部都使用ReLU(Rectified Linear Unit)

如图它关闭了右边,从而会使得很多的隐层输出为0,即网络变得稀疏,起到了类似L1的正则化作用,可以在一定程度上缓解过拟合。本质上是分段线性模型,前向计算非常简单,无需指数之类操作,Tanh和Logistic激活函数在两端的时候导数容易趋近于零,多级连乘后梯度更加约等于0,相比下它更不容易发生梯度发散问题
2、局部响应归一化LRN(Local Response Normalization)
原理是仿造生物学上活跃的神经元对相邻神经元的抑制现象(侧抑制)
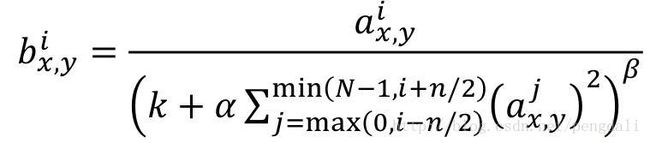
i表示第i个核在位置(x,y)运用激活函数ReLU后的输出,n是同一位置上临近的kernal map的数目,N是kernal的总数。参数K,n,alpha,belta都是超参数,我这里是这么设置的
tf.nn.lrn(in_data, depth_radius=4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name=name)3、防止过拟合使用dropout
dropout是以配置的概率将隐层神经元的输出设置为零。以这种方式“dropped out”的神经元既不参与前向传播,也不参与反向传播。所以每次提出一个输入,该神经网络就尝试一个不同的结构,但是所有这些结构之间共享权重。因为神经元不能依赖于其他特定神经元而存在,所以这种技术降低了神经元复杂的互适应关系.
ps:其他的特性比如双GPU、对数据做预处理这里没有实践
4、实验模型代码
def build_model_alexnet():
model = PowerCNNMode('cifar10_alexnet', is_debug=True)
model.set_input_placeholder([None, IMAGE_SIZE, IMAGE_SIZE, 3], [None, 10])
model.set_is_train()
model.set_dropout()
mode_config = [{'t': 'conv2d', 'x': 3, 'y': 3, 'n': 32, 's': 1, 'a': tf.nn.relu},
{'t': 'lrn'},
{'t': 'max_pool', 'k': 2, 's': 2},
{'t': 'dropout'},
{'t': 'conv2d', 'x': 3, 'y': 3, 'n': 64, 's': 1, 'a': tf.nn.relu},
{'t': 'lrn'},
{'t': 'max_pool', 'k': 2, 's': 2},
{'t': 'dropout'},
{'t': 'conv2d', 'x': 3, 'y': 3, 'n': 64, 's': 1, 'a': tf.nn.relu},
{'t': 'dropout'},
{'t': 'conv2d', 'x': 3, 'y': 3, 'n': 128, 's': 1, 'a': tf.nn.relu},
{'t': 'dropout'},
{'t': 'conv2d', 'x': 3, 'y': 3, 'n': 256, 's': 1, 'a': tf.nn.relu},
{'t': 'max_pool', 'k': 2, 's': 2},
{'t': 'flatten'},
{'t': 'dense', 'u': 1024, 'a': tf.nn.relu},
{'t': 'dropout'},
{'t': 'dense', 'u': 1024, 'a': tf.nn.relu},
{'t': 'dense', 'u': 10, 'a': tf.nn.softmax},
]
model.inference(mode_config)
model.set_loss()
model.set_adamoptimizer(1e-4)
model.set_accuracy()
return model训练100轮,效果果然提升了

四、ResNet模型
这个只展示个34层的图,最大的有152层

这个模型比之前又改进了不少,在imagenet等其他大赛中大放异彩
1、残差块

随着网络的逐步加深,梯度经过一层层的卷积层会逐渐衰减,这个现象也叫梯度弥散
残差神经网络由于存在shorcut connections,网络间的数据流通更为顺畅。ResNet作者认为深度残差网络不太可能由于梯度消失而形成欠拟合,因为这在batch normalized network中就很难出现。残差网络结构的解决方案是,增加卷积层输出求和的捷径连接。
这是我的残差块:
def res_block(self, in_data, param):
out_filter = param['n']
id = param['id']
name = 'res_block_' + str(id)
in_filter = in_data.shape.as_list()[-1]
self.debug(name + ' in shape', in_data.shape.as_list())
with tf.variable_scope(name):
if in_filter != out_filter: #输出是否需要变小
x = self.conv2d(in_data, {'x':3,'y':3,'n':out_filter,'s':2,'b':False,'id':id})
orig_x = self.conv2d(in_data, {'x':3,'y':3,'n':out_filter,'s':2,'b':False,'id':id})
else:
x = self.conv2d(in_data, {'x': 3, 'y': 3, 'n': out_filter, 's': 1, 'b': False, 'id': id})
orig_x = tf.identity(in_data, 'orig_x')
x = self._batch_norm(x, self._is_train, 'bn1')
x = self._relu(x, self._relu_leakiness)
x = self.conv2d(x, {'t': 'conv2d', 'x': 3, 'y': 3, 'n': out_filter, 's': 1, 'id': id})
x = self._batch_norm(x, self._is_train, 'bn2')
x += orig_x
x = self._relu(x, self._relu_leakiness)
self.debug(name + ' out shape', x.get_shape().as_list())
return x2、数据归一化(Batch Normalization)
在Inception V2中提出,这个还是为了防止梯度弥散。它的目的就是要让数据具有0均值和单位方差。实际操纵中是用一个Batch的均值和方差作为对整个数据集均值和方差的估计。 整个BN的算
法如下

def _batch_norm(self, in_data, train_phase, name='bn'):
in_shape = in_data.shape.as_list()
w_shape = [in_shape[-1]]
self.debug(name, 'in shape %s w_shape %s' % (in_shape, w_shape))
with tf.variable_scope(name):
beta = self._variable_on_cpu('beta', tf.constant(0., shape=w_shape))
gamma = self._variable_on_cpu('gamma', tf.constant(1., shape=w_shape))
axises = np.arange(len(in_data.shape) - 1).tolist() #卷积 [0,1,2] 全链接 [0]
batch_mean, batch_var = tf.nn.moments(in_data, axises, name='moments') #全部样本的均值与方差
ema = tf.train.ExponentialMovingAverage(decay=0.9) #移动平均窗口
def mean_var_with_update(): #训练使用移动平均及移动方差
ema_apply_op = ema.apply([batch_mean ,batch_var])
with tf.control_dependencies([ema_apply_op]):
return tf.identity(batch_mean) ,tf.identity(batch_var)
mean, var = tf.cond(train_phase, mean_var_with_update,
lambda: (ema.average(batch_mean), ema.average(batch_var)))
normed = tf.nn.batch_normalization(in_data, mean, var, beta, gamma, 1e-3)
return normed3、全局平均池化(global average pooling)
主要是用来解决全连接的问题,其主要是是将最后一层的特征图进行整张图的一个均值池化,形成一个特征点,将这些特征点组成最后的特征向量进行softmax中进行计算
举个例子
假如,最后的一层的数据是10个6*6的特征图,global average pooling是将每一张特征图计算所有像素点的均值,输出一个数据值,这样10 个特征图就会输出10个数据点,将这些数据点组成一个1*10的向量的话,就成为一个特征向量,就可以送入到softmax的分类中计算了
特征图

代码比较简单
def global_avg_pool(self, in_data, param):
assert in_data.get_shape().ndims == 4
name = 'global_pool_' + str(param['id'])
self.debug(name + ' in shape', in_data.shape)
x = tf.reduce_mean(in_data, [1, 2])
self.debug(name + ' out shape', x.shape)
return x4、实验模型代码
def build_model_resnet():
model = PowerCNNMode('cifar10_resnet', is_debug=True)
model.set_input_placeholder([None, IMAGE_SIZE, IMAGE_SIZE, 3], [None, 10])
model.set_is_train()
model.set_dropout()
mode_config = [{'t': 'conv2d', 'x': 3, 'y': 3, 'n': 16, 's': 1},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 16, 's': 1},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 16, 's': 1},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 16, 's': 1},
{'t': 'dropout'},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 32, 's': 2},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 32, 's': 1},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 32, 's': 1},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 32, 's': 1},
{'t': 'dropout'},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 64, 's': 2},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 64, 's': 1},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 64, 's': 1},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 64, 's': 1},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 64, 's': 1},
{'t': 'dropout'},
{'t': 'global_avg_pool'},
{'t': 'dense', 'u': 10, 'a': tf.nn.softmax},
]
model.inference(mode_config)
model.set_loss()
model.set_adamoptimizer(1e-4)
model.set_accuracy()
return model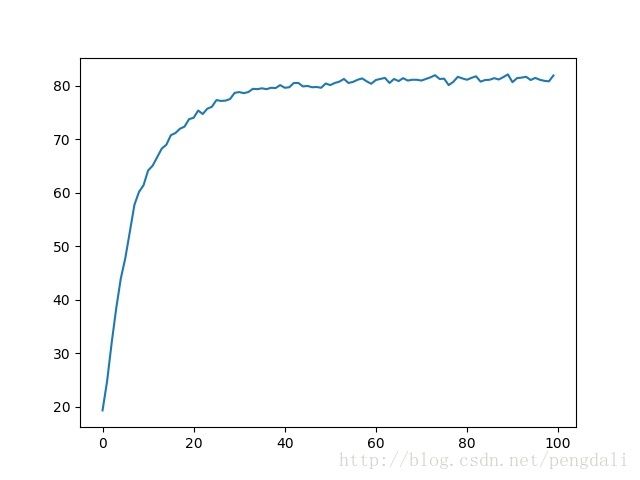
五、代码框架
为了方便的实验各种模型,随意实验调整各种不同配置,我实现了一个简单框架方便使用
1、模型部分
PowerCNNMode.py
import tensorflow as tf
import numpy as np
class PowerCNNMode:
def __init__(self, mode_name, is_debug=True):
self.config_key_map = {
'conv2d' : self.conv2d,
'max_pool' : self.max_pool,
'dense' : self.dense,
'flatten' : self.flatten,
'dropout' : self.dropout,
'lrn' : self.lrn,
'global_avg_pool': self.global_avg_pool,
'res_block' : self.res_block,
}
self._mode_name = mode_name
self._is_debug = is_debug
#private
self.x = None
self.y_ = None
self._dropout = None
self._is_train = None
self._layer_data = None #模型评分结果
self._loss = None #损失函数
self._train_op = None #反向优化
self._accuracy = None #检查函数
self._relu_leakiness = 0.1 #leakiness relu 参数
#输入数据占位
def set_input_placeholder(self, x_shape, y_shape):
self._layer_data = self.x = tf.placeholder(tf.float32, x_shape, name = 'input_data')
self.debug('input data shape ' ,self.x.shape.as_list())
self.y_ = tf.placeholder(tf.float32 ,y_shape ,name = 'y_data')
self.debug('input label shape ' ,self.y_.shape.as_list())
return self.x, self.y_
# 输入数据
def set_input_data(self, in_data, in_label):
self._layer_data = self.x = in_data
self.debug('input data shape ', self.x.shape.as_list())
self.y_ = in_label
self.debug('input label shape ', self.y_.shape.as_list())
#dropout参数
def set_dropout(self):
self._dropout = tf.placeholder(tf.float32, name='input_dropout')
return self._dropout
#is_train参数
def set_is_train(self):
self._is_train = tf.placeholder(tf.bool, name='input_is_train')
return self._is_train
#设置模型
def inference(self, config):
for k,v in enumerate(config):
v['id'] = k + 1
fun = self.config_key_map[v['t']]
self._layer_data = fun(self._layer_data, v)
return self._layer_data
#卷集层
# id 编号
# x 卷积盒宽
# y 卷积盒高
# n 卷积盒个数
# s 卷积步长
# a 激活函数 默认 None 无
# p 填充方式 默认 same
# b 是否有偏置 默认 有
def conv2d(self, in_data, param):
name = 'conv2d_' + str(param['id'])
w_shape = [param['x'], param['y'], in_data.shape.as_list()[-1], param['n']]
step = param['s']
activation = param['a'] if param.has_key('a') else None
p = param['p'] if param.has_key('p') else 'SAME'
is_add_bias = param['b'] if param.has_key('b') else True
self.debug(name ,'in_shape %s w_shape: %s' % (in_data.shape.as_list(), w_shape))
with tf.variable_scope(name):
n = np.sqrt(2. / (param['x'] * param['y'] * param['n']))
w = self._variable_on_cpu(name+'_w', tf.truncated_normal(w_shape ,stddev = n))
b = self._variable_on_cpu(name+'_b', tf.constant(0. ,shape=[w_shape[3]]))
x = tf.nn.conv2d(in_data, w, strides=[1, step, step, 1], padding=p, name=name)
if is_add_bias:
x = tf.nn.bias_add(x, b)
if activation != None:
x = activation(x)
self.debug(name + ' out shape', x.shape.as_list())
return x
#定义池化层
def max_pool(self, in_data, param):
ksize = param['k']
step = param['s']
name = 'max_pool_' + str(param['id'])
self.debug(name + ' in shape', in_data.shape.as_list())
with tf.variable_scope(name):
x = tf.nn.max_pool(in_data ,ksize=[1 ,ksize ,ksize ,1] ,strides=[1 ,step ,step ,1] ,padding='SAME' ,name=name)
self.debug(name + ' out shape', x.shape.as_list())
return x
#抹平参数
def flatten(self, in_data, param):
name = 'flatten_' + str(param['id'])
k = in_data.shape.as_list()
self.debug(name + ' in shape' ,k)
with tf.variable_scope(name):
x = tf.reshape(in_data, [-1 ,np.prod(k[1:])], name=name)
self.debug(name + ' out shape', x.shape.as_list())
return x
#全连接层
def dense(self, in_data, param):
units = param['u']
activation = param['a'] if param.has_key('a') else None
name = 'dense_' + str(param['id'])
input_units = in_data.shape.as_list()
is_add_bias = param['b'] if param.has_key('p') else True
self.debug(name + ' in shape' ,input_units)
with tf.variable_scope(name):
n = 1./units
w = self._variable_on_cpu(name+'_w', tf.truncated_normal([input_units[1] ,units] ,stddev = n))
b = self._variable_on_cpu(name+'_b', tf.constant(0., shape=[units]))
x = tf.matmul(in_data ,w ,name=name)
if is_add_bias:
x = tf.nn.bias_add(x, b)
if activation != None:
x = activation(x)
self.debug(name + ' out shape', x.shape.as_list())
return x
#dropout层
def dropout(self, in_data, param):
name = 'dropout_' + str(param['id'])
k = in_data.shape.as_list()
self.debug(name + ' in shape', k)
with tf.variable_scope(name):
x = tf.nn.dropout(in_data, self._dropout, name=name)
self.debug(name + ' out shape', x.shape.as_list())
return x
#局部响应归一化处理
def lrn(self, in_data, param):
name = 'norm_' + str(param['id'])
self.debug(name + ' in shape', in_data.shape.as_list())
with tf.variable_scope(name):
x = tf.nn.lrn(in_data, depth_radius=4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name=name)
self.debug(name + ' out shape', x.shape.as_list())
return x
#全局池化
def global_avg_pool(self, in_data, param):
assert in_data.get_shape().ndims == 4
name = 'global_pool_' + str(param['id'])
self.debug(name + ' in shape', in_data.shape)
x = tf.reduce_mean(in_data, [1, 2])
self.debug(name + ' out shape', x.shape)
return x
#损失函数
def set_loss(self, name='loss'):
self.debug(name + ' in shape', self._layer_data.shape.as_list())
with tf.variable_scope(name):
self._loss = tf.reduce_mean(-tf.reduce_sum(self.y_ * tf.log(self._layer_data), reduction_indices=[1]))
return self._loss
#训练优化器
def set_adamoptimizer(self, learning_rate=1e-3, name='adamoptimizer'):
self.debug('optimizer' ,name)
with tf.variable_scope(name):
self._train_op = tf.train.AdamOptimizer(learning_rate, name=name).minimize(self._loss)
return self._train_op
#检查函数
def set_accuracy(self, name='accuracy'):
self.debug(name + ' in shape', self._layer_data.shape.as_list())
with tf.variable_scope(name):
correct_prediction = tf.equal(tf.argmax(self._layer_data, 1), tf.argmax(self.y_, 1))
self._accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32) ,name = name) * 100
#----------resnet模型---------#
#res标准块
# id 编号
# n 输出卷积数
def res_block(self, in_data, param):
out_filter = param['n']
id = param['id']
name = 'res_block_' + str(id)
in_filter = in_data.shape.as_list()[-1]
self.debug(name + ' in shape', in_data.shape.as_list())
with tf.variable_scope(name):
if in_filter != out_filter: #输出是否需要变小
x = self.conv2d(in_data, {'x':3,'y':3,'n':out_filter,'s':2,'b':False,'id':id})
orig_x = self.conv2d(in_data, {'x':3,'y':3,'n':out_filter,'s':2,'b':False,'id':id})
else:
x = self.conv2d(in_data, {'x': 3, 'y': 3, 'n': out_filter, 's': 1, 'b': False, 'id': id})
orig_x = tf.identity(in_data, 'orig_x')
x = self._batch_norm(x, self._is_train, 'bn1')
x = self._relu(x, self._relu_leakiness)
x = self.conv2d(x, {'t': 'conv2d', 'x': 3, 'y': 3, 'n': out_filter, 's': 1, 'id': id})
x = self._batch_norm(x, self._is_train, 'bn2')
x += orig_x
x = self._relu(x, self._relu_leakiness)
self.debug(name + ' out shape', x.get_shape().as_list())
return x
#bn层
def _batch_norm(self, in_data, train_phase, name='bn'):
in_shape = in_data.shape.as_list()
w_shape = [in_shape[-1]]
self.debug(name, 'in shape %s w_shape %s' % (in_shape, w_shape))
with tf.variable_scope(name):
beta = self._variable_on_cpu('beta', tf.constant(0., shape=w_shape))
gamma = self._variable_on_cpu('gamma', tf.constant(1., shape=w_shape))
axises = np.arange(len(in_data.shape) - 1).tolist() #卷积 [0,1,2] 全链接 [0]
batch_mean, batch_var = tf.nn.moments(in_data, axises, name='moments') #全部样本的均值与方差
ema = tf.train.ExponentialMovingAverage(decay=0.9) #移动平均窗口
def mean_var_with_update(): #训练使用移动平均及移动方差
ema_apply_op = ema.apply([batch_mean ,batch_var])
with tf.control_dependencies([ema_apply_op]):
return tf.identity(batch_mean) ,tf.identity(batch_var)
mean, var = tf.cond(train_phase, mean_var_with_update,
lambda: (ema.average(batch_mean), ema.average(batch_var)))
normed = tf.nn.batch_normalization(in_data, mean, var, beta, gamma, 1e-3)
return normed
def _relu(self, x, leakiness=0.0, name='leaky_relu'):
self.debug(name + ' in shape', x.shape)
"""Relu, with optional leaky support."""
return tf.where(tf.less(x, 0.0), leakiness * x, x, name=name)
def _variable_on_cpu(self, name, initializer, trainable=True):
with tf.device('/cpu:0'):
var = tf.Variable(initializer, name=name, trainable=trainable)
return var
def _get_variable_on_cpu(self, name, shape, initializer, trainable=True):
with tf.device('/cpu:0'):
var = tf.get_variable(name, shape, initializer=initializer, dtype=tf.float32, trainable=trainable)
return var
#调试信息打印
def debug(self, name, message=''):
if self._is_debug:
print ('%s : %s' % (name, message))
def get_mode_name(self):
return self._mode_name
def get_input_data(self):
return self.x
def get_input_labels(self):
return self.y_
def get_input_dropout(self):
return self._dropout
def get_input_is_train(self):
return self._is_train
def get_loss(self):
return self._loss
def get_train(self):
return self._train_op
def get_accuracy(self):
return self._accuracy
def get_pred(self):
return self._layer_data2、训练与验证部分
这个部分主要是训练和保存一下最佳验证结果的权值
PowerCNNTrain.py
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import time
from datetime import datetime
import os
class PowerCNNTrain:
def __init__(self, model, train_data, train_labels, valid_data, valid_labels, is_dropout=False, is_restore=False, is_debug=True):
self._model = model #模型
self._train_data = train_data
self._train_labels = train_labels
self._valid_data = valid_data
self._valid_labels = valid_labels
self._is_restore = is_restore #是否使用上次存储参数
self._is_debug = is_debug #是否调试
#---模型接口---
self._in_data = model.get_input_data() #输入入口
self._in_labels = model.get_input_labels()
self._in_dropout = model.get_input_dropout() if is_dropout else None
self._in_is_train = model.get_input_is_train()
self._loss = model.get_loss() #损失函数
self._accuracy = model.get_accuracy() #检查函数
self._train_op = model.get_train() #反向优化
#private
self._pre_validation = tf.Variable(0., trainable = False) #之前的精度
self._global_step = tf.Variable(0, trainable=False) #总步数
def train(self, epochs, batch_size, debug_step=10, acc_step=1, dropout=None, is_train=None):
with tf.Session() as sess:
if not self.restore(sess): #是否还原
sess.run(tf.initialize_all_variables()) #执行初始化变量
data_size = self._train_data.shape[0]
batch_num = int(np.ceil(data_size/float(batch_size)))
accuracy_plot = [] #收集验证数据
for i in range(epochs):
for j in range(batch_num):
step_num = i * batch_num + j
start_time = time.time()
start, end = j * batch_size, min((j+1) * batch_size, data_size) #得到每批数据边界
fd = {self._in_data: self._train_data[start:end], self._in_labels: self._train_labels[start:end]}
if dropout != None and self._in_dropout != None:
fd[self._in_dropout] = dropout
if self._in_is_train != None:
fd[self._in_is_train] = True
z = sess.run(self._train_op, feed_dict=fd)
loss_value = sess.run(self._loss, feed_dict=fd) #训练
#assert not np.isnan(loss_value), 'Model diverged with loss = NaN'
duration = time.time() - start_time #训练时间
if step_num % debug_step == 0: #训练性能
examples_per_sec = batch_size / duration
sec_per_batch = float(duration)
format_str = ('%s: step %d, loss = %.2f (%.1f examples/sec; %.3f ''sec/batch)')
self.debug('train',format_str % (datetime.now().strftime("%y-%m-%d %H:%M:%S"), step_num, loss_value,
examples_per_sec, sec_per_batch))
sess.run(tf.assign(self._global_step ,tf.add(self._global_step , 1)))
if i % acc_step == 0 :
fd = {self._in_data: self._valid_data, self._in_labels: self._valid_labels}
if dropout != None and self._in_dropout != None:
fd[self._in_dropout] = 1
if self._in_is_train != None:
fd[self._in_is_train] = False
valid_loss, valid_accuracy = sess.run([self._loss, self._accuracy], feed_dict=fd)
accuracy_plot.append(valid_accuracy)
self.debug('batch_num: %d' % i ,'loss: %f total: %f' % (valid_loss,valid_accuracy))
self.check_and_save(sess, valid_accuracy)
if self._is_debug != 0 and len(accuracy_plot) > 1:
plt.plot(accuracy_plot)
plt.show()
#检查准确率是否有所提高
def check_and_save(self, sess, validation):
if sess.run(self._pre_validation) < validation:
sess.run(tf.assign(self._pre_validation ,validation))
self.save(sess)
#保存当前会话
def save(self, sess):
save_dir = self._model.get_mode_name() + '_cp'
if not os.path.exists(save_dir):
os.makedirs(save_dir)
step = self._global_step.eval()
self.debug('save', '%s step : %d' % (save_dir , step))
saver = tf.train.Saver() # 用于保存变量
#saver.save(sess, os.path.join(save_dir,'best_validation'), step)
saver.save(sess, os.path.join(save_dir,'best_validation')) #保存最佳验证结果
#恢复之前的数据
def restore(self, sess):
if not self._is_restore:
return False
#得到检查点文件
re_path = self._model.get_mode_name() + '_cp'
ckpt = tf.train.get_checkpoint_state(re_path)
if ckpt and ckpt.model_checkpoint_path:
self.debug('restore', ckpt.model_checkpoint_path)
saver = tf.train.Saver()
saver.restore(sess, ckpt.model_checkpoint_path) # 还原所有的变量
self.debug('restore','validation: %f step: %d' % (self._pre_validation.eval(),self._global_step.eval()))
return True
return False
#----------调试部分-------------#
#调试信息打印
def debug(self ,name ,message):
if self._is_debug:
print ('%s : %s' % (name, message))3、最后是构建各种模型
import tensorflow as tf
from PowerCNNMode import PowerCNNMode
from PowerCNNTrain import PowerCNNTrain
#from PowerCNNEval import PowerCNNEval
from tensorflow.python.framework import ops
import numpy as np
from keras.utils import np_utils
from scipy.misc import imsave
IMAGE_SIZE = 32
# 解压缩,返回解压后的字典
def unpickle(file):
import cPickle
fo = open(file, 'rb')
dict = cPickle.load(fo)
fo.close()
return dict
def main_resnet():
#images, labels = build_input_cifar10('./data/cifar-10-batches-bin',128,'train')
#print(images.get_shape())
for i in range(1,6):
file = 'data/cifar-10-batches-py/data_batch_%d' % i
dict = unpickle(file)
img = np.reshape(dict['data'], [-1, 3, 32, 32]) #10000, 3, 32, 32
img = img.transpose(0, 2, 3, 1)
if i==1: #显示前10张图片
for j in range(10):
picName = 'cifar10_img/%d_%d.jpg' % (j , dict['labels'][j])
imsave(picName, img[j])
if not locals().has_key('images'):
images = img
labels = np_utils.to_categorical(dict['labels'])
else:
images = np.concatenate([images,img])
labels = np.concatenate([labels,np_utils.to_categorical(dict['labels'])])
dict = unpickle('data/cifar-10-batches-py/test_batch')
test_images = np.reshape(dict['data'], [-1, 3, 32, 32]) # 10000, 3, 32, 32
test_images = test_images.transpose(0, 2, 3, 1)
test_labels = np_utils.to_categorical(dict['labels'])
model = build_model_resnet()
tr = PowerCNNTrain(model, images, labels,
test_images[:2000], test_labels[:2000],
is_dropout=True, is_restore=False, is_debug=True)
tr.train(epochs=100, batch_size=128, debug_step=200, acc_step=1, dropout=0.75)
def build_model_lenet5():
model = PowerCNNMode('cifar10_lenet5', is_debug=True)
model.set_input_placeholder([None, IMAGE_SIZE, IMAGE_SIZE, 3], [None, 10])
model.set_is_train()
model.set_dropout()
mode_config = [{'t': 'conv2d', 'x': 5, 'y': 5, 'n': 6, 's': 1, 'a': tf.nn.relu},
{'t': 'max_pool', 'k': 2, 's': 2},
{'t': 'dropout'},
{'t': 'conv2d', 'x': 5, 'y': 5, 'n': 16, 's': 1, 'a': tf.nn.relu},
{'t': 'max_pool', 'k': 2, 's': 2},
{'t': 'dropout'},
{'t': 'flatten'},
{'t': 'dense', 'u': 120, 'a': tf.nn.relu},
{'t': 'dropout'},
{'t': 'dense', 'u': 84, 'a': tf.nn.relu},
{'t': 'dense', 'u': 10, 'a': tf.nn.softmax},
]
model.inference(mode_config)
model.set_loss()
model.set_adamoptimizer(1e-4)
model.set_accuracy()
return model
def build_model_alexnet():
model = PowerCNNMode('cifar10_alexnet', is_debug=True)
model.set_input_placeholder([None, IMAGE_SIZE, IMAGE_SIZE, 3], [None, 10])
model.set_is_train()
model.set_dropout()
mode_config = [{'t': 'conv2d', 'x': 3, 'y': 3, 'n': 32, 's': 1, 'a': tf.nn.relu},
{'t': 'lrn'},
{'t': 'max_pool', 'k': 2, 's': 2},
{'t': 'dropout'},
{'t': 'conv2d', 'x': 3, 'y': 3, 'n': 64, 's': 1, 'a': tf.nn.relu},
{'t': 'lrn'},
{'t': 'max_pool', 'k': 2, 's': 2},
{'t': 'dropout'},
{'t': 'conv2d', 'x': 3, 'y': 3, 'n': 64, 's': 1, 'a': tf.nn.relu},
{'t': 'dropout'},
{'t': 'conv2d', 'x': 3, 'y': 3, 'n': 128, 's': 1, 'a': tf.nn.relu},
{'t': 'dropout'},
{'t': 'conv2d', 'x': 3, 'y': 3, 'n': 256, 's': 1, 'a': tf.nn.relu},
{'t': 'max_pool', 'k': 2, 's': 2},
{'t': 'flatten'},
{'t': 'dense', 'u': 1024, 'a': tf.nn.relu},
{'t': 'dropout'},
{'t': 'dense', 'u': 1024, 'a': tf.nn.relu},
{'t': 'dense', 'u': 10, 'a': tf.nn.softmax},
]
model.inference(mode_config)
model.set_loss()
model.set_adamoptimizer(1e-4)
model.set_accuracy()
return model
def build_model_resnet():
model = PowerCNNMode('cifar10_resnet', is_debug=True)
model.set_input_placeholder([None, IMAGE_SIZE, IMAGE_SIZE, 3], [None, 10])
model.set_is_train()
model.set_dropout()
mode_config = [{'t': 'conv2d', 'x': 3, 'y': 3, 'n': 16, 's': 1},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 16, 's': 1},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 16, 's': 1},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 16, 's': 1},
{'t': 'dropout'},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 32, 's': 2},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 32, 's': 1},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 32, 's': 1},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 32, 's': 1},
{'t': 'dropout'},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 64, 's': 2},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 64, 's': 1},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 64, 's': 1},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 64, 's': 1},
{'t': 'res_block', 'x': 3, 'y': 3, 'n': 64, 's': 1},
{'t': 'dropout'},
{'t': 'global_avg_pool'},
{'t': 'dense', 'u': 10, 'a': tf.nn.softmax},
]
model.inference(mode_config)
model.set_loss()
model.set_adamoptimizer(1e-4)
model.set_accuracy()
return model
if __name__ == '__main__':
ops.reset_default_graph()
main_resnet()