Eulerian Video Magnification
原文:http://www.hahack.com/codes/eulerian-video-magnification/
引言
人类的视觉感知存在有限的感知域。对于超出感知域的变化,我们无法感知。然而,这类信号却可能蕴藏着惊人的秘密。
比如,血液循环使得人体的皮肤发生细微的周期性变化,这个裸眼无法感知的变化却和人的心率非常吻合。2011 年,MIT 的一个亚裔学生 Mingzhe Poh 就利用这个微弱的信号设计了一个“魔镜”[1] —— 不仅能照出你的模样,还能测出你的心率。

Mingzhe Poh 的这面神奇的镜子的原理是利用了血液在人体内流动时光线的变化 [2] :心脏跳动时血液会通过血管,通过血管的血液量越大,被血液吸收的光线也越多,人皮肤表面反射的光线就越少。因此,通过对图像的时频分析就可以估算出心率。
再比如,乐器之所以会发出声音,是因为它发声的部分在弹奏过程中发生了有规律的形变,而这个形变的振幅对应着乐器发声的响度,快慢对应着乐器的音高。微弱信号所蕴藏的信息量是如此重大,无怪乎禅语有云:
一花一世界,一叶一菩提。
既然如此,能否将影像中的这些肉眼观察不到的变化“放大”到裸眼足以观察的幅度呢?这就是本文将要重点讨论的问题。
在接下来的篇幅中,我将首先追溯最早的一个放大变化的实验——卡文迪许实验,然后引出适用于现代计算机的两种视角下的影像放大方法。这两种视角分别称为拉格朗日视角(Lagrangian Perspective)和欧拉视角(Eulerian Perspective)。最后我将重点探讨欧拉视角的算法实现细节。我所实现的一个欧拉影像放大算法程序在 Github 上开源。
 附图 1 Henry Cavendish
附图 1 Henry Cavendish
最早的放大:卡文迪许扭秤实验
我所能追溯到的最早的将变化“放大”的实验是 1797 年卡文迪许(H.Cavendish)的经典实验——扭秤实验。卡文迪许实验是第一个在实验室里完成的测量两个物体之间万有引力的实验,并且第一个准确地求出了万有引力常数和地球质量。
实验的装置由约翰·米切尔设计,由两个重达350磅的铅球和扭秤系统组成。
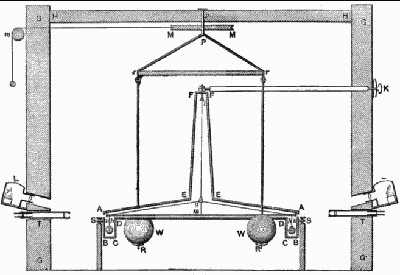
卡文迪许用两个质量一样的铅球分别放在扭秤的两端。扭秤中间用一根韧性很好的钢丝系在支架上,钢丝上有个小镜子。用准直的细光束照射镜子,细光束反射到一个很远的地方,标记下此时细光束所在的点。用两个质量一样的铅球同时分别吸引扭秤上的两个铅球。由于万有引力作用。扭秤微微偏转。但细光束所反射的远点却移动了较大的距离。他用此计算出了万有引力公式中的常数 GG 。
卡文迪许实验取得成功的原因,是将不易观察的微小变化量,转化(放大)为容易观察的显着变化量,再根据显着变化量与微小量的关系算出微小的变化量 。
卡文迪许的实验给了我们一个启示:放大变化,就是要解决以下两个问题:
- 何为“变” —— 如何找出不易观察的微小变化量;
- 放大“变” —— 如何放大这个变化量,使之肉眼可见。
不过,卡文迪许的这个实验需要借助一个庞大的扭秤装置,并不能直接用来放大影像中的变化。对于生活在二十一世纪的我们,最理想的方式当然是要借助计算机这个神器了。接下来将介绍两种现代的技术方案,能够让计算机为我们放大影像中细微的变化,从而使我们具有这样一对火眼金睛,去发现大自然隐藏的秘密。
拉格朗日视角
 附图 2 六祖慧能
附图 2 六祖慧能
时有风吹幡动。一僧云:风动。一僧云:幡动。议论不已。能进曰:不是风动,不是幡动,仁者心动。一众骇然。
六祖慧能在初见五祖的时候,恰逢有风吹来,吹得幡动。于是一个和尚说是风在动,另一个和尚说是幡在动,而慧能却一语道破:不是风动,也不是幡动,而是你的心在动。
看待一样东西,视角不同,得出的结论也就不同。正如看待生活中的“变”,视角不同,也会得到不同的结果。
所谓拉格朗日视角,就是从跟踪图像中感兴趣的像素(粒子)的运动轨迹的角度着手分析。打个比方,假如我们要研究河水的流速,我们坐上一条船,顺流而下,然后记录这条船的运动轨迹。
- 何为“变” —— 感兴趣的像素点随着时间的运动轨迹,这类像素点往往需要借助人工或其他先验知识来辅助确定;
- 放大“变” —— 将这些像素点的运动幅度加大。
2005 年,Liu 等人最早提出了一种针对影像的动作放大技术[3],该方法首先对目标的特征点进行聚类,然后跟踪这些点随时间的运动轨迹,最后将这些点的运动幅度加大。

然而,拉格朗日视角的方法存在以下几点不足:
- 需要对粒子的运动轨迹进行精确的跟踪和估计,需要耗费较多的计算资源;
- 对粒子的跟踪是独立进行的,缺乏对整体图像的考虑,容易出现图像没有闭合,从而影响放大后的效果;
- 对目标物体动作的放大就是修改粒子的运动轨迹,由于粒子的位置发生了变化,还需要对粒子原先的位置进行背景填充,同样会增加算法的复杂度。
欧拉视角
不同于拉格朗日视角,欧拉视角并不显式地跟踪和估计粒子的运动,而是将视角固定在一个地方,例如整幅图像。之后,假定整幅图像都在变,只是这些变化信号的频率、振幅等特性不同,而我们所感兴趣的变化信号就身处其中。这样,对“变”的放大就变成了对感兴趣频段的析出和增强。打个比方,同样是研究河水的流速,我们也可以坐在岸边,观察河水经过一个固定的地方时的变化,这个变化可能包含很多和水流本身无关的成分,比如叶子掉下水面激起的涟漪,但我们只关注最能体现水流速的部分。
- 何为“变” —— 整个场景都在变,而我们所感兴趣的变化信号藏在其中;
- 放大“变” —— 通过信号处理手段,将感兴趣的信号分离,并进行增强。
2012 年, Wu 等人从这个视角着手,提出了一种称为欧拉影像放大技术(Eulerian Video Magnification)的方法[4],其流程如下:
- 空间滤波。将视频序列进行金字塔多分辨率分解;
- 时域滤波。对每个尺度的图像进行时域带通滤波,得到感兴趣的若干频带;
- 放大滤波结果。对每个频带的信号用泰勒级数来差分逼近,线性放大逼近的结果;
- 合成图像。合成经过放大后的图像。

在下一节我们将重点探讨 Wu 等人所提出的这种线性的欧拉影像放大技术。之所以加上“线性”这个修饰词,是因为 Wadhwa 等人在 2013 年对这项技术进行了改进,提出了基于相位的影像动作处理技术[5]。基于相位的欧拉影像放大技术在放大动作的同时不会放大噪声,而是平移了噪声,因而可以达到更好的放大效果。不过对它的讨论超出了本文的篇幅,感兴趣的读者可以自己找来他们的 paper 阅读。
算法细节
空间滤波
如前面所说,欧拉影像放大技术(以下简称 EVM )的第一步是对视频序列进行空间滤波,以得到不同的空间频率的基带。这么做是因为:
- 有助于减少噪声。图像在不同空间频率下呈现出不同的SNR(信噪比)。一般来说,空间频率越低,信噪比反而越高。因此,为了防止失真,这些基带应该使用不同的放大倍数。最顶层的图像,即空间频率最低、信噪比最高的图像,可使用最大的放大倍数,下一层的放大倍数依次减小;
- 便于对图像信号的逼近。空间频率较高的图像(如原视频图像)可能难以用泰勒级数展开来逼近。因为在这种情况下,逼近的结果就会出现混淆,直接放大就会出现明显失真1 1对于这种情况,论文通过引入一个空间波长下限值来减少失真。如果当前基带的空间波长小于这个下限值,就减少放大倍数。。
由于空间滤波的目的只是简单的将多个相邻的像素“拼”成一块,所以可以使用低通滤波器来进行。为了加快运算速度,还可以顺便进行下采样操作。熟悉图像处理操作的朋友应该很快可以反应出来:这两个东西的组合就是金字塔。实际上,线性的 EVM 就是使用拉普拉斯金字塔或高斯金字塔来进行多分辨率分解。
时域滤波
得到了不同空间频率的基带后,接下来对每个基带都进行时域上的带通滤波,目的是提取我们感兴趣的那部分变化信号。
例如,如果我们要放大的心率信号,那么可以选择 0.4 ~ 4 Hz (24~240 bpm )进行带通滤波,这个频段就是人的心率的范围。
不过,带通滤波器有很多种,常见的就有理想带通滤波器、巴特沃斯(Butterworth)带通滤波器、高斯带通滤波器,等等。应该选择哪个呢?这得根据放大的目的来选择。如果需要对放大结果进行后续的时频分析(例如提取心率、分析乐器的频率),则应该选择窄通带的滤波器,如理想带通滤波器,因为这类滤波器可以直接截取出感兴趣的频段,而避免放大其他频段;如果不需要对放大结果进行时频分析,可以选择宽通带的滤波器,如 Butterworth 带通滤波器,二阶 IIR 滤波器等,因为这类滤波器可以更好的减轻振铃现象。

放大和合成
经过前面两步,我们已经找出了“变”的部分,即解决了何为“变”这个问题。接下来我们来探讨如何放大“变”这个问题。
一个重要的依据是:上一步带通滤波的结果,就是对感兴趣的变化的逼近。接下来将证明这个观点。
这里以放大一维的信号为例,二维的图像信号与此类似。
假定现在有个信号 I(x,t)I(x,t) ,在任意时刻 tt ,有:
eq: 1 »
I(x,t)I(x,0)=f(x+δ(t))=f(x),t>0,t=0I(x,t)=f(x+δ(t)),t>0I(x,0)=f(x),t=0
其中,δ(t)δ(t) 是变化信号,在本例中就是一个位移函数。
我们希望得到这个变化放大 αα 倍后的结果,即:
eq: 2 »
I^(x,t)=f(x+(1+α)δ(t))I^(x,t)=f(x+(1+α)δ(t))
为了将变化的部分分离出来,我们用一阶泰勒级数展开来逼近公式 1 表示的信号2 2想起了高数老师在第一节课所说的话:高等代数,也就是微积分,研究的就是一个字:“变”。:
eq: 3 »
I(x,t)≈f(x)+δ(t)∂f(x)∂xI(x,t)≈f(x)+δ(t)∂f(x)∂x
公式 2 中标蓝的部分恰好就是变化的部分,而这个部分又和上一步的带通滤波有着重要的联系。下面分两种情况讨论。
理想情况
我们先考虑一种理想情况:假如所有的变化信号 δ(t)δ(t) 的频率范围恰好是我们进行带通滤波时所选的频带范围,那么带通滤波结果 B(x,t)B(x,t) 应该恰好等于公式 2 中标蓝的部分,即:
eq: 4 »
B(x,t)=δ(t)∂f(x)∂xB(x,t)=δ(t)∂f(x)∂x
对公式 2 所逼近的信号进行放大,就是将这个变化的部分乘以一个放大倍数 αα ,再加回原来的信号中。即:
eq: 5 »
I~(x,t)=I(x,t)+αB(x,t)I~(x,t)=I(x,t)+αB(x,t)
联立公式 2~4 ,可以得到
eq: 6 »
I~(x,t)≈f(x)+(1+α)δ(t)∂f(x)∂xI~(x,t)≈f(x)+(1+α)δ(t)∂f(x)∂x
在这种理想情况下,这个 I~(x,t)I~(x,t) 约等于我们希望得到的 I(x,t)I(x,t) ,即:
eq: 7 »
I~(x,t)≈f(x+(1+α)δ(t))I~(x,t)≈f(x+(1+α)δ(t))
下图演示了使用上面的方法将一个余弦波放大 αα 倍的过程和结果。其中,黑色的曲线表示原信号 f(x)f(x) ,蓝色的曲线表示变化后的信号 f(x+δ)f(x+δ) ,青色的曲线表示对这个信号的泰勒级数逼近 f(x)+δ(t)∂f(x)∂xf(x)+δ(t)∂f(x)∂x,绿色的曲线表示我们分离出来的变化的部分。我们将这个部分放大 αα 倍再加回原信号就得到放大后的信号,图中红色的曲线表示这个放大后的信号 f(x)+(1+α)B(x,t))f(x)+(1+α)B(x,t)) 。

非理想情况
不过,有些时候,我们并没有那么幸运——变化信号 δ(t)δ(t) 的频率范围超出了我们所选的频段范围。这种情况下,应用带通滤波意味着只是保留了一部分的变化信号,而其他频率超出范围的信号将会被减弱。因此,我们用 γk(t)γk(t) 来表示在 tt 时刻变化第 kk 个变化信号减弱的倍数(0≤γk≤10≤γk≤1)3 3它的值和所选的带通滤波器有关。实际上论文原作者考虑这个情况仅仅是出于论证上的严密,在实现时我们不需要计算它,只需要得到 B(x,t) ,而这个值是上一步的带通结果。,则有:
eq: 8 »
B(x,t)=∑kγkδk(t)∂f(x)∂xB(x,t)=∑kγkδk(t)∂f(x)∂x
之后我们又要对它乘以放大倍数 αα 。既然两步都是乘以一个倍数,为了方便起见,我们干脆把这两个线性变化合为一步,即让放大倍数 αk=γkααk=γkα ,则:
eq: 9 »
I~(x,t)≈f(x+∑k(1+αk)δk(t))I~(x,t)≈f(x+∑k(1+αk)δk(t))
放大倍数限制
线性的 EVM 方法会在放大动作变化的同时放大噪声,为了避免造成太大的失真,可以设置一个合理的放大倍数限制。假定信号的空间波长为 λ=2πωλ=2πω ,这个限制可以用公式 9 来表示:
eq: 10 »
(1+α)δ(t)<λ8(1+α)δ(t)<λ8
当超出这个边界的时候,我们可以让 αα 维持在一个边界值,如下图所示:

不过,如果要放大的是颜色的变化,那么从视觉上看并不会很受影响(或者说这种颜色的失真就是我们想要的),这时候就可以不用对 αα 进行限制,或者使用一个更小的空间波长下限值。
算法实现
这一节将介绍我使用 OpenCV 实现线性欧拉影像放大算法的心得。
- 本文的源码遵守 LGPL v3 协议,但这个技术已由原作者申请了专利,因此请勿直接用于商业用途。
- 动作放大的模块引用了 Yusuke Tomoto 的 ofxEvm 项目的相关代码。这个项目基于 EVM 实现了对动作的放大。对于初学者,我建议先阅读他的代码。
- 另外特别感谢 Daniel Ron 和 Aalessandro Gentilini 的大力援助,没有他们我无法完成这个程序。
颜色空间转换
颜色空间转换在原论文中只是一笔带过,但这一步对于放大动作还是非常有用的。在进入整个 framework 之前,作者建议先将图像的颜色空间由 RGB 转换到 YIQ 。YIQ 是 NTSC 电视机系统所采用的颜色空间,Y 是提供黑白电视及彩色电视的亮度信号,I 代表 In-phase,色彩从橙色到青色,Q 代表 Quadrature-phase,色彩从紫色到黄绿色。
采用这种颜色空间可以方便在后期使用一个衰减因子来减少噪声:对于只想放大动作变化的情况,颜色就应该不会发生太大变化,所以我们可以用这个衰减因子来减小放大后的信号的 I 和 Q 两个分量的值。然后再转回 RGB 颜色空间44类似的颜色空间还有 Lab,经过我的测试,使用 Lab 颜色空间也有效。。两个转换函数实现如下:
|
{ Mat ret = src.clone(); Mat T = (Mat_ T = T.inv(); //here inverse! for (int j=0; j for (int i=0; i ret.at + src.at + src.at ret.at + src.at + src.at ret.at + src.at + src.at } } dst = ret; } void ntsc2rgb(const Mat_ { Mat ret = src.clone(); Mat T = (Mat_ T = T.t(); //here transpose! for (int j=0; j for (int i=0; i ret.at + src.at + src.at ret.at + src.at + src.at ret.at + src.at + src.at } } dst = ret; } |
空间滤波
如前面所述,EVM 算法可以使用拉普拉斯金字塔和高斯金字塔来进行空间滤波。使用哪个金字塔得根据具体需求而定。如果要放大的是动作的变化,那么可以选择拉普拉斯金字塔,构造多个不同空间频率的基带;如果要放大的是颜色的变化,不同基带的 SNR 应该比较接近,因此可以选择高斯金字塔,只取最顶层下采样和低通滤波的结果。这两个金字塔可以很容易地利用 OpenCV 的 cv::PyDown() 和 cv::PyUp() 两个函数来构造:
|
* buildLaplacianPyramid - construct a laplacian pyramid from given image * * @param img - source image * @param levels - levels of the destinate pyramids * @param pyramid - destinate image * * @return true if success */ bool buildLaplacianPyramid(const cv::Mat &img, const int levels, std::vector { if (levels < 1){ perror("Levels should be larger than 1"); return false; } pyramid.clear(); cv::Mat currentImg = img; for (int l=0; l cv::Mat down,up; pyrDown(currentImg, down); pyrUp(down, up, currentImg.size()); cv::Mat lap = currentImg - up; pyramid.push_back(lap); currentImg = down; } pyramid.push_back(currentImg); return true; } /** * buildGaussianPyramid - construct a gaussian pyramid from a given image * * @param img - source image * @param levels - levels of the destinate pyramids * @param pyramid - destinate image * * @return true if success */ bool buildGaussianPyramid(const cv::Mat &img, const int levels, std::vector { if (levels < 1){ perror("Levels should be larger than 1"); return false; } pyramid.clear(); cv::Mat currentImg = img; for (int l=0; l cv::Mat down; cv::pyrDown(currentImg, down); pyramid.push_back(down); currentImg = down; } return true; } |
时域滤波
同样,时域滤波可以根据不同的需求选择不同的带通滤波器。如果需要对放大结果进行后续的时频分析,则可以选择理想带通滤波器;如果不需要对放大结果进行时频分析,可以选择宽通带的滤波器,如 Butterworth 带通滤波器,二级IIR 滤波器等。这里分别实现了二阶 IIR 带通滤波器和理想带通滤波器:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
* temporalIIRFilter - temporal IIR filtering an image * (thanks to Yusuke Tomoto) * @param pyramid - source image * @param filtered - filtered result * */ void VideoProcessor::temporalIIRFilter(const cv::Mat &src, cv::Mat &dst) { cv::Mat temp1 = (1-fh)*lowpass1[curLevel] + fh*src; cv::Mat temp2 = (1-fl)*lowpass2[curLevel] + fl*src; lowpass1[curLevel] = temp1; lowpass2[curLevel] = temp2; dst = lowpass1[curLevel] - lowpass2[curLevel]; } /** * temporalIdalFilter - temporal IIR filtering an image pyramid of concat-frames * (Thanks to Daniel Ron & Alessandro Gentilini) * * @param pyramid - source pyramid of concatenate frames * @param filtered - concatenate filtered result * */ void VideoProcessor::temporalIdealFilter(const cv::Mat &src, cv::Mat &dst) { cv::Mat channels[3]; // split into 3 channels cv::split(src, channels); for (int i = 0; i < 3; ++i){ cv::Mat current = channels[i]; // current channel cv::Mat tempImg; int width = cv::getOptimalDFTSize(current.cols); int height = cv::getOptimalDFTSize(current.rows); cv::copyMakeBorder(current, tempImg, 0, height - current.rows, 0, width - current.cols, cv::BORDER_CONSTANT, cv::Scalar::all(0)); // do the DFT cv::dft(tempImg, tempImg, cv::DFT_ROWS | cv::DFT_SCALE, tempImg.rows); // construct the filter cv::Mat filter = tempImg.clone(); createIdealBandpassFilter(filter, fl, fh, rate); // apply filter cv::mulSpectrums(tempImg, filter, tempImg, cv::DFT_ROWS); // do the inverse DFT on filtered image cv::idft(tempImg, tempImg, cv::DFT_ROWS | cv::DFT_SCALE, tempImg.rows); // copy back to the current channel tempImg(cv::Rect(0, 0, current.cols, current.rows)).copyTo(channels[i]); } // merge channels cv::merge(channels, 3, dst); // normalize the filtered image cv::normalize(dst, dst, 0, 1, CV_MINMAX); } /** * createIdealBandpassFilter - create a 1D ideal band-pass filter * * @param filter - destinate filter * @param fl - low cut-off * @param fh - high cut-off * @param rate - sampling rate(i.e. video frame rate) */ void VideoProcessor::createIdealBandpassFilter(cv::Mat &filter, double fl, double fh, double rate) { int width = filter.cols; int height = filter.rows; fl = 2 * fl * width / rate; fh = 2 * fh * width / rate; double response; for (int i = 0; i < height; ++i) { for (int j = 0; j < width; ++j) { // filter response if (j >= fl && j <= fh) response = 1.0f; else response = 0.0f; filter.at } } } |
放大变化
根据前面的公式 5 和公式 8,可以设计如下的放大函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
* amplify - ampilfy the motion * * @param filtered - motion image */ void VideoProcessor::amplify(const cv::Mat &src, cv::Mat &dst) { float curAlpha; switch (spatialType) { case LAPLACIAN: // for motion magnification //compute modified alpha for this level curAlpha = lambda/delta/8 - 1; curAlpha *= exaggeration_factor; if (curLevel==levels || curLevel==0) // ignore the highest and lowest frequency band dst = src * 0; else dst = src * cv::min(alpha, curAlpha); break; case GAUSSIAN: // for color magnification dst = src * alpha; break; default: break; } } |
对于动作信号的放大,调用这个函数前需要先算出每一层基带的 λλ 以及 δ(t)δ(t) 的值,以便于根据公式 10 来计算当前合理的放大倍数:
2 3 4 5 6 7 8 |
delta = lambda_c/8.0/(1.0+alpha); // the factor to boost alpha above the bound // (for better visualization) exaggeration_factor = 2.0; // compute the representative wavelength lambda // for the lowest spatial frequency band of Laplacian pyramid lambda = sqrt(w*w + h*h)/3; // 3 is experimental constant |
注意:这里的 λcλc 就是前面所提的空间波长的下限值。对于 λ<λcλ<λc 的基带,αα 值将被减弱。另外,还加了一个 exaggeration_factor 参数,它是一个魔数(magic number),用来将符合 λ>λcλ>λc 的基带加倍放大。
合成图像
先合成变化信号的图像,再与原图进行叠加。根据使用金字塔的类型,编写对应的合成方法:
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
/** * reconImgFromLaplacianPyramid - reconstruct image from given laplacian pyramid * * @param pyramid - source laplacian pyramid * @param levels - levels of the pyramid * @param dst - destinate image */ void reconImgFromLaplacianPyramid(const std::vector const int levels, cv::Mat_ { cv::Mat currentImg = pyramid[levels]; for (int l=levels-1; l>=0; l--) { cv::Mat up; cv::pyrUp(currentImg, up, pyramid[l].size()); currentImg = up + pyramid[l]; } dst = currentImg.clone(); } /** * upsamplingFromGaussianPyramid - up-sampling an image from gaussian pyramid * * @param src - source image * @param levels - levels of the pyramid * @param dst - destinate image */ void upsamplingFromGaussianPyramid(const cv::Mat &src, const int levels, cv::Mat_ { cv::Mat currentLevel = src.clone(); for (int i = 0; i < levels; ++i) { cv::Mat up; cv::pyrUp(currentLevel, up); currentLevel = up; } currentLevel.copyTo(dst); } |
衰减 I、Q 通道
对于动作信号的放大,可以在后期引入一个衰减因子减弱 I、Q 两个通道的变化幅度,最后才转回 RGB 颜色空间。
2 3 4 5 6 7 8 9 10 11 12 13 14 |
* attenuate - attenuate I, Q channels * * @param src - source image * @param dst - destinate image */ void VideoProcessor::attenuate(cv::Mat &src, cv::Mat &dst) { cv::Mat planes[3]; cv::split(src, planes); planes[1] = planes[1] * chromAttenuation; planes[2] = planes[2] * chromAttenuation; cv::merge(planes, 3, dst); } |
结果
下面演示使用我的程序,对论文提供的 face 案例进行处理的结果。
所选参数如下:
| αα | λcλc | 频段 | 衰减因子 | |
|---|---|---|---|---|
| 动作变化放大 | 10 | 80 | 0.05~0.4 | 0.1 |
| 颜色变化放大 | 50 | - | 0.83~1.0 | - |
源码和程序
-
QtEVM 的源码
-
QtEVM 的 Win32 可执行程序