Reducing DRAM Footprint with NVM in Facebook
Assaf Eisenman, Asaf Cidon, Sachin Katti. Stanford University
Darryl Gardner, Islam Abdelrahman, Jens Axboe, Siying Dong, Kim Hazelwood, Chris Petersen. Facebook Inc.
Eurosys '18
Abstract
目前DRAM大量使用但是DRAM成本很高,本文提出了MyNVM这个系统,利用NVM块设备来减少DRAM的使用,从而减少整体成本,同时还能提供和使用更多DRAM的MyRocksd能够相比的延迟以及QPS(query per second)。
使用NVM替换DRAM的主要问题是不如DRAM的读带宽以及在高写负载下的寿命问题。
解决这个问题的主要方法:
- 使用partitioned index的small size block
- 通过对齐压缩后的块减少读带宽需要
- 使用字典压缩
- 通过实现权限控制策略限制进入NVMcache的对象控制寿命
- 用轮询机制替换中断
效果:应用到Facebook的实际环境中,对比myrocks将内存需求从96GB降到了16GB,并且是第一个将NVM设备应用到实际环境中的
Introduction
当前的KVS比如RocksDB或者LevelDB仍高度依赖于DRAM,使用DRAM来缓存热数据对象。MyRocks是基于RocksDB构建的MySQL,Facebook中的一个MyRocks server使用了128G DRAM和3TB的flash,所以目前的KVS对DRAM的依赖很高。而受限于DRAM容量增长缓慢,DRAM价格不断上涨,一年内已经增加了2.3X。
本文目标是减少DRAM的使用量同时保持平均延迟、第99百分位延迟以及QPS。做的第一个测试就是直接将MyRocks的内存减少到16GB,观察到性能下降
NVM提供两种形式,一种是更贵的可字节寻址的形式,另一种是更便宜的块设备形式,本文为了节约成本就选择了块设备的形式。
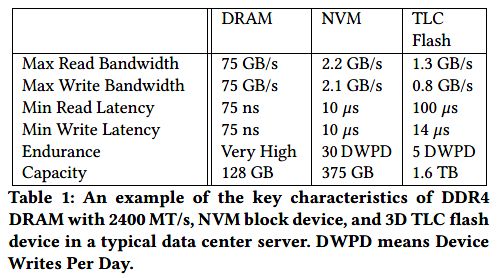
根据提供的数据对比,NVM设备虽然在读和寿命上分别是Flash的10x以及5x,但是仍比DRAM慢了100X,所以NVM更适合拿来做一个容量更大的缓存
使用NVM替换DRAM作为cache的主要问题:
- NVM读带宽没有DRAM高,同时减少DRAM用量导致能被DRAM缓存的数据更少
- 使用更小的Data Block会降低他们的压缩率
- 写寿命问题
- NVM延迟更低导致操作系统中断带来的开销占比增加
Contribution:
- 使用NVM作为一个二级cache
- 将数据库的索引进行划分,实现更细粒度的索引缓存,从而减少缓存index block的数量,同时将压缩后的block聚集到同一个NVM页,并按页对齐
- 采用更小的block size之后使用字典压缩
- 限制只有高命中率的数据进入NVM
- 混合的轮询机制
- 减少DRAM达到6X,性能接近于更高内存的MyRocks
Background
介绍RocksDB、MyRocks以及NVM带来的问题
RocksDB and MyRocks
LinkBench
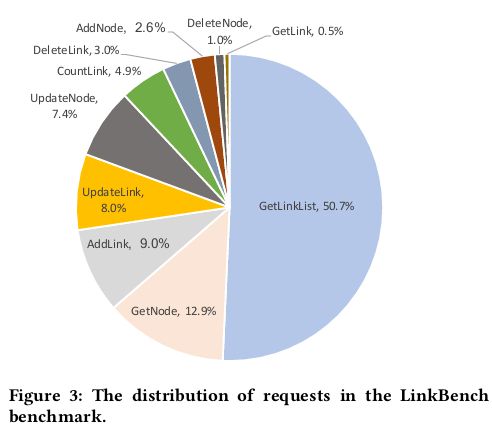
LinkBench是一个开源的数据库benchmark,主要基于Facebook用于存储社交关系图的真实trace,访问数据库的操作主要包括单点读、range查询、count查询、创建、删除以及更新,个操作比例如下图。
LinkBench分为两个工作阶段,首先通过生成加载合成的社交图来填充数据库,然后是通过数据库查询负载来运行benchmark
NVM
NVM有两种形态,一种是DIMM形式,另一种是块设备形式,本文针对的是块设备形式,因为便宜
基础性能测试
条件:Fio 2.19、4并发任务、不同的队列深度、Libaio engine,对比3D Triple-Level Cell Flash
-
Latency
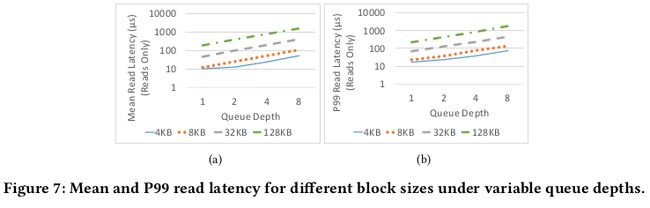
在较低队列深度中NVM性能是flash的10x,并且在真实的负载下Flash表现出因为读写争用造成的性能损耗
随着block size的增加,延迟也会增加
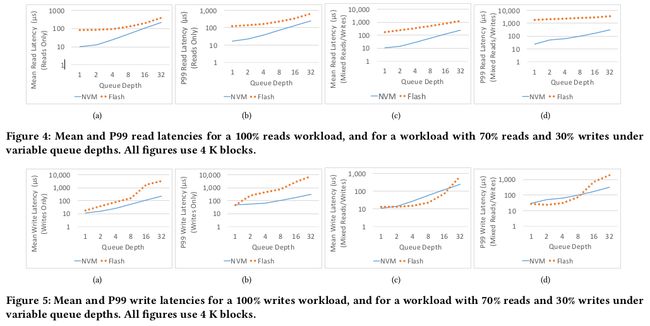 不同queue depth下的性能
不同queue depth下的性能
-
Bandwidth
NVM的Bandwidth per capacity更高
对于混合负载,随着读比例减小,combine bandwidth从2.2GB/s减少到1.8GB/s,但是这种情况可以通过增加block size解决
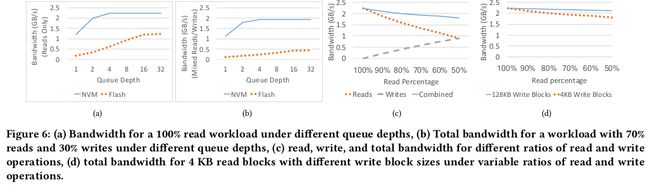 queue depth以及读写比对bandwidth的影响
queue depth以及读写比对bandwidth的影响 Durability
可以提供TLC 6X的写入量,并且NVM并没有flash的写放大的问题
Challenge
相对DRAM更高的延迟、更低的带宽、寿命限制、block限制、操作系统中断带来的开销占比增加
Design
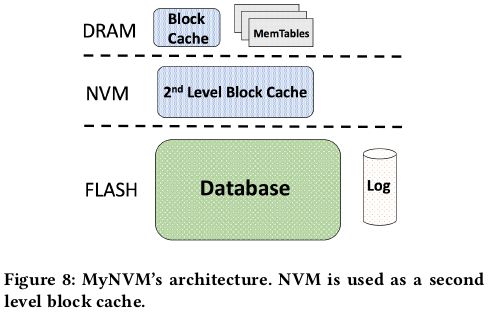
将NVM作为一个第二层的buffer,容量比DRAM更大,默认使用LRU算法作为淘汰策略
Satisfying NVM's Read Bandwidth
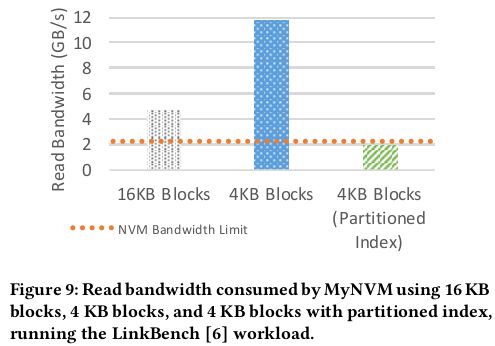
MyNVM默认16KB的block大小,但是测试集中的read size为10-100B,所以每次读至少读16KB造成了160X的读放大
Reducing Block Size
既然16KB的block太大那么就减少block size到4KB,但是结果出人意料,读带宽需求增加到了原来的两倍以上,其原因是block size减少之后,index block的size会增加,block size从16KB变到4KB,其index size增加了4倍,这样消耗更多的DRAM降低了命中率
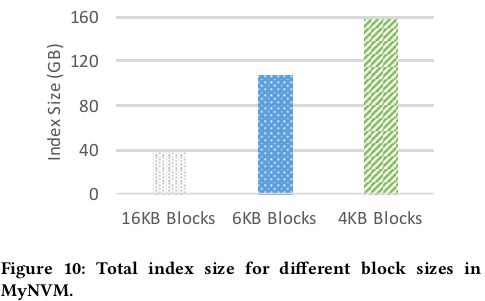
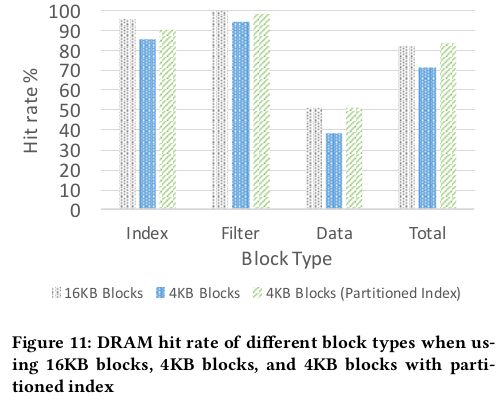
为了解决这个问题提出了index划分的方法,原来是一个SST对应一个index block,一个index可能包含了许多冷数据。现在一个SST对应多个index block,所有的index block再对应一个顶层index block,顶层index block索引次级index block,DRAM内只缓存顶层index block,以及被读到的对应的次级index block,使得缓存命中率达到16KB的情况。

Aligning Blocks with Physical Pages
由于RocksDB内会对Block进行压缩,导致原本为4KB的block不到4KB,从而写不满一个NVM的物理页,下一个block就会跨页造成读放大。所以MyNVM中使用6KB的Block,使得压缩后差不多刚好4KB(减少了index size所以同样减少了带宽消耗)。不过还存在压缩后不够4KB,或者超过4KB的情况。
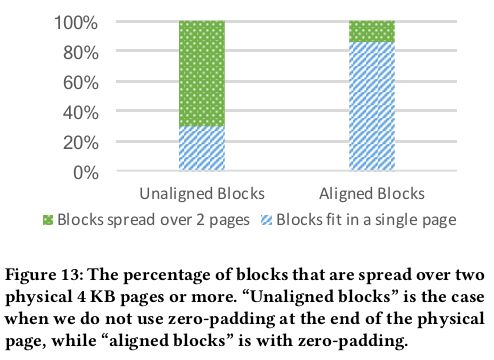
对于不够4KB则进行0填充,超过的只能跨页了。

最终效果是Block对齐减少了读带宽需求,但是由于进行了0填充,所以略微增加了写带宽需求以及降低了命中率


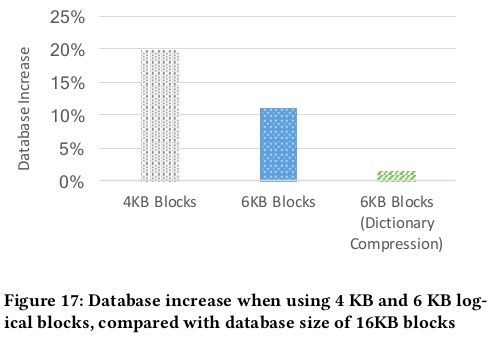
Database Size
减少block size会导致压缩效率的降低,导致数据库的空间占用增加
什么预载?
NVM Durability Constraint
如果单纯地把NVM当做一个二级cache,那么其写带宽很快就会超过设备的寿命限制,因为冷数据的频繁换入换出
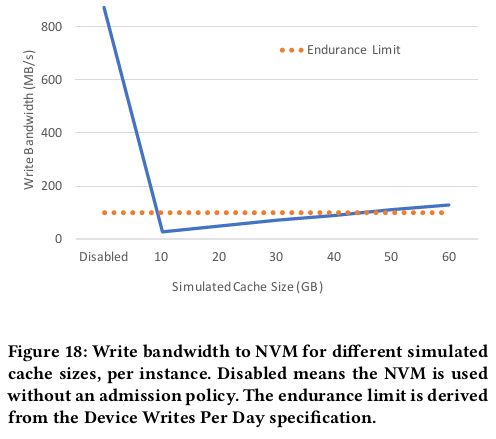
本文的解决办法是限制只有可能频繁访问的数据才放入NVM,具体做法是在DRAM里面维护一个LRU list并且缓存被访问的block的key,然后对于一个从flash里面读出来的block,只有当他出现在DRAM的LRUlist里面才会被加入到NVM里面。
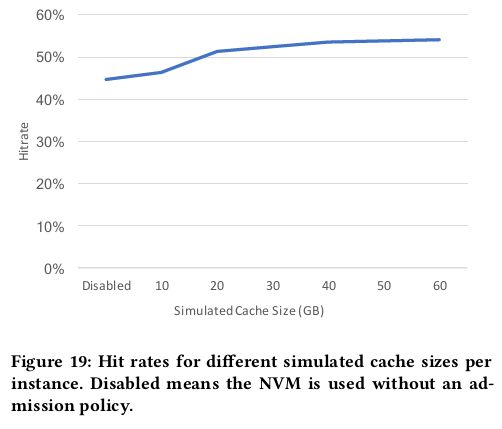
随着模拟cache模拟的容量增加,缓存命中率也随之增加,同时也造成写带宽需求增加,一个平衡点则为40GB,见figure18.
Interrupt Latency
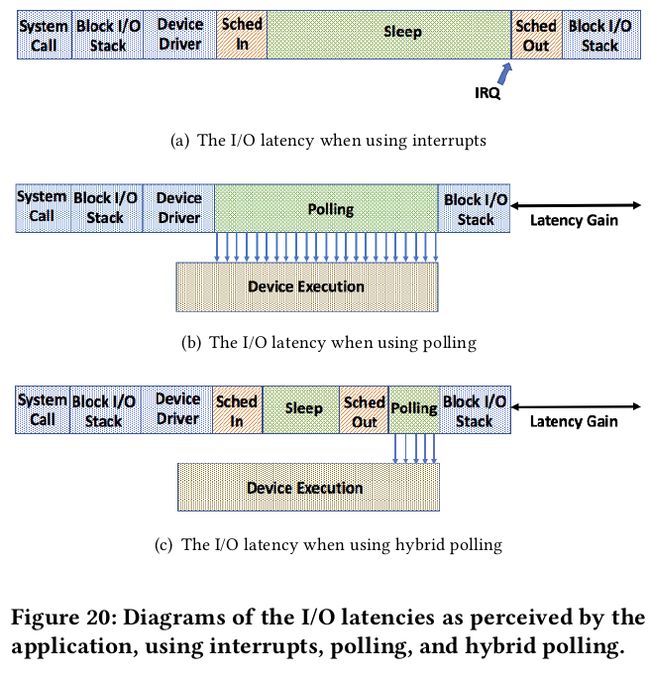
由于NVM很快,使用带中断的异步IO会带来CPU上下文切换的开销,所以本文使用了轮询机制,但是直接使用轮询会导致CPU占用达到100%(通过Fio的pvsync2 I/O engine进行测试),所以为了克服这个问题,又提出IO请求提交之后休眠一段固定的时间在进行轮询的方式,但是这样的方式在线程数增加之后还是会导致CPU占用增加,其原因是等待的时间是一个常量,所以又提出解决办法是设置一个动态的等待时间,即dynamic hybrid polling technique,每次等待的时间是之前IO的延迟的平均值。
最后测试发现随着线程数增加到8,这样的加速方式效果不再明显,主要的原因有几条:
- 多个线程同时访问设备之后增加了单个IO的延迟
- 多线程的时候CPU在线程提交IO之后可能等待(?)
- 多线程同时轮询增加了轮询的开销,解决办法之一是专门用一个线程去轮询(但好像只有在比较深的队列深度以及pipeline IO的时候才有效)
- Linux内核将所有的NVMe 提交/完成队列都进行轮询增加了轮序开销
综上所述,MyNVM暂时没有引入轮询的机制到生产环境
Applicability to Fast Flash Device
快速flash设备类似于NVM所以本文的策略也适用于快速flash,但是flash有NVM没有的问题比如写放大以及读写干扰等问题,所以也不能直接用,还要做些有话,做什么优化就是别人的问题了。
Implementation
MyNVM基于MyRocks和RocksDB实现
MyNVM将DRAM作为一级cache,缓存未压缩的block,从NVM读以及写数据到NVM都是通过direct I/O进行。NVM中block是压缩的。
查找的时候,MyNVM首先访问DRAM,miss的时候再去查找NVM,并且这个时候不会立刻把miss的内容加入到cache而是会通过前面的缓存管理策略决定哪些key能被加入到NVM。对应的需要维护一个DRAM中的simulated cache并且每次访问都要更新这个cache,为了减少这个cache的空间占用,缓存的key是原来的key的hash值。
写入NVM会被打包成128KB,被缓存的block会被追加到NVM文件中,NVM中以文件为单位管理缓存空间,当空间不够的时候就删除最老的文件释放空间。
MyNVM的index是两层的,次级index以4KB为单位进行划分(index block不会被压缩),由于index是有序的所以可以使用二分查找。
块对齐
MyNVM使用Zstandard压缩算法,并采用了字典压缩,字典存储在SST的专用的block中,用于压缩和解压
通过pwriteev2和preadev2实现dynamic hybrid polling(并未被加入系统中)
Evaluation
配置:
- dual-socket Xeon E5 processor
- MyRocks + 96GB DRAM
- MyRocks + 16GB DRAM
- MyNVM + 16GB DRAM + 140GB NVM
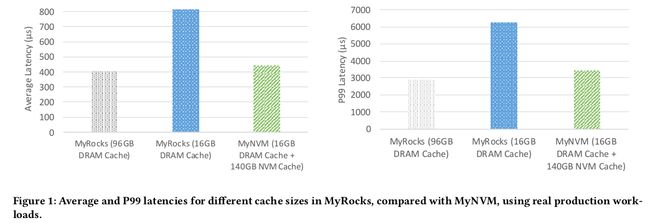
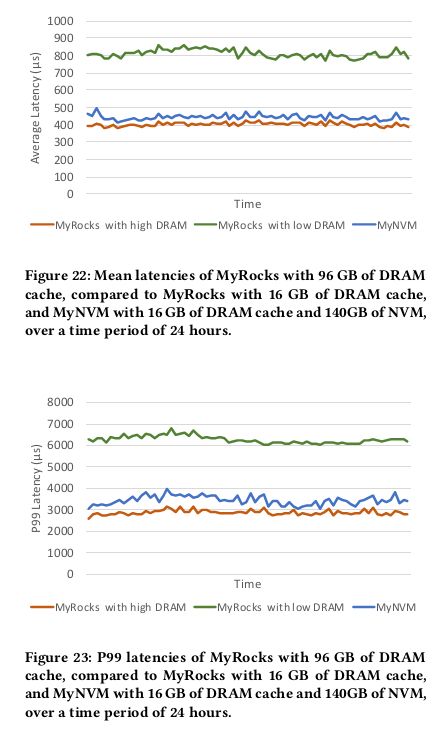
Mean and P99 Latency
测试方法:shadow workload
MyNVM比16G DRAM延迟低了45%,比96GB DRAM略高
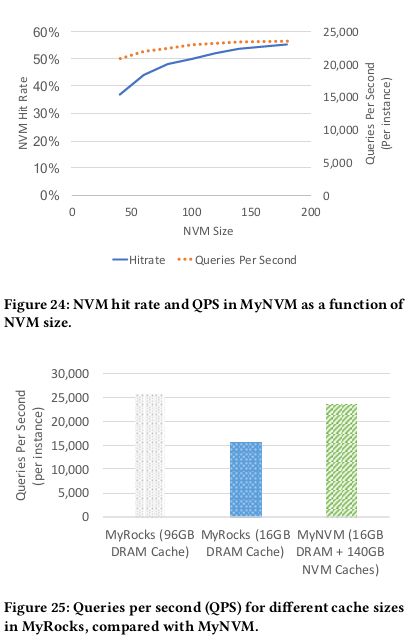
QPS
测试方法:LinkBench
MyNVM在超过140GB的之后收益减少,所以选择140GB命中率和QPS最佳
对比MyRocks,16GB性能超过50%,96GB略低8%
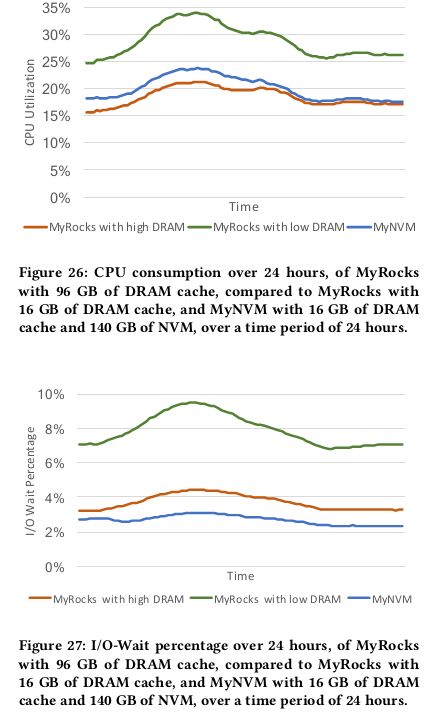
CPU Consumption
减少DRAM会导致CPU占用增加,主要是两方面原因,一是block换入换出会带来解压的开销,另一个是CPU需要花更多时间等待请求写到flash