python实战笔记之(13):Scrapy基本用法实例讲解
Scrapy是一个非常强大的异步爬虫框架,它已经给我们写好了许许多多的组件,使用Scrapy我们只用关心爬虫的逻辑就好了。本文通过一个简单的项目了解一下Scrapy的爬取流程,对Scrapy的基本用法也有一个大体的了解。
一、目标站点分析
Scrapy提供了一个官方抓取网站:http://quotes.toscrape.com,主要列出了一些名人名言,相应的作者和标签信息。

下拉到底点击“Next” 会进行翻页,URL变为“http://quotes.toscrape.com/page/2/”,这是一个最简单的GET请求实例,通过改变链接的名称就可以进行翻页了,网页结构也非常简单,没有任何的反爬虫措施,所以就选用这一个站点作为Scrapy的入门实例。
二、流程框架
1.抓取第一页
请求第一页的URL并得到源代码,进行下一步的分析。
2.获取内容和下一页链接
分析源代码,提取首页内容,获取下一页链接等待进一步提取。
3.翻页爬取
请求下一页信息,分析内容并请求下一页链接。
4.保存爬取结果
将爬取结果保存为特定格式,如文本、数据库。
三、Scrapy实战
1.首先cd到项目目录下,输入“scrapy startproject quotetutorial”,即项目名为quotetutorial。

2.按照提示,首先“cd quotetutorial”,接着用genspider创建一个spider:“scrapy genspider quotes quotes.toscrape.com”,其中“quotes”为spider名称,“quotes quotes.toscrape.com”是要爬取的URL。

现在我们就完成了spider的创建,实际上就是为我们创建了一个“quotes.py”文件,文件内容如下:
# -*- coding: utf-8 -*-
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
pass
除此之外,我们可以看到还有以下文件:
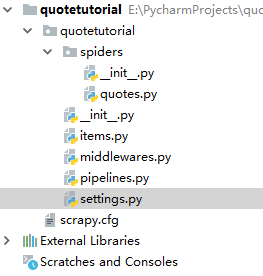
其中,“scrapy.cfg”为配置文件 ;“items.py”是用来保存数据的数据结构;“middlewares.py”是在爬取过程中定义的一些中间件,可以用来处理Request,Response以及Exceptions等操作,也可以用来修改Request, Response等相关的配置;“pipelines.py”即项目管道,可以用来输出一些items;另外,最重要的就是“settings.py”,里面定义了许多配置信息。最主要的运行代码是在“quotes.py”里面。
首先在命令行运行一下“scrapy crawl quotes”,回车之后控制台输出了一些调试信息。可以看出,它和普通的爬虫不太一样,Scrapy提供了很多额外的输出。
E:\PycharmProjects\quotetutorial>scrapy crawl quotes
2018-09-06 20:24:23 [scrapy.utils.log] INFO: Scrapy 1.3.3 started (bot: quotetutorial)
2018-09-06 20:24:23 [scrapy.utils.log] INFO: Overridden settings: {'BOT_NAME': 'quotetutorial', 'NEWSPIDER_MODULE': 'quotetutorial.spiders', 'ROBOTSTXT_OBEY': True,
'SPIDER_MODULES': ['quotetutorial.spiders']}
2018-09-06 20:24:24 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2018-09-06 20:24:25 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-09-06 20:24:25 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2018-09-06 20:24:26 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2018-09-06 20:24:26 [scrapy.core.engine] INFO: Spider opened
2018-09-06 20:24:26 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-09-06 20:24:26 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-09-06 20:24:27 [scrapy.core.engine] DEBUG: Crawled (404) (referer: None)
2018-09-06 20:24:28 [scrapy.core.engine] DEBUG: Crawled (200) 这么看这个爬虫似乎没有输出我们想要的那种信息,将“quotes.py”文件改写之后再运行:
# -*- coding: utf-8 -*-
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
print(response.text)上面文件中的parse方法,是请求文件之后默认调用的一个方法,我们在这里可以打印出请求的响应内容。

parse方法实际上就是一个默认的回调,在爬虫启动的时候会首先请求start_urls里的链接,然后会自动调用parse方法进行解析。
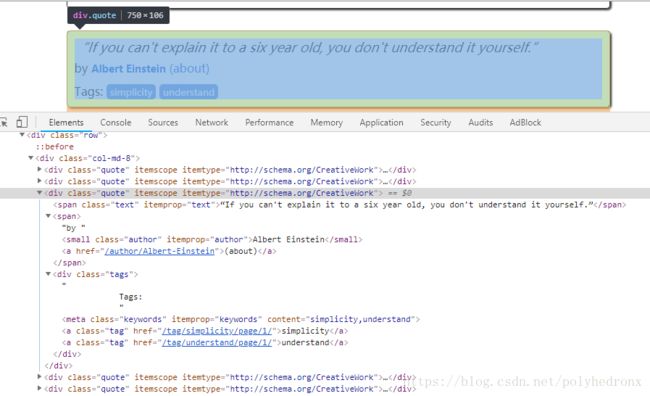
3.接下来,我们看一下该怎么抓取这个网页。
网页结构很简单,看下图便一目了然。class="text"包含了句子内容,class="author"包含了作者信息,class="tags"包含了标签信息,它们都包含在class="quote"的一个div标签里。
借助Scrapy提供的“items.py”定义统一的数据结构,指定一些字段之类的,将爬取到的结果作为一个个整体存下来。根据提示更改文件如下:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class QuoteItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
接下来在parse方法里面写一下解析的方法:
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
text = quote.css('.text::text').extract_first()
author = quote.css('.author::text').extract_first()
tags = quote.css('.tags .tag::text').extract()解析方法和pyquery非常相似,“.text”指的是标签的class,“::text”是Scrapy特有的语法结构,表示输出标签里面的文本内容,“extract_first()”方法表示获取第一个内容,而“extract”会把所有结果都找出来(类似于find和findall)。
Scrapy还为我们提供了一个非常强大的工具--shell,直接输入“scrapy shell quotes.toscrape.com”就可以进入命令行交互模式:
E:\PycharmProjects\quotetutorial>scrapy shell quotes.toscrape.com
2018-09-06 21:02:36 [scrapy.utils.log] INFO: Scrapy 1.3.3 started (bot: quotetutorial)
2018-09-06 21:02:36 [scrapy.utils.log] INFO: Overridden settings: {'BOT_NAME': 'quotetutorial', 'DUPEFILTER_CLASS': 'scrapy.dupefilt
ers.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0, 'NEWSPIDER_MODULE': 'quotetutorial.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES':
['quotetutorial.spiders']}
2018-09-06 21:02:36 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole']
2018-09-06 21:02:37 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-09-06 21:02:37 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2018-09-06 21:02:37 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2018-09-06 21:02:37 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-09-06 21:02:37 [scrapy.core.engine] INFO: Spider opened
2018-09-06 21:02:39 [scrapy.core.engine] DEBUG: Crawled (404) (referer: None)
2018-09-06 21:02:39 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
2018-09-06 21:02:48 [traitlets] DEBUG: Using default logger
2018-09-06 21:02:48 [traitlets] DEBUG: Using default logger
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler
[s] item {}
[s] request
[s] response <200 http://quotes.toscrape.com>
[s] settings
[s] spider
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
In [1]:
在此模式可以进行一些相应的调试,比如输入“response”就会有一个输出结果:
In [1]: response
Out[1]: <200 http://quotes.toscrape.com>
同样地,我们可以查看“response.css('.quote')”的输出:
In [2]: quotes = response.css('.quote')
In [3]: quotes
Out[3]:
[,
,
,
,
,
,
,
,
,
]
输出结果是list类型,里面的内容是Selector选择器,查看第一个结果:
In [4]: quotes[0]
Out[4]:
继续使用css选择器选择class为text的部分,可以看到结果也是一个list,内容只有一个,也是一个Selector。
In [5]: quotes[0].css('.text')
Out[5]: []
使用“::text”会有什么不同呢?让我们来看一下:
In [6]: quotes[0].css('.text::text')
Out[6]: []
可以看到,不同之处是里面的data变成了字符串格式的数据,而不带“::text”获取到的是整个标签的内容。
再加上extract()会发生什么呢?
In [7]: quotes[0].css('.text::text').extract()
Out[7]: ['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”']
返回的依然是list,长度为1,内容是一个字符串。如果去掉“::text”,则返回的是内容为标签的list,如下。也就是说,使用extract(),是把原来Selector中的data单独提取了出来。
In [8]: quotes[0].css('.text').extract()
Out[8]: ['“The world as we have created it is a process of our thinking. It cannot be changed wi
thout changing our thinking.”']
我们再继续修改一下,使用extract_first()。可以想到,使用extract_first()获取到的应该是原来list中的第一个值,也就是说,现在返回的应该是一个字符串,而不再是一个列表了。
In [9]: quotes[0].css('.text::text').extract_first()
Out[9]: '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”'
上面选取的是class为text的标签,里面只有一个元素,所以用extract()获取到的list里面也只有一个元素,而class为tags的标签就不一样了,里面包含了可能不止一个元素,如下,我们获取到的就是一个包含了多个元素的list。使用extract_fist()依然可以获取list中的第一个元素。
In [10]: quotes[0].css('.tags .tag::text').extract()
Out[10]: ['change', 'deep-thoughts', 'thinking', 'world']
In [11]: quotes[0].css('.tags .tag::text').extract_first()
Out[11]: 'change'
综上,我们就可以理解了extract_first()和extract()的不同之处,一个是返回第一个结果,一个是返回列表形式的内容。以后我们在做单个结果的解析时,可以使用extract_first(),多个使用extract()就好了。
接下来调用一下我们刚才定义的items,将提取出的网页信息存储到item,然后调用yield方法将item生成出来。
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
item = QuoteItem()
text = quote.css('.text::text').extract_first()
author = quote.css('.author::text').extract_first()
tags = quote.css('.tags .tag::text').extract()
item['text'] = text
item['author'] = author
item['tags'] = tags
yield item重新运行一下爬虫(在命令行输入“scrapy crawl quotes”)就能看到输出了提取出的一些信息:

4.翻页并爬取其它页面信息
由于网页的请求方式非常简单,比如第二页就是“http://quotes.toscrape.com/page/2/”,请求其它页只要将“2”替换成对应数字即可。在页面底端点击“Next”也可以切换到下一页,这是因为“Next”对应着下一页的超链接,同样地,我们可以从网页源代码中提取出这个超链接。

根据分析将parse方法修改如下:
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
item = QuoteItem()
text = quote.css('.text::text').extract_first()
author = quote.css('.author::text').extract_first()
tags = quote.css('.tags .tag::text').extract()
item['text'] = text
item['author'] = author
item['tags'] = tags
yield item
next = response.css('.pager .next a::attr(href)').extract_first()
url = response.urljoin(next)
yield scrapy.Request(url=url, callback=self.parse)其中,urljoin方法是为了拼凑出完整的url,因为我们获取到的“next”只是类似于“/page/3/”这样。最后生成一个Request,第一个参数就是要请求的url,第二个参数“callback”是回调函数的意思,也就是请求之后得到的response由谁来处理,这里我们还是调用parse,因为parse方法就是用来处理索引页的,这就相当于完成了一个递归的调用,可以一直不断地获取下一页的链接并对访问得到的信息进行处理。
再次重新运行程序,可以看到输出了10页的内容,这是因为该网站只有10页内容。
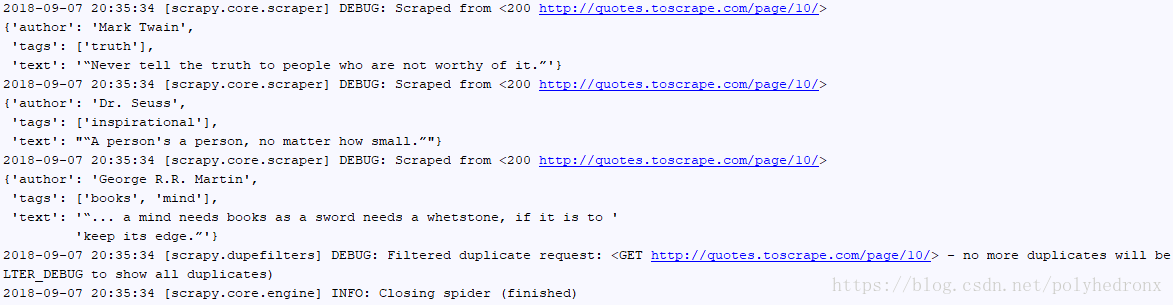
5.下面我们把抓取到的信息进行保存。
保存信息也很简单,在原来的命令后面增加“-o 文件名称.json”,爬取完成后就会生成一个“quotes.json”文件,把获取到的信息保存成了标准的json格式。
scrapy crawl quotes -o quotes.json
数据不仅可以保存成json格式,Scrapy还提供了其它存储格式,比如“jl”格式,在命令行输入如下命令就可以得到jl格式文件。相比于json格式,它没有了最前面和最后面的的大括号,每条数据独占一行。
scrapy crawl quotes -o quotes.jl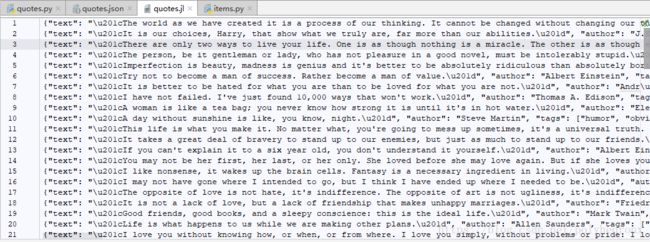
或者保存成csv格式:
scrapy crawl quotes -o quotes.csv
它还支持xml:
scrapy crawl quotes -o quotes.xml
此外它还支持“pickle”和“marshal”等格式,此处就不一一列举了。
Scrapy同时提供了一种远程ftp的保存方式,可以将爬取结果通过ftp的形式进行保存,例如:
scrapy crawl quotes -o ftp://user:[email protected]/path/quotes.csv
6.在保存之前还需要做一些item的相应的处理,因为在解析完之后,有一些item可能不是我们想要的,或者我们想把item保存到数据库里面,就需要借助Scrapy的Pipeline工具。
如下,在“pipelines.py”里我们写了两个pipeline,第一个TextPipeline类是对item进行一些处理,这里实现的功能是长度限制,如果text长度大于50,则舍弃后面的部分,并用省略号代替。在item的text不存在时,DropItem抛出异常。MongoPipeline类是用来将数据保存到MongoDB数据库,其中,类方法from_crawler用来从settings里面拿到配置信息,当然,我们同时需要在“settings.py”文件里面添加配置信息。open_spider方法是在爬虫刚要启动时需要执行的操作,在这里进行pymongo的一些初始化操作。复写process_item方法,将数据写入数据库。最后close_spider方法将MongoDB的连接关闭。
注意:要想让pipeline生效,需要在settings里面指定pipeline。后面的序号300和400这样,代表pipeline运行的优先级顺序,序号越小表示优先级越高,会优先进行调用。
# pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from scrapy.exceptions import DropItem
class TextPipeline(object):
def __init__(self):
self.limit = 50
def process_item(self, item, spider):
if item['text']:
if len(item['text']) > self.limit:
item['text'] = item['text'][0:self.limit].rstrip() + '...'
return item
else:
return DropItem('Missing Text')
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
name = item.__class__.__name__
self.db['quotes'].insert(dict(item))
return item
def close_spider(self, spider):
self.client.close()
# settings.py
MONGO_URI = 'localhost'
MONGO_DB = 'quotestutorial'
ITEM_PIPELINES = {
'quotetutorial.pipelines.TextPipeline': 300,
'quotetutorial.pipelines.MongoPipeline': 400,
}搞好之后我们可以再次运行一下程序(命令行输入“scrapy crawl quotes”),可以看到输出的text过长的话,后面就被省略号代替了,同时数据也被存入了MongoDB数据库。

 如果运行过程中出现了下面这种错误,是因为MongoDB服务器没有开启,解决方法就是在CMD中cd到mongodb/bin目录下,执行命令 mongod --dbpath "e:\mongodb\data"(将路径换成你的mongodb安装路径)就可以了,注意不要把命令窗口关闭,然后就可以进行MongoDB数据库的相关操作了。
如果运行过程中出现了下面这种错误,是因为MongoDB服务器没有开启,解决方法就是在CMD中cd到mongodb/bin目录下,执行命令 mongod --dbpath "e:\mongodb\data"(将路径换成你的mongodb安装路径)就可以了,注意不要把命令窗口关闭,然后就可以进行MongoDB数据库的相关操作了。
pymongo.errors.ServerSelectionTimeoutError: localhost:27017: [WinError 10061] 由于目标计算机积极拒绝,无法连接。