简单型
1:linux中内核空间及用户空间的区别?用户空间与内核通信方式有哪些?
A.INTRODUCTION (32位系统)
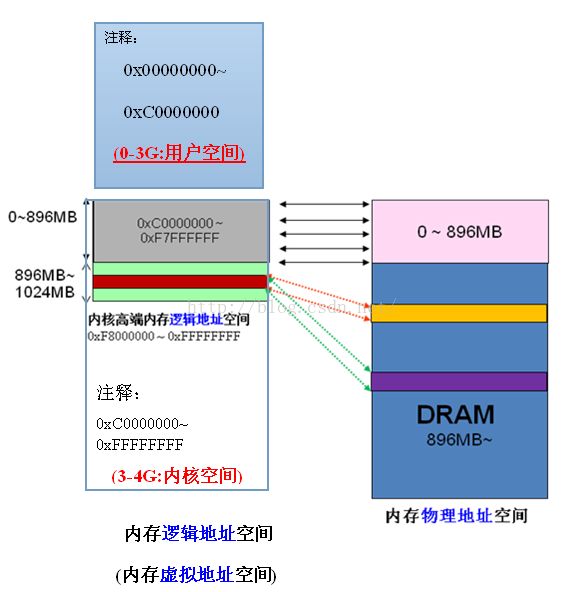
Linux 简化了分段机制,使得虚拟地址(逻辑地址)与线性地址总是一致,因此,Linux的虚拟地址空间也为0~4G(2^32)。
Linux内核将这4G字节的空间分为两部分。将最高的 1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为“内核空间”。而将较低的3G字节(从虚拟地址 0x00000000到0xBFFFFFFF),供各个进程使用,称为“用户空间“。因为每个进程可以通过系统调用进入内核,因此,Linux内核由系统 内的所有进程共享。于是,从具体进程的角度来看,每个进程可以拥有4G字节的虚拟空间。

|
*进程寻址空间0~4G
*进程在用户态只能访问0~3G,只有进入内核态才能访问3G~4G
*进程通过系统调用进入内核态
*每个进程虚拟空间的3G~4G部分是相同的
*进程从用户态进入内核态不会引起CR3的改变但会引起堆栈的改变 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
关于虚拟内核空间(逻辑地址)到物理空间的映射:
当内核模块代码或线程访问内存时,代码中的内存地址都为逻辑地址,而对应到真正的物理内存地址,需要地址一对一的映射,如逻辑地址0xc0000003对应的物理地址为0×3,0xc0000004对应的物理地址为0×4,… …,逻辑地址与物理地址对应的关系为
物理地址 = 逻辑地址 – 0xC0000000
| 逻辑地址 |
物理内存地址 |
| 0xc0000000 |
0×0 |
| 0xc0000001 |
0×1 |
| 0xc0000002 |
0×2 |
| 0xc0000003 |
0×3 |
| … |
… |
| 0xe0000000 |
0×20000000 |
| … |
… |
| 0xffffffff |
0×40000000 ?? |
对内核空间来说,其地址映射是很简单 的线性映射,0xC0000000就是物理地址与线性地址之间的位移量,在Linux代码中就叫做PAGE_OFFSET。
B.outline
一、Linux用户空间与内核空间
refer: http://blog.chinaunix.net/uid-15007890-id-3415331.html
二、Linux进程地址空间的一步步探究
refer:http://soft.chinabyte.com/os/51/12324551.shtml
C.contents
一、Linux用户空间与内核空间
Linux 操作系统和驱动程序运行在内核空间,应用程序运行在用户空间,两者不能简单地使用指针传递数据,因为Linux使用的虚拟内存机制,用户空间的数据可能被换出,当内核空间使用用户空间指针时,对应的数据可能不在内存中。
我们知道,linux操作系统每个进程的地址空间都是独立的,其实这里的独立说得是物理空间上得独立。
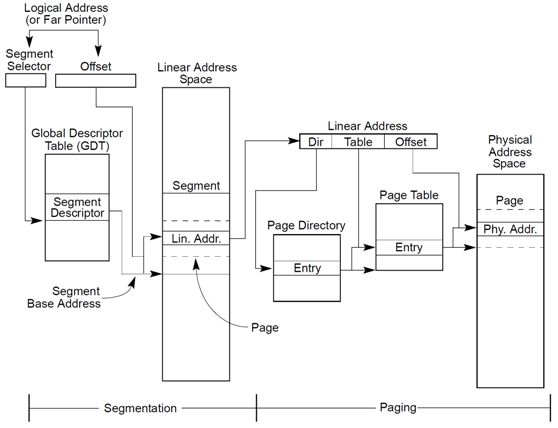
1. Linux内核地址映射模型
x86 CPU采用了段页式地址映射模型。进程代码中的地址为逻辑地址,经过段页式地址映射后,才真正访问物理内存。
段页式机制如下图。
2.Linux内核地址空间划分
通常32位Linux内核地址空间划分0~3G为用户空间,3~4G为内核空间。注意这里是32位内核地址空间划分,64位内核地址空间划分是不同的。
3.Linux内核高端内存的由来
当内核模块代码或线程访问内存时,代码中的内存地址都为逻辑地址,而对应到真正的物理内存地址,需要地址一对一的映射,如逻辑地址0xc0000003对应的物理地址为0×3,0xc0000004对应的物理地址为0×4,… …,逻辑地址与物理地址对应的关系为
物理地址 = 逻辑地址 – 0xC0000000
| 逻辑地址 |
物理内存地址 |
| 0xc0000000 |
0×0 |
| 0xc0000001 |
0×1 |
| 0xc0000002 |
0×2 |
| 0xc0000003 |
0×3 |
| … |
… |
| 0xe0000000 |
0×20000000 |
| … |
… |
| 0xffffffff |
0×40000000 ?? |
假 设按照上述简单的地址映射关系,那么内核逻辑地址空间访问为0xc0000000 ~ 0xffffffff,那么对应的物理内存范围就为0×0 ~ 0×40000000,即只能访问1G物理内存。若机器中安装8G物理内存,那么内核就只能访问前1G物理内存,后面7G物理内存将会无法访问,因为内核 的地址空间已经全部映射到物理内存地址范围0×0 ~ 0×40000000。即使安装了8G物理内存,那么物理地址为0×40000001的内存,内核该怎么去访问呢?代码中必须要有内存逻辑地址 的,0xc0000000 ~ 0xffffffff的地址空间已经被用完了,所以无法访问物理地址0×40000000以后的内存。
显 然不能将内核地址空间0xc0000000 ~ 0xfffffff全部用来简单的地址映射。因此x86架构中将内核地址空间划分三部分:ZONE_DMA、ZONE_NORMAL和 ZONE_HIGHMEM。ZONE_HIGHMEM即为高端内存,这就是内存高端内存概念的由来。
在x86结构中,三种类型的区域如下:
ZONE_DMA 内存开始的16MB
ZONE_NORMAL 16MB~896MB
ZONE_HIGHMEM 896MB ~ 结束
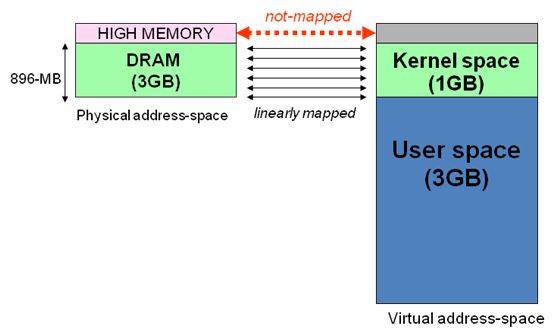
4.Linux内核高端内存的理解
前 面我们解释了高端内存的由来。 Linux将内核地址空间划分为三部分ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM,高端内存HIGH_MEM地址空间范围为 0xF8000000 ~ 0xFFFFFFFF(896MB~1024MB)。那么如内核是如何借助128MB高端内存地址空间是如何实现访问可以所有物理内存?
当内核想访问高于896MB物理地址内存时,从0xF8000000 ~ 0xFFFFFFFF地址空间范围内找一段相应大小空闲的逻辑地址空间,借用一会。借用这段逻辑地址空间,建立映射到想访问的那段物理内存(即填充内核PTE页面表),临时用一会,用完后归还。这样别人也可以借用这段地址空间访问其他物理内存,实现了使用有限的地址空间,访问所有所有物理内存。如下图。

例 如内核想访问2G开始的一段大小为1MB的物理内存,即物理地址范围为0×80000000 ~ 0x800FFFFF。访问之前先找到一段1MB大小的空闲地址空间,假设找到的空闲地址空间为0xF8700000 ~ 0xF87FFFFF,用这1MB的逻辑地址空间映射到物理地址空间0×80000000 ~ 0x800FFFFF的内存。映射关系如下:
| 逻辑地址 |
物理内存地址 |
| 0xF8700000 |
0×80000000 |
| 0xF8700001 |
0×80000001 |
| 0xF8700002 |
0×80000002 |
| … |
… |
| 0xF87FFFFF |
0x800FFFFF |
当内核访问完0×80000000 ~ 0x800FFFFF物理内存后,就将0xF8700000 ~ 0xF87FFFFF内核线性空间释放。这样其他进程或代码也可以使用0xF8700000 ~ 0xF87FFFFF这段地址访问其他物理内存。
从上面的描述,我们可以知道高端内存的最基本思想:借一段地址空间,建立临时地址映射,用完后释放,达到这段地址空间可以循环使用,访问所有物理内存。
看到这里,不禁有人会问:万一有内核进程或模块一直占用某段逻辑地址空间不释放,怎么办?若真的出现的这种情况,则内核的高端内存地址空间越来越紧张,若都被占用不释放,则没有建立映射到物理内存都无法访问了。
在 香港尖沙咀有些写字楼,洗手间很少且有门锁的。客户要去洗手间的话,可以向前台拿钥匙,方便完后,把钥匙归还到前台。这样虽然只有一个洗 手间,但可以满足所有客户去洗手间的需求。要是某个客户一直占用洗手间、钥匙不归还,那么其他客户都无法上洗手间了。Linux内核高端内存管理的思想类 似。
5.Linux内核高端内存的划分
内核将高端内存划分为3部分:VMALLOC_START~VMALLOC_END、KMAP_BASE~FIXADDR_START和FIXADDR_START~4G。

对 于高端内存,可以通过 alloc_page() 或者其它函数获得对应的 page,但是要想访问实际物理内存,还得把 page 转为线性地址才行(为什么?想想 MMU 是如何访问物理内存的),也就是说,我们需要为高端内存对应的 page 找一个线性空间,这个过程称为高端内存映射。
对应高端内存的3部分,高端内存映射有三种方式:
映射到”内核动态映射空间”(noncontiguous memory allocation)
这种方式很简单,因为通过 vmalloc() ,在”内核动态映射空间”申请内存的时候,就可能从高端内存获得页面(参看 vmalloc 的实现),因此说高端内存有可能映射到”内核动态映射空间”中。
持久内核映射(permanent kernel mapping)
如果是通过 alloc_page() 获得了高端内存对应的 page,如何给它找个线性空间?
内核专门为此留出一块线性空间,从 PKMAP_BASE 到 FIXADDR_START ,用于映射高端内存。在 2.6内核上,这个地址范围是 4G-8M 到 4G-4M 之间。这个空间起叫”内核永久映射空间”或者”永久内核映射空间”。这个空间和其它空间使用同样的页目录表,对于内核来说,就是 swapper_pg_dir,对普通进程来说,通过 CR3 寄存器指向。通常情况下,这个空间是 4M 大小,因此仅仅需要一个页表即可,内核通过来 pkmap_page_table 寻找这个页表。通过 kmap(),可以把一个 page 映射到这个空间来。由于这个空间是 4M 大小,最多能同时映射 1024 个 page。因此,对于不使用的的 page,及应该时从这个空间释放掉(也就是解除映射关系),通过 kunmap() ,可以把一个 page 对应的线性地址从这个空间释放出来。
临时映射(temporary kernel mapping)
内核在 FIXADDR_START 到 FIXADDR_TOP 之间保留了一些线性空间用于特殊需求。这个空间称为”固定映射空间”在这个空间中,有一部分用于高端内存的临时映射。
这块空间具有如下特点:
(1)每个 CPU 占用一块空间
(2)在每个 CPU 占用的那块空间中,又分为多个小空间,每个小空间大小是 1 个 page,每个小空间用于一个目的,这些目的定义在 kmap_types.h 中的 km_type 中。
当要进行一次临时映射的时候,需要指定映射的目的,根据映射目的,可以找到对应的小空间,然后把这个空间的地址作为映射地址。这意味着一次临时映射会导致以前的映射被覆盖。通过 kmap_atomic() 可实现临时映射。
6. 常见问题:
1、用户空间(进程)是否有高端内存概念?
用户进程没有高端内存概念。只有在内核空间才存在高端内存。用户进程最多只可以访问3G物理内存,而内核进程可以访问所有物理内存。
2、64位内核中有高端内存吗?
目前现实中,64位Linux内核不存在高端内存,因为64位内核可以支持超过512GB内存。若机器安装的物理内存超过内核地址空间范围,就会存在高端内存。
3、用户进程能访问多少物理内存?内核代码能访问多少物理内存?
32位系统用户进程最大可以访问3GB,内核代码可以访问所有物理内存。
64位系统用户进程最大可以访问超过512GB,内核代码可以访问所有物理内存。
4、高端内存和物理地址、逻辑地址、线性地址的关系?
高端内存只和逻辑地址有关系,和逻辑地址、物理地址没有直接关系。
5、为什么不把所有的地址空间都分配给内核?
若把所有地址空间都给内存,那么用户进程怎么使用内存?怎么保证内核使用内存和用户进程不起冲突?
(1)让我们忽略Linux对段式内存映射的支持。 在保护模式下,我们知道无论CPU运行于用户态还是核心态,CPU执行程序所访问的地址都是虚拟地址,MMU 必须通过读取控制寄存器CR3中的值作为当前页面目录的指针,进而根据分页内存映射机制(参看相关文档)将该虚拟地址转换为真正的物理地址才能让CPU真 正的访问到物理地址。
(2)对于32位的Linux,其每一个进程都有4G的寻址空间,但当一个进程访问其虚拟内存空间中的某个地址时又是怎样实现不与其它进程的虚拟空间混淆 的呢?每个进程都有其自身的页面目录PGD,Linux将该目录的指针存放在与进程对应的内存结构task_struct.(struct mm_struct)mm->pgd中。每当一个进程被调度(schedule())即将进入运行态时,Linux内核都要用该进程的PGD指针设 置CR3(switch_mm())。
(3)当创建一个新的进程时,都要为新进程创建一个新的页面目录PGD,并从内核的页面目录swapper_pg_dir中复制内核区间页面目录项至新建进程页面目录PGD的相应位置,具体过程如下:
do_fork() --> copy_mm() --> mm_init() --> pgd_alloc() --> set_pgd_fast() --> get_pgd_slow() --> memcpy(&PGD + USER_PTRS_PER_PGD, swapper_pg_dir + USER_PTRS_PER_PGD, (PTRS_PER_PGD - USER_PTRS_PER_PGD) * sizeof(pgd_t))
这样一来,每个进程的页面目录就分成了两部分,第一部分为“用户空间”,用来映射其整个进程空间(0x0000 0000-0xBFFF FFFF)即3G字节的虚拟地址;第二部分为“系统空间”,用来映射(0xC000 0000-0xFFFF FFFF)1G字节的虚拟地址。可以看出Linux系统中每个进程的页面目录的第二部分是相同的,所以从进程的角度来看,每个进程有4G字节的虚拟空间, 较低的3G字节是自己的用户空间,最高的1G字节则为与所有进程以及内核共享的系统空间。
(4)现在假设我们有如下一个情景:
在进程A中通过系统调用sethostname(const char *name,seze_t len)设置计算机在网络中的“主机名”.
在该情景中我们势必涉及到从用户空间向内核空间传递数据的问题,name是用户空间中的地址,它要通过系统调用设置到内核中的某个地址中。让我们看看这个 过程中的一些细节问题:系统调用的具体实现是将系统调用的参数依次存入寄存器ebx,ecx,edx,esi,edi(最多5个参数,该情景有两个 name和len),接着将系统调用号存入寄存器eax,然后通过中断指令“int 80”使进程A进入系统空间。由于进程的CPU运行级别小于等于为系统调用设置的陷阱门的准入级别3,所以可以畅通无阻的进入系统空间去执行为int 80设置的函数指针system_call()。由于system_call()属于内核空间,其运行级别DPL为0,CPU要将堆栈切换到内核堆栈,即 进程A的系统空间堆栈。我们知道内核为新建进程创建task_struct结构时,共分配了两个连续的页面,即8K的大小,并将底部约1k的大小用于 task_struct(如#define alloc_task_struct() ((struct task_struct *) __get_free_pages(GFP_KERNEL,1))),而其余部分内存用于系统空间的堆栈空间,即当从用户空间转入系统空间时,堆栈指针 esp变成了(alloc_task_struct()+8192),这也是为什么系统空间通常用宏定义current(参看其实现)获取当前进程的 task_struct地址的原因。每次在进程从用户空间进入系统空间之初,系统堆栈就已经被依次压入用户堆栈SS、用户堆栈指针ESP、EFLAGS、 用户空间CS、EIP,接着system_call()将eax压入,再接着调用SAVE_ALL依次压入ES、DS、EAX、EBP、EDI、ESI、 EDX、ECX、EBX,然后调用sys_call_table+4*%EAX,本情景为sys_sethostname()。
(5)在sys_sethostname()中,经过一些保护考虑后,调用copy_from_user(to,from,n),其中to指向内核空间 system_utsname.nodename,譬如0xE625A000,from指向用户空间譬如0x8010FE00。现在进程A进入了内核,在 系统空间中运行,MMU根据其PGD将虚拟地址完成到物理地址的映射,最终完成从用户空间到系统空间数据的复制。准备复制之前内核先要确定用户空间地址和 长度的合法性,至于从该用户空间地址开始的某个长度的整个区间是否已经映射并不去检查,如果区间内某个地址未映射或读写权限等问题出现时,则视为坏地址, 就产生一个页面异常,让页面异常服务程序处理。过程如 下:copy_from_user()->generic_copy_from_user()->access_ok()+__copy_user_zeroing().
二、Linux进程地址空间的一步步探究
2012-05-03 00:00中国IT实验室佚名
关键字:Linux
我们知道,在32位机器上linux操作系统中的进程的地址空间大小是4G,其中0-3G是用户空间,3G-4G是内核空间。其实,这个4G的地址空间是不存在的,也就是我们所说的虚拟内存空间。
(我们知道,linux操作系统每个进程的地址空间都是独立的,其实这里的独立说得是物理空间上得独立。)
那虚拟内存空间是什么呢,它与实际物理内存空间又是怎样对应的呢,为什么有了虚拟内存技术,我们就能运行比实际物理内存大的应用程序,它是怎么做到的呢?()
呵呵,这一切的一切都是个迷呀,下面我们就一步一步解开心中的谜团吧!
我们来看看,当我们写好一个应用程序,编译后它都有什么东东?
例如:
用命令size a.out会得到:
其中text是放的是代码,data放的是初始化过的全局变量或静态变量,bss放的是未初始化的全局变量或静态变量
由于历史原因,C程序一直由下列几部分组成:
A.正文段。这是由cpu执行的机器指令部分。通常,正文段是可共享的,所以即使是经常执行的程序(如文本编辑程序、C编译程序、shell等)在存储器中也只需要有一个副本,另外,正文段常常是只读的,以防止程序由于意外事故而修改器自身的指令。
B.初始化数据段。通常将此段称为数据段,它包含了程序中需赋初值的变量。例如,C程序中任何函数之外的说明:
int maxcount = 99;(全局变量)
C.非初始化数据段。通常将此段称为bss段,这一名称来源于早期汇编程序的一个操作,意思是"block started by symbol",在程序开始执行之前,内核将此段初始化为0。函数外的说明:
long sum[1000];
使此变量存放在非初始化数据段中。
D.栈。自动变量以及每次函数调用时所需保存的信息都存放在此段中。每次函数调用时,其返回地址、以及调用者的环境信息(例如某些机器寄存器)都存放在栈中。然后,新被调用的函数在栈上为其自动和临时变量分配存储空间。通过以这种方式使用栈,C函数可以递归调用。
E.堆。通常在堆中进行动态存储分配。由于历史上形成的惯例,堆位于非初始化数据段顶和栈底之间。
从上图我们看到栈空间是下增长的,堆空间是从下增长的,他们会会碰头呀?一般不会,因为他们之间间隔很大,如:
#include
#include
int bss_var;
int data_var0 = 1;
int main()
{
printf("Test location:\n");
printf("\tAddress of main(Code Segment):%p\n",main);
printf("_____________________________________\n");
int stack_var0 = 2;
printf("Stack location:\n");
printf("\tInitial end of stack:%p\n",&stack_var0);
int stack_var1 = 3;
printf("\tNew end of stack:%p\n",&stack_var1);
printf("_____________________________________\n");
printf("Data location:\n");
printf("\tAddress of data_var(Data Segment):%p\n",&data_var0);
static int data_var1 = 4;
printf("\tNew end of data_var(Data Segment):%p\n",&data_var1);
printf("_____________________________________\n");
printf("BSS location:\n");
printf("\tAddress of bss_var:%p\n",&bss_var);
printf("_____________________________________\n");
printf("Heap location:\n");
char *p = (char *)malloc(10);
printf("\tAddress of head_var:%p\n",p);
return 0;
}
运行结果如下:
呵呵,这里我们看到地址了,这个地址是虚拟地址,这些地址时怎么来的呢?其实在我们编译的时候,
这些地址就已经确定了,如下图中红线。
也就是说,我们不论我们运行a.out程序多少次这些地址都是一样的。我们知道,linux操作系统每个进程的地址空间都是独立的,其实这里的独立说得是物理空间上得独立。那相同的虚拟地址,不同的物理地址,他们之间是怎样联系起来的呢?我们继续探究…
在linux操作系统中,每个进程都通过一个task_struct的结构体描叙,每个进程的地址空间都通过一个mm_struct描叙,c语言中的每个段空间都通过vm_area_struct表示,他们关系如下 :
当运行一个程序时,操作系统需要创建一个进程,这个进程和程序之间都干了些什么呢?
当一个程序被执行时,该程序的内容必须被放到进程的虚拟地址空间,对于可执行程序的共享库也是如此。可执行程序并非真正读到物理内存中,而只是链接到进程的虚拟内存中。
当一个可执行程序映射到进程虚拟地址空间时,一组vm_area_struct数据结构将被产生。每个vm_area_struct数据结构表示可执行印象的一部分;是可执行代码,或是初始化的数据,以及未初始化的数据等。
linux操作系统是通过sys_exec对可执行文件进行映射以及读取的,有如下几步:
1.创建一组vm_area_struct
2.圈定一个虚拟用户空间,将其起始结束地址(elf段中已设置好)保存到vm_start和vm_end中。
3.将磁盘file句柄保存在vm_file中
4.将对应段在磁盘file中的偏移值(elf段中已设置好)保存在vm_pgoff中;
5.将操作该磁盘file的磁盘操作函数保存在vm_ops中
注意:这里没有对应 的页目录表项创建页表,更不存在设置页表项了。
假设现在程序中有一条指令需要读取上面vm_start--vm_end之间的某内容
例如:mov [0x08000011],%eax,那么将会执行如下序列:
1.cpu依据CR3(current->pgd)找到0x08000011地址对应的pgd[i],由于该pgd[i]内容保持为初始化状态即为0,导致cpu异常.
2.do_page_fault被调用,在该函数中,为pgd[i]在内存中分配一个页表,并让该表项指向它,如下图所示:
注意:这里i为0x08000011高10位,j为其中间10位,此时pt表项全部为0(pte[j]也为0);
3.为pte[j]分配一个真正的物理内存页面,依据vm_area_struct中的vm_file、vm_pgoff和vm_ops,调用filemap_nopage将磁盘file中vm_pgoff偏移处的内容读入到该物理页面中,如下图所示:
①。分配物理内存页面;
②。从磁盘文件中将内容读取到物理内存页面中
从上面我们可以知道,在进程创建的过程中,程序内容被映射到进程的虚拟内存空间,为了让一个很大的程序在有限的物理内存空间运行,我们可以把这个程序的开始部分先加载到物理内存空间运行,因为操作系统处理的是进程的虚拟地址,如果在进行虚拟到物理地址的转换工程中,发现物理地址不存在时,这个时候就会发生缺页异常(nopage),接着操作系统就会把磁盘上还没有加载到内存中的数据加载到物理内存中,对应的进程页表进行更新。也许你会问,如果此时物理内存满了,操作系统将如何处理?
下面我们看看linux操作系统是如何处理的:
如果一个进程想将一个虚拟页装入物理内存,而又没有可使用的空闲物理页,操作系统就必须淘汰物理内存中的其他页来为此页腾出空间。
在linux操作系统中,物理页的描叙如下:
struct mem_map
{
1.本页使用计数,当该页被许多进程共享时计数将大于1.
2.age描叙本页的年龄,用来判断该页是否为淘汰或交换的好候选
3.map_nr描叙物理页的页帧号
}
如果从物理内存中被淘汰的页来自于一个映像或数据文件,并且还没有被写过,则该页不必保存,它可以丢掉。如果有进程在需要该页时就可以把它从映像或数据文件中取回内存。
然而,如果该页被修改过,操作系统必须保留该页的内容以便晚些时候在被访问。这种页称为"脏(dirty)页",当它被从内存中删除时,将被保存在一个称为交换文件的特殊文件中。
相对于处理器和物理内存的速度,访问交换文件要很长时间,操作系统必须在将页写到磁盘以及再次使用时取回内存的问题上花费心机。
如果用来决定哪一页被淘汰或交换的算法不够高效的话,就可能出现称为"抖动"的情况。在这种情况下,页面总是被写到磁盘又读回来,操作系统忙于此而不能进行真正的工作。
linux使用"最近最少使用(Least Recently Used ,LRU)"页面调度技巧来公平地选择哪个页可以从系统中删除。这种设计系统中每个页都有一个"年龄",年龄随页面被访问而改变。页面被访问越多它越年轻;被访问越少越老。年老的页是用于交换的最佳候选页。
Linux将物理内存按固定大小的页面(一般为4K)划分内存,在内核初始化时,会建立一个全局struct page结构数组mem_map[ ]。如系统中有76G物理内存,则物理内存页面数为76*1024*1024k/4K= 19922944个页面,mem_map[ ]数组大小19922944,即为数组中每个元素和物理内存页面一一对应,整个数组就代表着系统中的全部物理页面。 在服务器中,存在NUMA架构(如Nehalem、Romly等),Linux将NUMA中内存访问速度一致(如按照内存通道划分)的部分称为一个节点(Node),用struct pglist_data数据结构表示,通常使用时用它的typedef定义pg_data_t。系统中的每个结点都通过pgdat_list链表pg_data_t->node_next连接起来,该链接以NULL为结束标志。每个结点又进一步分为许多块,称为区域(zones)。区域表示内存中的一块范围。区域用struct zone_struct数据结构表示,它的typedef定义为zone_t。
每个区域(Zone)中有多个页面(Pages)组成。节点、区域、页面三者关系如下图。

1 节点(Node)
节点(Node),在linux中用struct pglist_data数据结构表示,通常使用时用它的typedef定义pg_data_t,数据结构定义在文件include/linux/mmzone.h中。当分配一个页面时,linux使用本地结点分配策略,从运行的CPU最近的一个结点分配。 因为进程倾向于在同一个CPU上运行,使用内存时也就更可能使用本结点的空间。对于象PC之类的UMA系统,仅有一个静态的pg_data_t结构,变量名为contig_page_data。遍历所有节点可以使用for_each_online_pgdat(pgdat)来实现。
2 区域(Zone)
节点(Node)下面可以有多个区域, 共有以下几种类型:
1)ZONE_DMA
它是低内存的一块区域,这块区域由标准工业架构(Industry Standard Architecture)设备使用,适合DMA内存。这部分区域大小和CPU架构有关,在x86架构中,该部分区域大小 限制为16MB。
2)ZONE_DMA32
该部分区域为适合支持32位地址总线的DMA内存空间。很显然,该部分仅在64位系统有效,在32位系统中,这部分区域为空。在x86-64架构中,这部分的区域范围为0~4GB。
3)ZONE_NORMAL
属于ZONE_NORMAL的内存被内核直接映射到线性地址。这部分区域仅表示可能存在这部分区域,如在64位系统中,若系统只有4GB物理内存,则所有的物理内存都属于 ZONE_DMA32,而ZONE_NORMAL区域为空。许多内核操作都仅在ZONE_NORMAL内存区域进行,所以这部分是系统性能关键的地 方。
4)ZONE_HIGHMEM
是系统中剩下的可用内存,但因为内核的地址空间有限,这部分内存不直接映射到内核。
在x86架构中内存有三种区域:ZONE_DMA,ONE_NORMAL,ZONE_HIGHMEM,不同类型的区域适合不同需要。在32位系统中结构中,1G(内核空间)/3G(用户空间) 地址空间划分时,三种类型的区域如下:
ZONE_DMA 内存开始的16MB
ZONE_NORMAL 16MB~896MB
ZONE_HIGHMEM 896MB ~ 结束
4G(内核空间)/4G(用户空间)地址空间划分时,三种类型区域划分为:
ZONE_DMA 内存开始的16MB
ZONE_NORMAL 16MB~3968MB
ZONE_HIGHMEM 3968MB ~ 结束
在64位Linux系统中,内存只有三个区域DMA、DMA32和NORMAL。
ZONE_DMA 内存开始的16MB
ZONE_DMA32 16MB~4GB
ZONE_NORMAL 4GB ~ 结束
下图是32位系统和64位系统对应的内存区域划分:

3 页面(Page)
系统内存由固定的块组成,称为页帧,每个页帧由struct page结构描述。内核在初始化时,会根据内存的大小计算出由多少页帧,每个页帧都会有一个page结构与之对应,这些 信息保存在全局数组变量mem_map中。mem_map通常存储在ZONE_NORMAL区域中, 在内存较小的机器中,会保存在加载内核镜像后的一片保留空间里。有多少个物理页面,就会有多个struct page结构,如系统安装128GB物理内存,struct page结构体大小为40字节,则mem_map[ ]数组就占用物理内存大小为128*1024*1024k/4k * 40 = 1280MB,即Linux内核要使用1280MB物理内存来保存mem_map[ ]数组,这部分内存是不可被使用的,因此 struct page结构体大小不能设计很大。
页面标志尤为重要,在内存分配与回收、I/O操作等重要内核活动过程中都会使用到页面标志。所有的标志在include/linux/page-flags.h中定义。下面解释一下重要的几个页面标志:
PG_locked:页面是否被锁住,若该位设置了该位,则不允许内核其他部分访问该页面。这用来防止内存管理过程中遇到的竞争条件,如当从硬盘读取数据到一个页面时,就不允许其他内核部分访问该页面,因为读数据的过程中,其他内核部分能访问的话,则读取到的数据是不完整的。
PG_error:I/O出错,且操作和页面有关,就设置该标志。
PG_referenced和PG_active:控制系统使用页面的活跃程度,这个信息对swap系统选择待交换出的页面非常重要。
PG_update:表示成功完成从块设备上读取一个页面的数据。该标志和块设备I/O操作有关。
PG_dirty:当内存页面中的数据和块设备上的数据不一致时,就设置该标志。在写数据到块设备时,为了提高将来的读性能,数据并不是立即回写到块设备上,而只是设置页面脏 标志,表示该页面数据需要回写。
PG_lru:该标志用来实现页面回收和交换。
PG_highmem:表示该页面为属于高端内存。
2:linux中内存划分及如何使用?虚拟地址及物理地址的概念及彼此之间的转化,高端内存概念?
3:linux中中断的实现机制,tasklet与workqueue的区别及底层实现区别?为什么要区分上半部和下半部?
Linux设备驱动编程中的中断与定时器处理
【正文】
一、基础知识
1、中断
所谓中断是指CPU在执行程序的过程中,出现了某些突发事件急待处理,CPU必须暂停执行当前的程序,转去处理突发事件,处理完毕后CPU又返回程序被中断的位置并继续执行。
2、中断的分类
1)根据中断来源分为:内部中断和外部中断。内部中断来源于CPU内部(软中断指令、溢出、语法错误等),外部中断来自CPU外部,由设备提出请求。
2)根据是否可被屏蔽分为:可屏蔽中断和不可屏蔽中断(NMI),被屏蔽的中断将不会得到响应。
3)根据中断入口跳转方法分为:向量中断和非向量中断。向量中断为不同的中断分配不同的中断号,非向量中断多个中断共享一个中断号,在软件中判断具体是哪个中断(非向量中断由软件提供中断服务程序入口地址)。
二、Linux中断处理程序架构
设备的中断会打断内核中正常调度和运行,系统对更高吞吐率的追求势必要求中断服务程序尽可能的短小(时间短),但是在大多数实际使用中,要完成的工作都是复杂的,它可能需要进行大量的耗时工作。
1、Linux中断处理中的顶半部和底半部机制
由于中断服务程序的执行并不存在于进程上下文,因此,要求中断服务程序的时间尽可能的短。 为了在中断执行事件尽可能短和中断处理需完成大量耗时工作之间找到一个平衡点,Linux将中断处理分为两个部分:顶半部(top half)和底半部(bottom half)。
 Linux中断处理机制
Linux中断处理机制
顶半部完成尽可能少的比较紧急的功能,它往往只是简单地读取寄存器中的中断状态并清除中断标志后进行“登记中断”的工作。“登记”意味着将底半部的处理程序挂载到该设备的底半部指向队列中去。底半部作为工作重心,完成中断事件的绝大多数任务。
a. 底半部可以被新的中断事件打断,这是和顶半部最大的不同,顶半部通常被设计成不可被打断
b. 底半部相对来说不是非常紧急的,而且相对比较耗时,不在硬件中断服务程序中执行。
c. 如果中断要处理的工作本身很少,所有的工作可在顶半部全部完成
三、中断编程
1、申请和释放中断
在Linux设备驱动中,使用中断的设备需要申请和释放相对应的中断,分别使用内核提供的 request_irq() 和 free_irq() 函数
a. 申请IRQ
typedef irqreturn_t (*irq_handler_t)(int irq, void *dev_id);
int request_irq(unsigned int irq, irq_handler_t handler, unsigned long irqflags, const char *devname, void *dev_id)
/* 参数:
** irq:要申请的硬件中断号
** handler:中断处理函数(顶半部)
** irqflags:触发方式及工作方式
** 触发:IRQF_TRIGGER_RISING 上升沿触发
** IRQF_TRIGGER_FALLING 下降沿触发
** IRQF_TRIGGER_HIGH 高电平触发
** IRQF_TRIGGER_LOW 低电平触发
** 工作:不写:快速中断(一个设备占用,且中断例程回调过程中会屏蔽中断)
** IRQF_SHARED:共享中断
** dev_id:在共享中断时会用到(中断注销与中断注册的此参数应保持一致)
** 返回值:成功返回 - 0 失败返回 - 负值(绝对值为错误码)
*/
b. 释放IRQ
void free_irq(unsigned int irq, void *dev_id);
/* 参数参见申请IRQ */
2、屏蔽和使能中断
void disable_irq(int irq); //屏蔽中短、立即返回
void disable_irq_nosync(int irq); //屏蔽中断、等待当前中断处理结束后返回
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
void enable_irq(int irq); //使能中断
全局中断使能和屏蔽函数(或宏)
屏蔽:
#define local_irq_save(flags) ...
void local irq_disable(void );
使能:
#define local_irq_restore(flags) ...
void local_irq_enable(void);
3、底半部机制
Linux实现底半部机制的的主要方式有 Tasklet、工作队列和软中断
a. Tasklet
Tasklet使用简单,只需要定义tasklet及其处理函数并将二者关联即可,例如:
void my_tasklet_func(unsigned long); /* 定义一个处理函数 */
DECLARE_TASKLET(my_tasklet, my_tasklet_func, data);
/* 定义一个名为 my_tasklet 的 struct tasklet 并将其与 my_tasklet_func 绑定,data为传入 my_tasklet_func的参数 */
只需要在顶半部中电泳 tasklet_schedule()函数就能使系统在适当的时候进行调度运行
tasklet_schedule(struct tasklet *xxx_tasklet);
tasklet使用模版
/* 定义 tasklet 和底半部函数并关联 */
void xxx_do_tasklet(unsigned long data);
DECLARE_TASKLET(xxx_tasklet, xxx_tasklet_func, data);
/* 中断处理底半部 */
void xxx_tasklet_func()
{
/* 中断处理具体操作 */
}
/* 中断处理顶半部 */
irqreturn xxx_interrupt(int irq, void *dev_id)
{
//do something
task_schedule(&xxx_tasklet);
//do something
return IRQ_HANDLED;
}
/* 设备驱动模块 init */
int __init xxx_init(void)
{
...
/* 申请设备中断 */
result = request_irq(xxx_irq, xxx_interrupt, IRQF_DISABLED, "xxx", NULL);
...
return 0;
}
module_init(xxx_init);
/* 设备驱动模块exit */
void __exit xxx_exit(void)
{
...
/* 释放中断 */
free_irq(xxx_irq, NULL);
}
module_exit(xxx_exit);
b. 工作队列 workqueue
工作队列与tasklet方法非常类似,使用一个结构体定义一个工作队列和一个底半部执行函数:
struct work_struct {
atomic_long_t data;
struct list_head entry;
work_func_t func;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
struct work_struct my_wq; /* 定义一个工作队列 */
void my_wq_func(unsigned long); /*定义一个处理函数 */
通过INIT_WORK()可以初始化这个工作队列并将工作队列与处理函数绑定(一般在模块初始化中使用):
void INIT_WORK(struct work_struct *my_wq, work_func_t);
/* my_wq 工作队列地址
** work_func_t 处理函数
*/
与tasklet_schedule_work ()对应的用于调度工作队列执行的函数为schedule_work()
工作队列使用模版
/* 定义工作队列和关联函数 */
struct work_struct xxx_wq;
void xxx_do_work(unsigned long);
/* 中断处理底半部 */
void xxx_work(unsigned long)
{
/* do something */
}
/* 中断处理顶半部 */
irqreturn_t xxx_interrupt(int irq, void *dev_id)
{
...
schedule_work(&xxx_wq);
...
return IRQ_HANDLED;
}
/* 设备驱动模块 init */
int __init xxx_init(void)
{
...
/* 申请设备中断 */
result = request_irq(xxx_irq, xxx_interrupt, IRQF_DISABLED, "xxx", NULL);
/* 初始化工作队列 */
INIT_WORK(&xxx_wq, xxx_do_work);
...
return 0;
}
module_init(xxx_init);
/* 设备驱动模块exit */
void __exit xxx_exit(void)
{
...
/* 释放中断 */
free_irq(xxx_irq, NULL);
}
module_exit(xxx_exit);
c. 软中断
软中断(softirq)也是一种传统的底半部处理机制,它的执行时机通常是顶半部返回的时候,tasklet的基于软中断实现的,因此也运行于软中断上下文。
在Linux内核中,用softirq_action结构体表征一个软中断,这个结构体中包含软中断处理函数指针和传递给该函数的参数。使用open_softirq()函数可以注册软中断对应的处理函数,而raise_softirq()函数可以触发一个软中断。
struct softirq_action
{
void (*action)(struct softirq_action *);
};
void open_softirq(int nr, void (*action)(struct softirq_action *)); /* 注册软中断 */
void raise_softirq(unsigned int nr); /* 触发软中断 */
local_bh_disable() 和 local_bh_enable() 是内核中用于禁止和使能软中断和tasklet底半部机制的函数。
softirq和tasklet都属于软中断,tasklet是softirq的特殊实现;
workqueue是普通的工作队列。
1、softirq
软中断支持SMP,同一个softirq可以在不同的CPU上同时运行,softirq必须是可重入的。软中断是在编译期间静态分配的,它不像tasklet那样能被动态的注册或去除。kernel/softirq.c中定义了一个包含32个softirq_action结构体的数组。每个被注册的软中断都占据该数组的一项。因此最多可能有32个软中断。2.6版本的内核中定义了六个软中断:HI_SOFTIRQ、TIMER_SOFTIRQ、NET_TX_SOFTIRQ、NET_RX_SOFTIRQ、 SCSI_SOFTIRQ、TASKLET_SOFTIRQ。
一般情况下,在硬件中断处理程序后都会试图调用do_softirq()函数,每个CPU都是通过执行这个函数来执行软中断服务的。由于软中断不能进入硬中断部分,且同一个CPU上软中断的执行是串行的,即不允许嵌套,因此,do_softirq()函数一开始就检查当前CPU是否已经正出在中断服务中,如果是则 do_softirq()函数立即返回。这是由do_softirq()函数中的 if (in_interrupt()) return; 保证的。
2、tasklet
引入tasklet,最主要的是考虑支持SMP,提高SMP多个cpu的利用率;不同的tasklet可以在不同的cpu上运行。tasklet可以理解为softirq的派生,所以它的调度时机和软中断一样。对于内核中需要延迟执行的多数任务都可以用tasklet来完成,由于同类tasklet本身已经进行了同步保护,所以使用tasklet比软中断要简单的多,而且效率也不错。 tasklet把任务延迟到安全时间执行的一种方式,在中断期间运行,即使被调度多次,tasklet也只运行一次,不过tasklet可以在SMP系统上和其他不同的tasklet并行运行。在SMP系统上,tasklet还被确保在第一个调度它的CPU上运行,因为这样可以提供更好的高速缓存行为,从而提高性能。
与一般的软中断不同,某一段tasklet代码在某个时刻只能在一个CPU上运行,但不同的tasklet代码在同一时刻可以在多个CPU上并发地执行。 Kernel/softirq.c中用tasklet_trylock()宏试图对当前要执行的tasklet(由指针t所指向)进行加锁,如果加锁成功(当前没有任何其他CPU正在执行这个tasklet),则用原子读函数atomic_read()进一步判断count成员的值。如果count为0,说明这个tasklet是允许执行的。如果tasklet_trylock()宏加锁不成功,或者因为当前tasklet的count值非0而不允许执行时,我们必须将这个tasklet重新放回到当前CPU的tasklet队列中,以留待这个CPU下次服务软中断向量TASKLET_SOFTIRQ时再执行。为此进行这样几步操作:
(1)先关 CPU中断,以保证下面操作的原子性。
(2)把这个tasklet重新放回到当前CPU的tasklet队列的首部;
(3)调用 __cpu_raise_softirq()函数在当前CPU上再触发一次软中断请求TASKLET_SOFTIRQ;
(4)开中断。
软中断和tasklet都是运行在中断上下文中,它们与任一进程无关,没有支持的进程完成重新调度。所以软中断和tasklet不能睡眠、不能阻塞,它们的代码中不能含有导致睡眠的动作,如减少信号量、从用户空间拷贝数据或手工分配内存等。也正是由于它们运行在中断上下文中,所以它们在同一个CPU上的执行是串行的,这样就不利于实时多媒体任务的优先处理。
3、workqueue
什么情况下使用工作队列,什么情况下使用tasklet。如果推后执行的任务需要睡眠,那么就选择工作队列。如果推后执行的任务不需要睡眠,那么就选择tasklet。另外,如果需要用一个可以重新调度的实体来执行你的下半部处理,也应该使用工作队列。它是唯一能在进程上下文运行的下半部实现的机制,也只有它才可以睡眠。这意味着在需要获得大量的内存时、在需要获取信号量时,在需要执行阻塞式的I/O操作时,它都会非常有用。如果不需要用一个内核线程来推后执行工作,那么就考虑使用tasklet。
*******************************************************************************************************
当前的2.6版内核中,有三种可能的选择:softirq、tasklet和work queue。 tasklet基于softirq实现,所以两者很相近。work queue与它们完全不同,它靠内核线程实现。
1、softirq
软中断支持SMP,同一个softirq可以在不同的CPU上同时运行,softirq必须是可重入的。软中断是在编译期间静态分配的,它不像tasklet那样能被动态的注册或去除。kernel/softirq.c中定义了一个包含32个 softirq_action结构体的数组。每个被注册的软中断都占据该数组的一项。因此最多可能有32个软中断。2.6版本的内核中定义了六个软中断:HI_SOFTIRQ、TIMER_SOFTIRQ、NET_TX_SOFTIRQ、NET_RX_SOFTIRQ、SCSI_SOFTIRQ、 TASKLET_SOFTIRQ。
软中断的特性:
1).一个软中断不会抢占另外一个软中断。
2).唯一可以抢占软中断的是中断处理程序。
3).其他软中断(包括相同类型的)可以在其他的处理其上同时执行。
4).一个注册的软中断必须在被标记后才能执行。
5).软中断不可以自己休眠(即调用可阻塞的函数或sleep等)。
6).索引号小的软中断在索引号大的软中断之前执行。
2、tasklet
引入tasklet,最主要的是考虑支持SMP,提高SMP多个cpu的利用率;两个相同的tasklet决不会同时执行。tasklet可以理解为softirq的派生,所以它的调度时机和软中断一样。对于内核中需要延迟执行的多数任务都可以用tasklet来完成,由于同类tasklet本身已经进行了同步保护,所以使用tasklet比软中断要简单的多,而且效率也不错。tasklet把任务延迟到安全时间执行的一种方式,在中断期间运行,即使被调度多次,tasklet也只运行一次,不过tasklet可以在SMP系统上和其他不同的tasklet并行运行。在SMP系统上,tasklet还被确保在第一个调度它的CPU上运行,因为这样可以提供更好的高速缓存行为,从而提高性能。
tasklet的特性:.不允许两个两个相同类型的tasklet同时执行,即使在不同的处理器上。
3、work queue
如果推后执行的任务需要睡眠,那么就选择工作队列。另外,如果需要用一个可以重新调度的实体来执行你的下半部处理,也应该使用工作队列。它是唯一能在进程上下文运行的下半部实现的机制,也只有它才可以睡眠。这意味着在需要获得大量的内存时、在需要获取信号量时,在需要执行阻塞式的I/O操作时,它都会非常有用。work queue造成的开销最大,因为它要涉及到内核线程甚至是上下文切换。这并不是说work queue的低效,但每秒钟有数千次中断,就像网络子系统时常经历的那样,那么采用其他的机制可能更合适一些。 尽管如此,针对大部分情况工作队列都能提供足够的支持。
工作队列特性:
1).工作队列会在进程上下文中执行!
2).可以阻塞。(前两种机制是不可以阻塞的)
3).可以被重新调度。(前两种只可以被中断处理程序打断)
4).使用工作队列的两种形式:
1>缺省工作者线程(works threads)
2>自建的工作者线程
5).在工作队列和内核其他部分之间使用锁机制就像在其他的进程上下文一样。
6).默认允许响应中断。
7).默认不持有任何锁。
4、softirq和tasklet共同点
软中断和tasklet都是运行在中断上下文中,它们与任一进程无关,没有支持的进程完成重新调度。所以软中断和tasklet不能睡眠、不能阻塞,它们的代码中不能含有导致睡眠的动作,如减少信号量、从用户空间拷贝数据或手工分配内存等。也正是由于它们运行在中断上下文中,所以它们在同一个CPU上的执行是串行的,这样就不利于实时多媒体任务的优先处理。
5、总结
表 1. 对下半部的比较
| 下半部 |
上下文 |
顺序执行保障 |
| 软中断 |
中断 |
没有 |
| Tasklet |
中断 |
同类型不能同时执行 |
| 工作队列 |
进程 |
没有(和进程上下文一样被调度) |
简单地说,一般的驱动程序的编写者需要做两个选择。 首先,你是不是需要一个可调度的实体来执行需要推后完成的工作――从根本上来说,有休眠的需要吗?要是有,工作队列就是你的惟一选择。 否则最好用tasklet。要是必须专注于性能的提高,那么就考虑softirq。
4:linux中断的响应执行流程?中断的申请及何时执行(何时执行中断处理函数)?
5:linux中的同步机制?spinlock与信号量的区别?
为了避免并发,防止竞争。内核提供了一组同步方法来提供对共享数据的保护。 我们的重点不是介绍这些方法的详细用法,而是强调为什么使用这些方法和它们之间的差别。
Linux 使用的同步机制可以说从2.0到2.6以来不断发展完善。从最初的原子操作,到后来的信号量,从大内核锁到今天的自旋锁。这些同步机制的发展伴随 Linux从单处理器到对称多处理器的过度;伴随着从非抢占内核到抢占内核的过度。锁机制越来越有效,也越来越复杂。
目前来说内核中原子操作多用来做计数使用,其它情况最常用的是两种锁以及它们的变种:一个是自旋锁,另一个是信号量。我们下面就来着重介绍一下这两种锁机制。
自旋锁
------------------------------------------------------
自旋锁是专为防止多处理器并发而引入的一种锁,它在内核中大量应用于中断处理等部分(对于单处理器来说,防止中断处理中的并发可简单采用关闭中断的方式,不需要自旋锁)。
自旋锁最多只能被一个内核任务持有,如果一个内核任务试图请求一个已被争用(已经被持有)的自旋锁,那么这个任务就会一直进行忙循环——旋转——等待锁重新可用。要是锁未被争用,请求它的内核任务便能立刻得到它并且继续进行。自旋锁可以在任何时刻防止多于一个的内核任务同时进入临界区,因此这种锁可有效地避免多处理器上并发运行的内核任务竞争共享资源。
事实上,自旋锁的初衷就是:在短期间内进行轻量级的锁定。一个被争用的自旋锁使得请求它的线程在等待锁重新可用的期间进行自旋(特别浪费处理器时间),所以自旋锁不应该被持有时间过长。如果需要长时间锁定的话, 最好使用信号量。
自旋锁的基本形式如下:
spin_lock(&mr_lock);
//临界区
spin_unlock(&mr_lock);
因为自旋锁在同一时刻只能被最多一个内核任务持有,所以一个时刻只有一个线程允许存在于临界区中。这点很好地满足了对称多处理机器需要的锁定服务。在单处 理器上,自旋锁仅仅当作一个设置内核抢占的开关。如果内核抢占也不存在,那么自旋锁会在编译时被完全剔除出内核。
简单的说,自旋锁在内核中主要用来防止多处理器中并发访问临界区,防止内核抢占造成的竞争。另外自旋锁不允许任务睡眠(持有自旋锁的任务睡眠会造成自死锁——因为睡眠有可能造成持有锁的内核任务被重新调度,而再次申请自己已持有的锁),它能够在中断上下文中使用。
死锁:假设有一个或多个内核任务和一个或多个资源,每个内核都在等待其中的一个资源,但所有的资源都已经被占用了。这便会发生所有内核任务都在相互等待, 但它们永远不会释放已经占有的资源,于是任何内核任务都无法获得所需要的资源,无法继续运行,这便意味着死锁发生了。自死琐是说自己占有了某个资源,然后 自己又申请自己已占有的资源,显然不可能再获得该资源,因此就自缚手脚了。
信号量
------------------------------------------------------
Linux中的信号量是一种睡眠锁。如果有一个任务试图获得一个已被持有的信号量时,信号量会将其推入等待队列,然后让其睡眠。这时处理器获得自由去执行 其它代码。当持有信号量的进程将信号量释放后,在等待队列中的一个任务将被唤醒,从而便可以获得这个信号量。
信号量的睡眠特性,使得信号量适用于锁会被长时间持有的情况;只能在进程上下文中使用,因为中断上下文中是不能被调度的;另外当代码持有信号量时,不可以再持有自旋锁。
信号量基本使用形式为:
static DECLARE_MUTEX(mr_sem);//声明互斥信号量
if(down_interruptible(&mr_sem))
//可被中断的睡眠,当信号来到,睡眠的任务被唤醒
//临界区
up(&mr_sem);
信号量和自旋锁区别
------------------------------------------------------
虽然听起来两者之间的使用条件复杂,其实在实际使用中信号量和自旋锁并不易混淆。注意以下原则:
如果代码需要睡眠——这往往是发生在和用户空间同步时——使用信号量是唯一的选择。由于不受睡眠的限制,使用信号量通常来说更加简单一些。如果需要在自旋 锁和信号量中作选择,应该取决于锁被持有的时间长短。理想情况是所有的锁都应该尽可能短的被持有,但是如果锁的持有时间较长的话,使用信号量是更好的选 择。另外,信号量不同于自旋锁,它不会关闭内核抢占,所以持有信号量的代码可以被抢占。这意味者信号量不会对影响调度反应时间带来负面影响。
自旋锁对信号量
------------------------------------------------------
需求 建议的加锁方法
低开销加锁 优先使用自旋锁
短期锁定 优先使用自旋锁
长期加锁 优先使用信号量
中断上下文中加锁 使用自旋锁
持有锁是需要睡眠、调度 使用信号量
将中断处理分成top half(cpu和外设之间的交互,获取状态,ack状态,收发数据等)和bottom half(后段的数据处理)已经深入人心,对于任何的OS都一样,将不那么紧急的事情推迟到bottom half中执行是OK的,具体如何推迟执行分成两种类型:有具体时间要求的(对应linux kernel中的低精度timer和高精度timer)和没有具体时间要求的。对于没有具体时间要求的又可以分成两种:
1、越快越好型,这种实际上是有性能要求的,除了中断top half可以抢占其执行,其他的进程上下文(无论该进程的优先级多么的高)是不会影响其执行的,一言以蔽之,在不影响中断延迟的情况下,OS会尽快处理。
2、随遇而安型。这种属于那种没有性能需求的,其调度执行依赖系统的调度器。
本质上讲,越快越好型的bottom half不应该太多,而且tasklet的callback函数不能执行时间过长,否则会产生进程调度延迟过大的现象,甚至是非常长而且不确定的延迟,对real time的系统会产生很坏的影响。
在linux kernel中,“越快越好型”有两种,softirq 和 tasklet,“随遇而安型”也有两种,workqueue 和threaded irq handler。
tasklet 特点:
1、tasklet可以动态分配,也可以静态分配,数量不限。
2、同一种 tasklet 在多个cpu上也不会并行执行,这使得程序员在撰写 tasklet function 的时候比较方便,减少了对并发的考虑(当然损失了性能)。
3、tasklet 在软件中断上下文中运行,所以 tasklet 代码必须是原子的。而工作队列函数在一个特殊内核进程上下文运行,有更多的灵活性,且能够休眠。
4、tasklet 执行的很快, 短时期, 并且在原子态,除了中断top half可以抢占其执行,其他的进程上下文(无论该进程的优先级多么的高)是不会影响其执行的。
tasklet 使用:
Tasklet 的使用比较简单,只需要定义tasklet及其处理函数并将两者关联
例子:
Void my_tasklet_func(unsigned long)
静态创建:static DECLARE_TASKLET(my_tasklet,my_tasklet_func,data)
动态创建:DECLARE_TASKLET(my_tasklet,my_tasklet_func,data)
代码 DECLARE_TASKLET 实现了定义名称为 my_tasklet 的 tasklet 并将其与 my_tasklet_func 这个函数绑定,而传入这个函数的参数为data。
需要调度 tasklet 的时候引用一个 tasklet_schedule() 函数就能使系统在适当的时候进行调度,如下所示
Tasklet_schedule(&my_tasklet)
6:linux中RCU原理?
7: linux中软中断的实现原理?
8:linux系统实现原子操作有哪些方法?
9:MIPS Cpu中空间地址是怎么划分的?如在uboot中如何操作设备的特定的寄存器?
10:linux 字符设备file与inode的理解
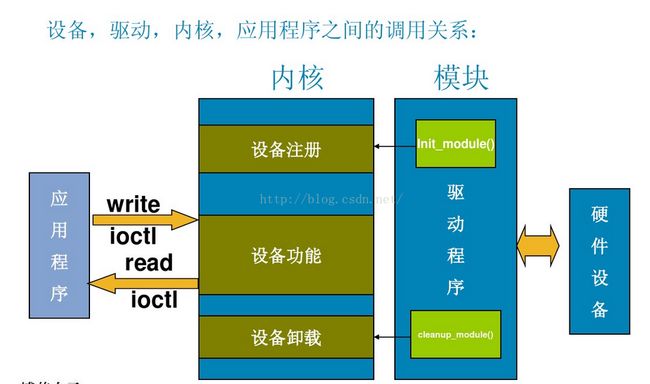
对于Linux系统中,一般字符设备和驱动之间的函数调用关系如下图所示

上图描述了用户空间应用程序通过系统调用来调用程序的过程。一般而言在驱动程序的设计中,会关系 struct file 和 struct inode 这两个结构体。
用户空间使用open()系统调用函数打开一个字符设备时( int fd = open("dev/demo", O_RDWR) )大致有以下过程:
- 在虚拟文件系统VFS中的查找对应与字符设备对应 struct inode节点
- 遍历字符设备列表(chardevs数组),根据inod节点中的 cdev_t设备号找到cdev对象
- 创建struct file对象(系统采用一个数组来管理一个进程中的多个被打开的设备,每个文件秒速符作为数组下标标识了一个设备对象)
- 初始化struct file对象,将 struct file对象中的 file_operations成员指向 struct cdev对象中的 file_operations成员(file->fops = cdev->fops)
- 回调file->fops->open函数
一、inode结构体
VFS inode 包含文件访问权限、属主、组、大小、生成时间、访问时间、最后修改时间等信息。它是Linux 管理文件系统的最基本单位,也是文件系统连接任何子目录、文件的桥梁。
内核使用inode结构体在内核内部表示一个文件。因此,它与表示一个已经打开的文件描述符的结构体(即file 文件结构)是不同的,我们可以使用多个file 文件结构表示同一个文件的多个文件描述符,但此时,所有的这些file文件结构全部都必须只能指向一个inode结构体。
inode结构体包含了一大堆文件相关的信息,但是就针对驱动代码来说,我们只要关心其中的两个域即可:
- dev_t i_rdev; 表示设备文件的结点,这个域实际上包含了设备号。
- struct cdev *i_cdev; struct cdev是内核的一个内部结构,它是用来表示字符设备的,当inode结点指向一个字符设备文件时,此域为一个指向inode结构的指针。
下面是源代码:


struct inode {
struct hlist_node i_hash;
struct list_head i_list;
struct list_head i_sb_list;
struct list_head i_dentry;
unsigned long i_ino;
atomic_t i_count;
unsigned int i_nlink;
uid_t i_uid;//inode拥有者id
gid_t i_gid;//inode所属群组id
dev_t i_rdev;//若是设备文件,表示记录设备的设备号
u64 i_version;
loff_t i_size;//inode所代表大少
#ifdef __NEED_I_SIZE_ORDERED
seqcount_t i_size_seqcount;
#endif
struct timespec i_atime;//inode最近一次的存取时间
struct timespec i_mtime;//inode最近一次修改时间
struct timespec i_ctime;//inode的生成时间
unsigned int i_blkbits;
blkcnt_t i_blocks;
unsigned short i_bytes;
umode_t i_mode;
spinlock_t i_lock;
struct mutex i_mutex;
struct rw_semaphore i_alloc_sem;
const struct inode_operations *i_op;
const struct file_operations *i_fop;
struct super_block *i_sb;
struct file_lock *i_flock;
struct address_space *i_mapping;
struct address_space i_data;
#ifdef CONFIG_QUOTA
struct dquot *i_dquot[MAXQUOTAS];
#endif
struct list_head i_devices;
union {
struct pipe_inode_info *i_pipe;
struct block_device *i_bdev;
struct cdev *i_cdev;//若是字符设备,对应的为cdev结构
};
};
inode的相关操作函数
/* 内核函数从inode中提取设备号 */
/* 提取主设备号 */
static inline unsigned imajor(const struct inode *inode)
{
return MAJOR(inode->i_rdev);
}
/* 提取次设备号 */
static inline unsigned iminor(const struct inode *inode)
{
return MINOR(inode->i_rdev);
}
二、file 文件结构体
在设备驱动中,这也是个非常重要的数据结构,必须要注意一点,这里的file与用户空间程序中的FILE指针是不同的,用户空间FILE是定义在C库中,从来不会出现在内核中。而struct file,却是内核当中的数据结构,因此,它也不会出现在用户层程序中。
file结构体指示一个已经打开的文件(设备对应于设备文件),其实系统中的每个打开的文件在内核空间都有一个相应的struct file结构体,它由内核在打开文件时创建,并传递给在文件上进行操作的任何函数,直至文件被关闭。如果文件被关闭,内核就会释放相应的数据结构。
在内核源码中,struct file要么表示为file,或者为filp(意指“file pointer”), 注意区分一点,file指的是struct file本身,而filp是指向这个结构体的指针。
下面是几个重要成员:
1、fmode_t f_mode;
此文件模式通过 FMODE_READ , FMODE_WRITE 识别了文件为可读的,可写的,或者是二者。在open或ioctl函数中可能需要检查此域以确认文件的读/写权限,你不必直接去检测读或写权限,因为在进行octl等操作时内核本身就需要对其权限进行检测。
2、 loff_t f_pos;
当前读写文件的位置。为64位。如果想知道当前文件当前位置在哪,驱动可以读取这个值而不会改变其位置。对read,write来说,当其接收到一个loff_t型指针作为其最后一个参数时,他们的读写操作便作更新文件的位置,而不需要直接执行filp ->f_pos操作。而
3、unsigned int f_flags;
文件标志,如 O_RDONLY , O_NONBLOCK 以及 O_SYNC 。在驱动中还可以检查O_NONBLOCK标志查看是否有非阻塞请求。其它的标志较少使用。特别地注意的是,读写权限的检查是使用f_mode而不是f_flog。所有的标量定义在头文件中
4、struct file_operations *f_op;
与文件相关的各种操作。当文件需要迅速进行各种操作时,内核分配这个指针作为它实现文件打开,读,写等功能的一部分。filp->f_op 其值从未被内核保存作为下次的引用,即你可以改变与文件相关的各种操作,这种方式效率非常高。
file_operation 结构体解析如下:Linux字符设备驱动file_operations
5、 void *private_data;
在驱动调用open方法之前,open系统调用设置此指针为NULL值。你可以很自由的将其做为你自己需要的一些数据域或者不管它,如,你可以将其指向一个分配好的数据,但是你必须记得在file struct被内核销毁之前在release方法中释放这些数据的内存空间。private_data用于在系统调用期间保存各种状态信息是非常有用的。
三、chardevs 数组
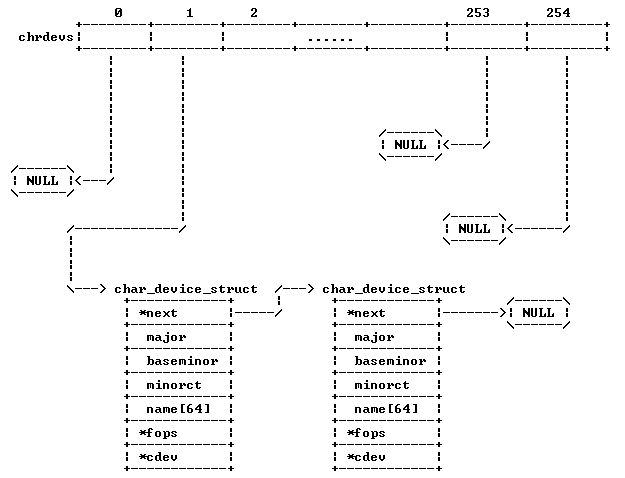
前面对用户层open()的分析提到,通过数据结构 struct inode{...} 中的 i_cdev 成员可以找到cdev,而所有的字符设备都在 chrdevs 数组中,chrdevs具体是什么样的呢
下面先看一下 chrdevs 的定义:
#define CHRDEV_MAJOR_HASH_SIZE 255
static DEFINE_MUTEX(chrdevs_lock);
static struct char_device_struct {
struct char_device_struct *next; // 结构体指针
unsigned int major; // 主设备号
unsigned int baseminor; // 次设备起始号
int minorct; // 次备号个数
char name[64];
struct cdev *cdev; /* will die */
} *chrdevs[CHRDEV_MAJOR_HASH_SIZE];// 只能挂255个字符主设备
可以看到全局数组 chrdevs 包含了255(CHRDEV_MAJOR_HASH_SIZE 的值)个 struct char_device_struct的元素,每一个对应一个相应的主设备号。
如果分配了一个设备号,就会创建一个 struct char_device_struct 的对象,并将其添加到 chrdevs 中;这样,通过chrdevs数组,我们就可以知道分配了哪些设备号。
相关函数,(这些函数在上篇已经介绍过,现在回顾一下:
register_chrdev_region( ) 分配指定的设备号范围
alloc_chrdev_region( ) 动态分配设备范围
他们都主要是通过调用函数 __register_chrdev_region() 来实现的;要注意,这两个函数仅仅是注册设备号!如果要和cdev关联起来,还要调用cdev_add()。
register_chrdev( )申请指定的设备号,并且将其注册到字符设备驱动模型中.
它所做的事情为:
- 注册设备号, 通过调用 __register_chrdev_region() 来实现
- 分配一个cdev, 通过调用 cdev_alloc() 来实现
- 将cdev添加到驱动模型中, 这一步将设备号和驱动关联了起来. 通过调用 cdev_add() 来实现
- 将第一步中创建的 struct char_device_struct 对象的 cdev 指向第二步中分配的cdev. 由于register_chrdev()是老的接口,这一步在新的接口中并不需要。
四、cdev 结构体
Linux内核中,使用 struct cdev 来描述一个字符设备
五、文件系统中对字符设备文件的访问
下面看一下上层应用open() 调用系统调用函数的过程
对于一个字符设备文件, 其inode->i_cdev 指向字符驱动对象cdev, 如果i_cdev为 NULL ,则说明该设备文件没有被打开.
由于多个设备可以共用同一个驱动程序.所以,通过字符设备的inode 中的i_devices 和 cdev中的list组成一个链表

首先,系统调用open打开一个字符设备的时候, 通过一系列调用,最终会执行到 chrdev_open
(最终是通过调用到def_chr_fops中的.open, 而def_chr_fops.open = chrdev_open. 这一系列的调用过程,本文暂不讨论)
int chrdev_open(struct inode * inode, struct file * filp)
chrdev_open()所做的事情可以概括如下:
1. 根据设备号(inode->i_rdev), 在字符设备驱动模型中查找对应的驱动程序, 这通过kobj_lookup() 来实现, kobj_lookup()会返回对应驱动程序cdev的kobject.
2. 设置inode->i_cdev , 指向找到的cdev.
3. 将inode添加到cdev->list 的链表中.
4. 使用cdev的ops 设置file对象的f_op
5. 如果ops中定义了open方法,则调用该open方法
6. 返回
执行完 chrdev_open()之后,file对象的f_op指向cdev的ops,因而之后对设备进行的read, write等操作,就会执行cdev的相应操作。
得到进程号:
asm/current.h
linux/sched.h
#define current get_current()
得到进程号:current->pid
得到进程名:current->comm
11.workqueue 理解
1. 什么是workqueue
Linux中的Workqueue机制就是为了简化内核线程的创建。通过调用workqueue的接口就能创建内核线程。并且可以根据当前系统CPU的个 数创建线程的数量,使得线程处理的事务能够并行化。workqueue是内核中实现简单而有效的机制,他显然简化了内核daemon的创建,方便了用户的 编程.
工作队列(workqueue)是另外一种将工作推后执行的形式.工作队列可以把工作推后,交由一个内核线程去执行,也就是说,这个下半部分可以在进程上下文中执行。最重要的就是工作队列允许被重新调度甚至是睡眠。
那么,什么情况下使用工作队列,什么情况下使用tasklet。如果推后执行的任务需要睡眠,那么就选择工作队列。如果推后执行的任务不需要睡眠,那么就 选择tasklet。另外,如果需要用一个可以重新调度的实体来执行你的下半部处理,也应该使用工作队列。它是唯一能在进程上下文运行的下半部实现的机 制,也只有它才可以睡眠。这意味着在需要获得大量的内存时、在需要获取信号量时,在需要执行阻塞式的I/O操作时,它都会非常有用。如果不需要用一个内核 线程来推后执行工作,那么就考虑使用tasklet。
2. 数据结构
我们把推后执行的任务叫做工作(work),描述它的数据结构为work_struct:
struct work_struct {
atomic_long_t data; /*工作处理函数func的参数*/
#define WORK_STRUCT_PENDING 0 /* T if work item pending execution */
#define WORK_STRUCT_STATIC 1 /* static initializer (debugobjects) */
#define WORK_STRUCT_FLAG_MASK (3UL)
#define WORK_STRUCT_WQ_DATA_MASK (~WORK_STRUCT_FLAG_MASK)
struct list_head entry; /*连接工作的指针*/
work_func_t func; /*工作处理函数*/
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
这些工作以队列结构组织成工作队列(workqueue),其数据结构为workqueue_struct:
struct workqueue_struct {
struct cpu_workqueue_struct *cpu_wq;
struct list_head list;
const char *name; /*workqueue name*/
int singlethread; /*是不是单线程 - 单线程我们首选第一个CPU -0表示采用默认的工作者线程event*/
int freezeable; /* Freeze threads during suspend */
int rt;
};
如果是多线程,Linux根据当前系统CPU的个数创建cpu_workqueue_struct 其结构体就是:
truct cpu_workqueue_struct {
spinlock_t lock;/*因为工作者线程需要频繁的处理连接到其上的工作,所以需要枷锁保护*/
struct list_head worklist;
wait_queue_head_t more_work;
struct work_struct *current_work; /*当前的work*/
struct workqueue_struct *wq; /*所属的workqueue*/
struct task_struct *thread; /*任务的上下文*/
} ____cacheline_aligned;
在该结构主要维护了一个任务队列,以及内核线程需要睡眠的等待队列,另外还维护了一个任务上下文,即task_struct。
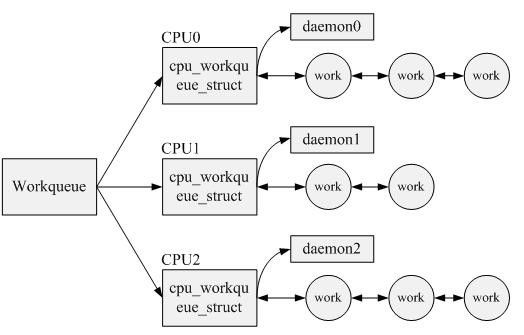
三者之间的关系如下:
3. 创建工作
3.1 创建工作queue
a. create_singlethread_workqueue(name)
该函数的实现机制如下图所示,函数返回一个类型为struct workqueue_struct的指针变量,该指针变量所指向的内存地址在函数内部调用kzalloc动态生成。所以driver在不再使用该work queue的情况下调用:
void destroy_workqueue(struct workqueue_struct *wq)来释放此处的内存地址。

图中的cwq是一per-CPU类型的地址空间。对于create_singlethread_workqueue而言,即使是对于多CPU系统,内核也 只负责创建一个worker_thread内核进程。该内核进程被创建之后,会先定义一个图中的wait节点,然后在一循环体中检查cwq中的 worklist,如果该队列为空,那么就会把wait节点加入到cwq中的more_work中,然后休眠在该等待队列中。
Driver调用queue_work(struct workqueue_struct *wq, struct work_struct *work)向wq中加入工作节点。work会依次加在cwq->worklist所指向的链表中。queue_work向 cwq->worklist中加入一个work节点,同时会调用wake_up来唤醒休眠在cwq->more_work上的 worker_thread进程。wake_up会先调用wait节点上的autoremove_wake_function函数,然后将wait节点从 cwq->more_work中移走。
worker_thread再次被调度,开始处理cwq->worklist中的所有work节点...当所有work节点处理完 毕,worker_thread重新将wait节点加入到cwq->more_work,然后再次休眠在该等待队列中直到Driver调用 queue_work...
b. create_workqueue
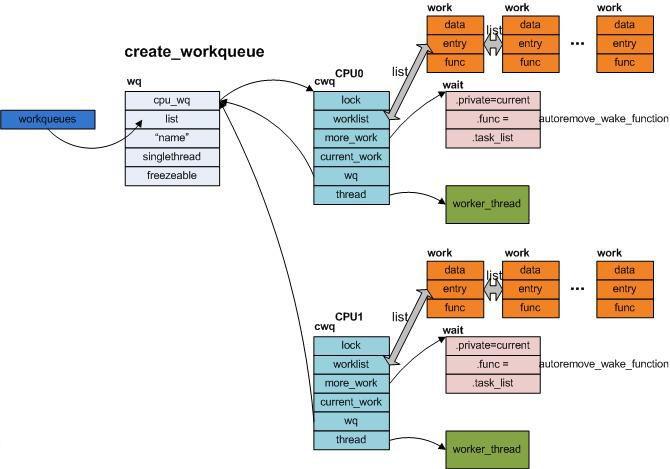
相对于create_singlethread_workqueue, create_workqueue同样会分配一个wq的工作队列,但是不同之处在于,对于多CPU系统而言,对每一个CPU,都会为之创建一个per- CPU的cwq结构,对应每一个cwq,都会生成一个新的worker_thread进程。但是当用queue_work向cwq上提交work节点时, 是哪个CPU调用该函数,那么便向该CPU对应的cwq上的worklist上增加work节点。
c.小结
当用户调用workqueue的初始化接口create_workqueue或者create_singlethread_workqueue对 workqueue队列进行初始化时,内核就开始为用户分配一个workqueue对象,并且将其链到一个全局的workqueue队列中。然后 Linux根据当前CPU的情况,为workqueue对象分配与CPU个数相同的cpu_workqueue_struct对象,每个 cpu_workqueue_struct对象都会存在一条任务队列。紧接着,Linux为每个cpu_workqueue_struct对象分配一个内 核thread,即内核daemon去处理每个队列中的任务。至此,用户调用初始化接口将workqueue初始化完毕,返回workqueue的指针。
workqueue初始化完毕之后,将任务运行的上下文环境构建起来了,但是具体还没有可执行的任务,所以,需要定义具体的work_struct对象。然后将work_struct加入到任务队列中,Linux会唤醒daemon去处理任务。
上述描述的workqueue内核实现原理可以描述如下:

3.2 创建工作
要使用工作队列,首先要做的是创建一些需要推后完成的工作。可以通过DECLARE_WORK在编译时静态地建该结构:
DECLARE_WORK(name,void (*func) (void *), void *data);
这样就会静态地创建一个名为name,待执行函数为func,参数为data的work_struct结构。
同样,也可以在运行时通过指针创建一个工作:
INIT_WORK(structwork_struct *work, woid(*func) (void *), void *data);
4. 调度
a. schedule_work
在大多数情况下, 并不需要自己建立工作队列,而是只定义工作, 将工作结构挂接到内核预定义的事件工作队列中调度, 在kernel/workqueue.c中定义了一个静态全局量的工作队列static struct workqueue_struct *keventd_wq;默认的工作者线程叫做events/n,这里n是处理器的编号,每个处理器对应一个线程。比如,单处理器的系统只有events /0这样一个线程。而双处理器的系统就会多一个events/1线程。
调度工作结构, 将工作结构添加到全局的事件工作队列keventd_wq,调用了queue_work通用模块。对外屏蔽了keventd_wq的接口,用户无需知道此 参数,相当于使用了默认参数。keventd_wq由内核自己维护,创建,销毁。这样work马上就会被调度,一旦其所在的处理器上的工作者线程被唤醒, 它就会被执行。
b. schedule_delayed_work(&work,delay);
有时候并不希望工作马上就被执行,而是希望它经过一段延迟以后再执行。在这种情况下,同时也可以利用timer来进行延时调度,到期后才由默认的定时器回调函数进行工作注册。延迟delay后,被定时器唤醒,将work添加到工作队列wq中。
工作队列是没有优先级的,基本按照FIFO的方式进行处理。
5. work queue API
1. create_workqueue用于创建一个workqueue队列,为系统中的每个CPU都创建一个内核线程。输入参数:
@name:workqueue的名称
2. create_singlethread_workqueue用于创建workqueue,只创建一个内核线程。输入参数:
@name:workqueue名称
3. destroy_workqueue释放workqueue队列。输入参数:
@ workqueue_struct:需要释放的workqueue队列指针
4. schedule_work调度执行一个具体的任务,执行的任务将会被挂入Linux系统提供的workqueue——keventd_wq输入参数:
@ work_struct:具体任务对象指针
5. schedule_delayed_work延迟一定时间去执行一个具体的任务,功能与schedule_work类似,多了一个延迟时间,输入参数:
@work_struct:具体任务对象指针
@delay:延迟时间
6. queue_work调度执行一个指定workqueue中的任务。输入参数:
@ workqueue_struct:指定的workqueue指针
@work_struct:具体任务对象指针
7. queue_delayed_work延迟调度执行一个指定workqueue中的任务,功能与queue_work类似,输入参数多了一个delay。
6. 示例
- //声明
- static struct workqueue_struct *mdp_pipe_ctrl_wq; /* mdp mdp pipe ctrl wq */
- static struct delayed_work mdp_pipe_ctrl_worker;
- mdp_pipe_ctrl_wq = create_singlethread_workqueue("mdp_pipe_ctrl_wq");//创建工作队列
- INIT_DELAYED_WORK(&mdp_pipe_ctrl_worker,mdp_pipe_ctrl_workqueue_handler);//delayed_work与task_func绑定。
- //处理函数
- static void mdp_pipe_ctrl_workqueue_handler(struct work_struct *work)
- {
- mdp_pipe_ctrl(MDP_MASTER_BLOCK, MDP_BLOCK_POWER_OFF, FALSE);
- }
- //开始调用工作队列,delay时间到了就执行处理函数。
- unsigned long mdp_timer_duration = (HZ/20); /* 50 msecond */
- /* send workqueue to turn off mdp power */
- queue_delayed_work(mdp_pipe_ctrl_wq,&mdp_pipe_ctrl_worker, mdp_timer_duration);
-
- /* cancel pipe ctrl worker */
- cancel_delayed_work(&mdp_pipe_ctrl_worker);
- /* for workder can't be cancelled... */
- flush_workqueue(mdp_pipe_ctrl_wq);
- /* for workder can't be cancelled... */
- flush_workqueue(mdp_pipe_ctrl_wq);
在driver 程序中许多很多情况需要设置延后执行的,这样工作队列就很好帮助我们实现。
复杂型:
1:linux中netfilter的实现机制?是如何实现对特定数据包进行处理(如过滤,NAT之类的)及HOOK点的注册?
2:linux中系统调用过程?如:应用程序中read()在linux中执行过程即从用户空间到内核空间?
3:linux内核的启动过程(源代码级)?
4:linux调度原理?
5:linux网络子系统的认识?
三: sample
1:二分法查找
2:大小端转化及判断
3: 二维数组最外边个元素之和?
4:特定比特位置0和1
5:字符串中的第一个和最后一个元素交换(字符串反转)?
6:linux driver 小例子
Linux设备驱动分为:字符设备、块设备和网络设备。原理图如下:
二、示例
示例主要转载自博客园的博客,见上。只是我采用的的Linux内核版本比那篇博文的新,有小许改动,粘贴代码如下:
内核版本:
ry@ubuntu:/$ uname -a
Linux ubuntu 3.16.0-30-generic #40~14.04.1-Ubuntu SMP Thu Jan 15 17:43:14 UTC 2015 x86_64 x86_64 x86_64 GNU/Linux
文件:hello_mod.c
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include "hello_mod_ioctl.h"
-
- #define MAJOR_NUM 250
- #define MINOR_NUM 0
- #define IN_BUF_LEN 256
- #define OUT_BUF_LEN 512
-
- MODULE_AUTHOR("Tishion");
- MODULE_DESCRIPTION("Hello_mod driver by tishion");
-
- static struct class * hello_class;
- static struct cdev hello_cdev;
- static dev_t devnum = 0;
- static char * modname = "hello_mod";
- static char * devicename = "hello";
- static char * classname = "hello_class";
-
- static int open_count = 0;
- static struct semaphore sem;
- static DEFINE_SPINLOCK(spin);
- static char * inbuffer = NULL;
- static char * outbuffer = NULL;
- static lang_t langtype;
-
- static int hello_mod_open(struct inode *, struct file *);
- static int hello_mod_release(struct inode *, struct file *);
- static ssize_t hello_mod_read(struct file *, char *, size_t, loff_t *);
- static ssize_t hello_mod_write(struct file *, const char *, size_t, loff_t *);
- static long hello_mod_ioctl(struct file *, unsigned int, unsigned long);
-
- struct file_operations hello_mod_fops =
- {
- .owner = THIS_MODULE,
- .open = hello_mod_open,
- .read = hello_mod_read,
- .write = hello_mod_write,
- .unlocked_ioctl = hello_mod_ioctl,
- .release = hello_mod_release,
- };
-
- static int hello_mod_open(struct inode *inode, struct file *pfile)
- {
- printk("+hello_mod_open()!/n");
- spin_lock(&spin);
- if(open_count)
- {
- spin_unlock(&spin);
- return -EBUSY;
- }
- open_count++;
- spin_unlock(&spin);
- printk("-hello_mod_open()!/n");
- return 0;
- }
- static int hello_mod_release(struct inode *inode, struct file *pfile)
- {
- printk("+hello_mod_release()!/n");
- open_count--;
- printk("-hello_mod_release()!/n");
- return 0;
- }
- static ssize_t hello_mod_read(struct file *pfile, char *user_buf, size_t len, loff_t *off)
- {
- printk("+hello_mod_read()!/n");
-
- if(down_interruptible(&sem))
- {
- return -ERESTARTSYS;
- }
- memset(outbuffer, 0, OUT_BUF_LEN);
- printk(" +switch()/n");
- switch(langtype)
- {
- case english:
- printk(" >in case: english/n");
- sprintf(outbuffer, "Hello! %s.", inbuffer);
- break;
- case chinese:
- printk(" >in case: chinese/n");
- sprintf(outbuffer, "你好! %s.", inbuffer);
- break;
- case pinyin:
- printk(" >in case: pinyin/n");
- sprintf(outbuffer, "ni hao! %s.", inbuffer);
- break;
- default:
- printk(" >in case: default/n");
- break;
- }
- printk(" -switch()/n");
- if(copy_to_user(user_buf, outbuffer, len))
- {
- up(&sem);
- return -EFAULT;
- }
- up(&sem);
- printk("-hello_mod_read()!/n");
- return 0;
- }
- static ssize_t hello_mod_write(struct file *pfile, const char *user_buf, size_t len, loff_t *off)
- {
- printk("+hello_mod_write()!/n");
- if(down_interruptible(&sem))
- {
- return -ERESTARTSYS;
- }
- if(len > IN_BUF_LEN)
- {
- printk("Out of input buffer/n");
- return -ERESTARTSYS;
- }
- if(copy_from_user(inbuffer, user_buf, len))
- {
- up(&sem);
- return -EFAULT;
- }
- up(&sem);
- printk("-hello_mod_write()!/n");
- return 0;
- }
- static long hello_mod_ioctl(struct file *pfile, unsigned int cmd, unsigned long arg)
- {
- int err = 0;
- printk("+hello_mod_ioctl()!/n");
- printk(" +switch()/n");
- switch(cmd)
- {
- case HELLO_IOCTL_RESETLANG:
- printk(" >in case: HELLO_IOCTL_RESETLANG/n");
- langtype = english;
- break;
- case HELLO_IOCTL_GETLANG:
- printk(" >in case: HELLO_IOCTL_GETLANG/n");
- err = copy_to_user((int *)arg, &langtype, sizeof(int));
- break;
- case HELLO_IOCTL_SETLANG:
- printk(" >in case: HELLO_IOCTL_SETLANG/n");
- err = copy_from_user(&langtype,(int *)arg, sizeof(int));
- break;
- default:
- printk(" >in case: default/n");
- err = ENOTSUPP;
- break;
- }
- printk(" -switch()/n");
- printk("-hello_mod_ioctl()!/n");
- return err;
- }
- static int __init hello_mod_init(void)
- {
- int result;
- printk("+hello_mod_init()!/n");
- devnum = MKDEV(MAJOR_NUM, MINOR_NUM);
- result = register_chrdev_region(devnum, 1, modname);
-
- if(result < 0)
- {
- printk("hello_mod : can't get major number!/n");
- return result;
- }
-
- cdev_init(&hello_cdev, &hello_mod_fops);
- hello_cdev.owner = THIS_MODULE;
- hello_cdev.ops = &hello_mod_fops;
- result = cdev_add(&hello_cdev, devnum, 1);
- if(result)
- printk("Failed at cdev_add()");
- hello_class = class_create(THIS_MODULE, classname);
- if(IS_ERR(hello_class))
- {
- printk("Failed at class_create().Please exec [mknod] before operate the device/n");
- }
- else
- {
- device_create(hello_class, NULL, devnum,NULL, devicename);
- }
-
- open_count = 0;
- langtype = english;
- inbuffer = (char *)kmalloc(IN_BUF_LEN, GFP_KERNEL);
- outbuffer = (char *)kmalloc(OUT_BUF_LEN, GFP_KERNEL);
- sema_init(&sem, 1);
- printk("-hello_mod_init()!/n");
- return 0;
- }
-
- static void __exit hello_mod_exit(void)
- {
- printk("+hello_mod_exit!/n");
- kfree(inbuffer);
- kfree(outbuffer);
- cdev_del(&hello_cdev);
- device_destroy(hello_class, devnum);
- class_destroy(hello_class);
- unregister_chrdev_region(devnum, 1);
- printk("-hello_mod_exit!/n");
- return ;
- }
-
- module_init(hello_mod_init);
- module_exit(hello_mod_exit);
- MODULE_LICENSE("GPL");
头文件:hello_mod_ioctl.h
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- #ifndef __HELLO_MOD_IOCTL_H__
- #define __HELLO_MOD_IOCTL_H__
-
- #define HELLO_MAGIC 12
- #define HELLO_IOCTL_RESETLANG _IO(HELLO_MAGIC,0) //set langtype = english
- #define HELLO_IOCTL_GETLANG _IOR(HELLO_MAGIC,1,int) //get langtype
- #define HELLO_IOCTL_SETLANG _IOW(HELLO_MAGIC,2,int) //set langtype
-
- typedef enum _lang_t
- {
- english, chinese, pinyin
- }lang_t;
-
- #endif
Makefile文件:(注意:Makefile的'M'要大写)
- #**********************************************
- # Makefile linux 2.6 Module
- # This makefile is written for Ubuntu 10.10
- # It may not perfomance without erros on the
- # other version or distributions.
- #**********************************************
- # BY:tishion
- # Mail:[email protected]
- # 2011/06/19
- #**********************************************
- obj-m += hello_mod.o
- CURRENT_PATH := $(shell pwd)
- LINUX_KERNEL := $(shell uname -r)
- LINUX_KERNEL_PATH := /usr/src/linux-headers-$(LINUX_KERNEL)
- all:
- make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
- clean:
- make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) clean
- install:
- insmod hello_mod.ko
- unistall:
- rmmod hello_mod
以上三个文件即为驱动代码
另外,再给一个应用层测试代码,并共用驱动的头文件
hello_mod_test.c文件:
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include "../hello_mod_ioctl.h"
-
- int main()
- {
- char outbuf[512];
- char * myname = "tishion";
- lang_t langtype = english;
- int fd = open("/dev/hello", O_RDWR, S_IRUSR|S_IWUSR);
- if(fd != -1)
- {
- write(fd, myname, strlen(myname)+1);
- langtype = chinese;
- ioctl(fd, HELLO_IOCTL_SETLANG, &langtype);
- read(fd, outbuf, 512);
- printf("langtype=chinese:%s/n", outbuf);
- memset(outbuf, 0, 512);
- langtype = pinyin;
- ioctl(fd, HELLO_IOCTL_SETLANG, &langtype);
- read(fd, outbuf, 512);
- printf("langtype=pinyin:%s/n", outbuf);
- memset(outbuf, 0, 512);
- ioctl(fd, HELLO_IOCTL_RESETLANG, &langtype);
- read(fd, outbuf, 512);
- printf("langtype=english:%s/n", outbuf);
- }
- else
- {
- perror("Failed at open():");
- }
- return 0;
- }
最后,安装原博客编译和查看结果。
需要注意的是,需要到“/var/log/”目录下着“syslog”文件。