Linux安装Spark集群(CentOS7+Spark2.1.1+Hadoop2.8.0)
1 安装Spark依赖的Scala
1.1下载和解压缩Scala
1.2 配置环境变量
1.3 验证Scala
2下载和解压缩Spark
2.1 下载Spark压缩包
2.2 解压缩Spark
3 Spark相关的配置
3.1 配置环境变量
3.2 配置conf目录下的文件
3.2.1 新建spark-env.h文件
3.2.2 新建slaves文件
4 启动和测试Spark集群
4.1 启动Spark
4.2 测试和使用Spark集群
4.2.1访问Spark集群提供的URL
4.2.2运行Spark提供的计算圆周率的示例程序
关键字:Linux CentOS Hadoop Spark Scala Java
版本号:CentOS7 Hadoop2.8.0 Spark2.1.1 Scala2.12.2 JDK1.8
说明:Spark可以在只安装了JDK、Scala的机器上直接单机安装,但是这样的话只能使用单机模式运行不涉及分布式运算和分布式存储的代码,例如可以单机安装Spark,单机运行计算圆周率的Spark程序。但是我们要运行的是Spark集群,并且需要调用Hadoop的分布式文件系统,所以请你先安装Hadoop,Hadoop集群的安装可以参考该博文:
http://blog.csdn.net/pucao_cug/article/details/71698903
安装单机版的Spark可以参考该博文:
http://blog.csdn.net/pucao_cug/article/details/72377219
Spark集群的最小化安装只需要安装这些东西:JDK 、Scala 、Hadoop 、Spark
1 安装Spark依赖的Scala
Hadoop的安装请参考上面提到的博文,因为Spark依赖scala,所以在安装Spark之前,这里要先安装scala。在每个节点上都进行安装。
1.1 下载和解压缩Scala
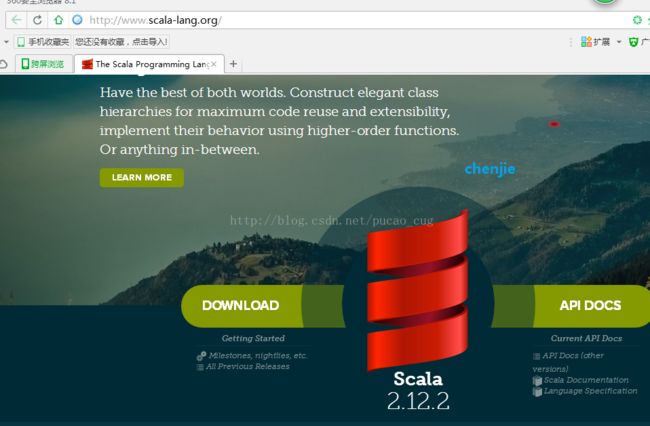
打开地址:http://www.scala-lang.org/
目前最新版是2.12.2,我就安装该版本
如图:
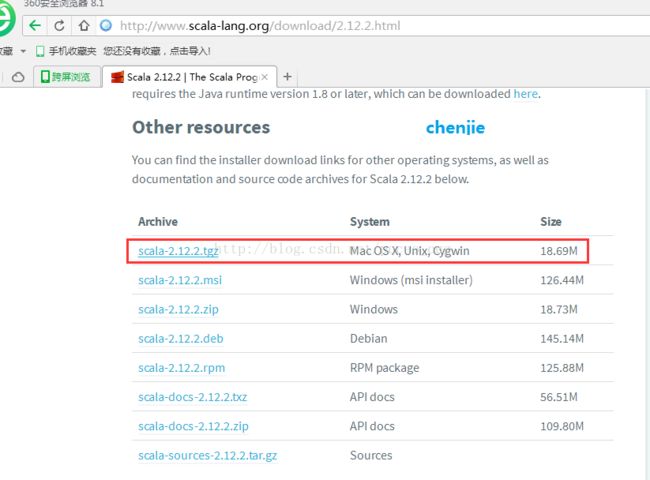
直接打开下面的地址也可以:
http://www.scala-lang.org/download/2.12.2.html
如图:
直接用下面的地址下载tgz包也可以:
https://downloads.lightbend.com/scala/2.12.2/scala-2.12.2.tgz
在Linux服务器的opt目录下新建一个名为scala的文件夹,并将下载的压缩包上载上去
如图:

执行命令,进入到该目录:
cd /opt/scala
执行命令进行解压缩:
tar -xvf scala-2.12.2
1.2 配置环境变量
编辑/etc/profile这个文件,在文件中增加一行配置:
export SCALA_HOME=/opt/scala/scala-2.12.2在该文件的PATH变量中增加下面的内容:
${SCALA_HOME}/bin添加完成后,我的/etc/profile的配置如下:
export JAVA_HOME=/opt/java/jdk1.8.0_121
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export HIVE_HOME=/opt/hive/apache-hive-2.1.1-bin
export HIVE_CONF_DIR=${HIVE_HOME}/conf
export SQOOP_HOME=/opt/sqoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha
export HBASE_HOME=/opt/hbase/hbase-1.2.5
export ZK_HOME=/opt/zookeeper/zookeeper-3.4.10
export SCALA_HOME=/opt/scala/scala-2.12.2
export CLASS_PATH=.:${JAVA_HOME}/lib:${HIVE_HOME}/lib:$CLASS_PATH
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${ZK_HOME}/bin:${HIVE_HOME}/bin:${SQOOP_HOME}/bin:${HBASE_HOME}/bin:${SCALA_HOME}/bin:$PATH说明:你可以只关注开头说的JDK SCALA Hadoop Spark的环境变量,其余的诸如Zookeeper、Hbase、Hive、Sqoop都不用管。
如图:

环境变量配置完成后,执行下面的命令:
source /etc/profile1.3 验证Scala
执行命令:
scala -version如图:
![]()
2 下载和解压缩Spark
在每个节点上都安装Spark,也就是重复下面的步骤。
2.1 下载Spark压缩包
打开下载地址:
http://spark.apache.org/downloads.html
如图:
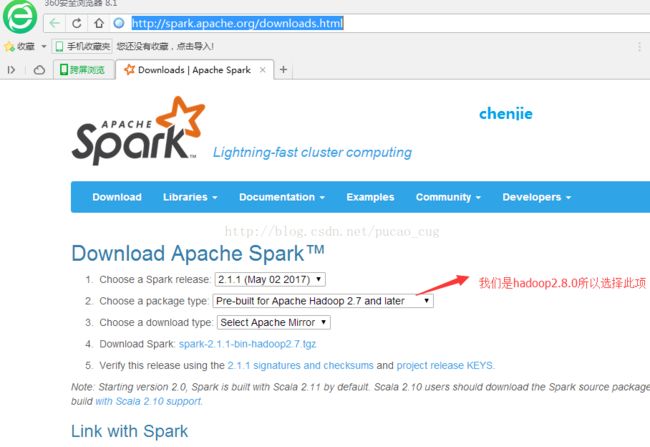
点击上图的 Download Spark,相当于是直接打开地址:
https://www.apache.org/dyn/closer.lua/spark/spark-2.1.1/spark-2.1.1-bin-hadoop2.7.tgz
下载后得到了大约200M的文件: spark-2.1.1-bin-hadoop2.7
直接用下面的地址下面也可以:
http://mirrors.hust.edu.cn/apache/spark/spark-2.1.1/spark-2.1.1-bin-hadoop2.7.tgz
2.2 解压缩Spark
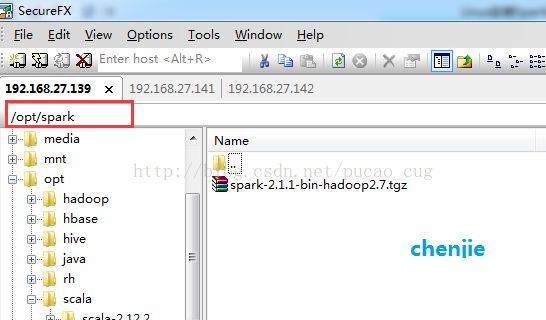
下载完成后,在Linux服务器的opt目录下新建一个名为spark的文件夹,把刚才下载的压缩包,上载上去。
如图:
进入到该目录内,也就是执行下面的命令:
cd /opt/spark
执行解压缩命令:
tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz
3 Spark相关的配置
说明:因为我们搭建的是基于hadoop集群的Spark集群,所以每个hadoop节点上我都安装了Spark,都需要按照下面的步骤做配置,启动的话只需要在Spark集群的Master机器上启动即可,我这里是在hserver1上启动。
3.1 配置环境变量
编辑/etc/profile文件,增加
export SPARK_HOME=/opt/spark/spark-2.1.1-bin-hadoop2.7上面的变量添加完成后编辑该文件中的PATH变量,添加
${SPARK_HOME}/bin注意:因为$SPARK_HOME/sbin目录下有一些文件名称和$HADOOP_HOME/sbin目录下的文件同名,为了避免同名文件冲突,这里不在PATH变量里添加$SPARK_HOME/sbin只添加了$SPARK_HOME/bin。
修改完成后,我的/etc/profile文件内容是:
export JAVA_HOME=/opt/java/jdk1.8.0_121
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export HIVE_HOME=/opt/hive/apache-hive-2.1.1-bin
export HIVE_CONF_DIR=${HIVE_HOME}/conf
export SQOOP_HOME=/opt/sqoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha
export HBASE_HOME=/opt/hbase/hbase-1.2.5
export ZK_HOME=/opt/zookeeper/zookeeper-3.4.10
export SCALA_HOME=/opt/scala/scala-2.12.2
export SPARK_HOME=/opt/spark/spark-2.1.1-bin-hadoop2.7
export CLASS_PATH=.:${JAVA_HOME}/lib:${HIVE_HOME}/lib:$CLASS_PATH
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${ZK_HOME}/bin:${HIVE_HOME}/bin:${SQOOP_HOME}/bin:${HBASE_HOME}:${SCALA_HOME}/bin:$PATH说明:你可以只关注开头说的JDK SCALA Hadoop Spark的环境变量,其余的诸如Zookeeper、Hbase、Hive、Sqoop都不用管。
如图:

编辑完成后,执行命令:
source /etc/profile
3.2 配置conf目录下的文件
对/opt/spark/spark-2.1.1-bin-hadoop2.7/conf目录下的文件进行配置。
3.2.1 新建spark-env.h文件
执行命令,进入到/opt/spark/spark-2.1.1-bin-hadoop2.7/conf目录内:
cd /opt/spark/spark-2.1.1-bin-hadoop2.7/conf
以spark为我们创建好的模板创建一个spark-env.h文件,命令是:
cp spark-env.sh.template spark-env.sh
如图:
![]()
编辑spark-env.h文件,在里面加入配置(具体路径以自己的为准):
export SCALA_HOME=/opt/scala/scala-2.12.2
export JAVA_HOME=/opt/java/jdk1.8.0_121
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/opt/spark/spark-2.1.1-bin-hadoop2.7
export SPARK_MASTER_IP=hserver1
export SPARK_EXECUTOR_MEMORY=1G3.2.2 新建slaves文件
执行命令,进入到/opt/spark/spark-2.1.1-bin-hadoop2.7/conf目录内:
cd /opt/spark/spark-2.1.1-bin-hadoop2.7/conf
以spark为我们创建好的模板创建一个slaves文件,命令是:
cp slaves.template slaves
如图:

编辑slaves文件,里面的内容为:
hserver2
hserver34 启动和测试Spark集群
4.1 启动Spark
因为spark是依赖于hadoop提供的分布式文件系统的,所以在启动spark之前,先确保hadoop在正常运行。Hadoop2.8.0的安装和启动,请参考该博文:
http://blog.csdn.net/pucao_cug/article/details/71698903
在hadoop正常运行的情况下,在hserver1(也就是hadoop的namenode,spark的marster节点)上执行命令:
cd /opt/spark/spark-2.1.1-bin-hadoop2.7/sbin
执行启动脚本:
./start-all.sh
如图:

完整内容是:
[root@hserver1 sbin]# cd/opt/spark/spark-2.1.1-bin-hadoop2.7/sbin
[root@hserver1 sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master,logging to/opt/spark/spark-2.1.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-hserver1.out
hserver2: startingorg.apache.spark.deploy.worker.Worker, logging to/opt/spark/spark-2.1.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hserver2.out
hserver3: startingorg.apache.spark.deploy.worker.Worker, logging to/opt/spark/spark-2.1.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hserver3.out
[root@hserver1 sbin]#注意:上面的命令中有./这个不能少,./的意思是执行当前目录下的start-all.sh脚本。
4.2 测试和使用Spark集群
4.2.1 访问Spark集群提供的URL
在浏览器里访问Mster机器,我的Spark集群里Master机器是hserver1,IP地址是192.168.27.143,访问8080端口,URL是:http://192.168.27.143:8080/
如图:

4.2.2 运行Spark提供的计算圆周率的示例程序
这里只是简单的用local模式运行一个计算圆周率的Demo。按照下面的步骤来操作。
第一步,进入到Spark的根目录,也就是执行下面的脚本:
cd /opt/spark/spark-2.1.1-bin-hadoop2.7
如图:
![]()
第二步,调用Spark自带的计算圆周率的Demo,执行下面的命令:
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master local examples/jars/spark-examples_2.11-2.1.1.jar
命令执行后,spark示例程序已经开始执行
如图:

很快执行结果出来了,执行结果我用红框标出来了
如图:
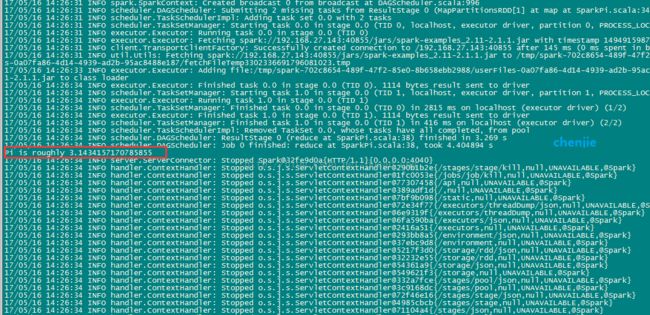
完整的控制台输出是:
[root@hserver1 bin]# cd /opt/spark/spark-2.1.1-bin-hadoop2.7
[root@hserver1 spark-2.1.1-bin-hadoop2.7]# ./bin/spark-submit--class org.apache.spark.examples.SparkPi --master localexamples/jars/spark-examples_2.11-2.1.1.jar
17/05/16 14:26:23 INFO spark.SparkContext: Running Spark version2.1.1
17/05/16 14:26:24 WARN util.NativeCodeLoader: Unable to loadnative-hadoop library for your platform... using builtin-java classes whereapplicable
17/05/16 14:26:25 INFO spark.SecurityManager: Changing view acls to:root
17/05/16 14:26:25 INFO spark.SecurityManager: Changing modify aclsto: root
17/05/16 14:26:25 INFO spark.SecurityManager: Changing view aclsgroups to:
17/05/16 14:26:25 INFO spark.SecurityManager: Changing modify aclsgroups to:
17/05/16 14:26:25 INFO spark.SecurityManager: SecurityManager:authentication disabled; ui acls disabled; users with view permissions: Set(root); groups withview permissions: Set(); users withmodify permissions: Set(root); groups with modify permissions: Set()
17/05/16 14:26:25 INFO util.Utils: Successfully started service'sparkDriver' on port 40855.
17/05/16 14:26:26 INFO spark.SparkEnv: Registering MapOutputTracker
17/05/16 14:26:26 INFO spark.SparkEnv: RegisteringBlockManagerMaster
17/05/16 14:26:26 INFO storage.BlockManagerMasterEndpoint: Usingorg.apache.spark.storage.DefaultTopologyMapper for getting topology information
17/05/16 14:26:26 INFO storage.BlockManagerMasterEndpoint:BlockManagerMasterEndpoint up
17/05/16 14:26:26 INFO storage.DiskBlockManager: Created localdirectory at /tmp/blockmgr-cf8cbb42-95d2-4284-9a48-67592363976a
17/05/16 14:26:26 INFO memory.MemoryStore: MemoryStore started withcapacity 413.9 MB
17/05/16 14:26:26 INFO spark.SparkEnv: RegisteringOutputCommitCoordinator
17/05/16 14:26:26 INFO util.log: Logging initialized @5206ms
17/05/16 14:26:27 INFO server.Server: jetty-9.2.z-SNAPSHOT
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@5118388b{/jobs,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@15a902e7{/jobs/json,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@7876d598{/jobs/job,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4a3e3e8b{/jobs/job/json,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@5af28b27{/stages,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@71104a4{/stages/json,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@4985cbcb{/stages/stage,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@72f46e16{/stages/stage/json,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@3c9168dc{/stages/pool,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@332a7fce{/stages/pool/json,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@549621f3{/storage,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@54361a9{/storage/json,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@32232e55{/storage/rdd,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@5217f3d0{/storage/rdd/json,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@37ebc9d8{/environment,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@293bb8a5{/environment/json,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@2416a51{/executors,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@6fa590ba{/executors/json,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@6e9319f{/executors/threadDump,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@72e34f77{/executors/threadDump/json,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@7bf9b098{/static,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@389adf1d{/,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@77307458{/api,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@1fc0053e{/jobs/job/kill,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@290b1b2e{/stages/stage/kill,null,AVAILABLE,@Spark}
17/05/16 14:26:27 INFO server.ServerConnector: StartedSpark@32fe9d0a{HTTP/1.1}{0.0.0.0:4040}
17/05/16 14:26:27 INFO server.Server: Started @5838ms
17/05/16 14:26:27 INFO util.Utils: Successfully started service'SparkUI' on port 4040.
17/05/16 14:26:27 INFO ui.SparkUI: Bound SparkUI to 0.0.0.0, andstarted at http://192.168.27.143:4040
17/05/16 14:26:27 INFO spark.SparkContext: Added JARfile:/opt/spark/spark-2.1.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.1.jarat spark://192.168.27.143:40855/jars/spark-examples_2.11-2.1.1.jar withtimestamp 1494915987472
17/05/16 14:26:27 INFO executor.Executor: Starting executor IDdriver on host localhost
17/05/16 14:26:27 INFO util.Utils: Successfully started service'org.apache.spark.network.netty.NettyBlockTransferService' on port 41104.
17/05/16 14:26:27 INFO netty.NettyBlockTransferService: Servercreated on 192.168.27.143:41104
17/05/16 14:26:27 INFO storage.BlockManager: Usingorg.apache.spark.storage.RandomBlockReplicationPolicy for block replicationpolicy
17/05/16 14:26:27 INFO storage.BlockManagerMaster: RegisteringBlockManager BlockManagerId(driver, 192.168.27.143, 41104, None)
17/05/16 14:26:27 INFO storage.BlockManagerMasterEndpoint:Registering block manager 192.168.27.143:41104 with 413.9 MB RAM,BlockManagerId(driver, 192.168.27.143, 41104, None)
17/05/16 14:26:27 INFO storage.BlockManagerMaster: RegisteredBlockManager BlockManagerId(driver, 192.168.27.143, 41104, None)
17/05/16 14:26:27 INFO storage.BlockManager: InitializedBlockManager: BlockManagerId(driver, 192.168.27.143, 41104, None)
17/05/16 14:26:28 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@4e6d7365{/metrics/json,null,AVAILABLE,@Spark}
17/05/16 14:26:28 INFO internal.SharedState: Warehouse path is'file:/opt/spark/spark-2.1.1-bin-hadoop2.7/spark-warehouse'.
17/05/16 14:26:28 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@705202d1{/SQL,null,AVAILABLE,@Spark}
17/05/16 14:26:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3e58d65e{/SQL/json,null,AVAILABLE,@Spark}
17/05/16 14:26:28 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@6f63c44f{/SQL/execution,null,AVAILABLE,@Spark}
17/05/16 14:26:28 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@62a8fd44{/SQL/execution/json,null,AVAILABLE,@Spark}
17/05/16 14:26:28 INFO handler.ContextHandler: Startedo.s.j.s.ServletContextHandler@1d035be3{/static/sql,null,AVAILABLE,@Spark}
17/05/16 14:26:30 INFO spark.SparkContext: Starting job: reduce atSparkPi.scala:38
17/05/16 14:26:30 INFO scheduler.DAGScheduler: Got job 0 (reduce atSparkPi.scala:38) with 2 output partitions
17/05/16 14:26:30 INFO scheduler.DAGScheduler: Final stage:ResultStage 0 (reduce at SparkPi.scala:38)
17/05/16 14:26:30 INFO scheduler.DAGScheduler: Parents of finalstage: List()
17/05/16 14:26:30 INFO scheduler.DAGScheduler: Missing parents:List()
17/05/16 14:26:30 INFO scheduler.DAGScheduler: SubmittingResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34), which has nomissing parents
17/05/16 14:26:30 INFO memory.MemoryStore: Block broadcast_0 storedas values in memory (estimated size 1832.0 B, free 413.9 MB)
17/05/16 14:26:30 INFO memory.MemoryStore: Block broadcast_0_piece0stored as bytes in memory (estimated size 1167.0 B, free 413.9 MB)
17/05/16 14:26:31 INFO storage.BlockManagerInfo: Addedbroadcast_0_piece0 in memory on 192.168.27.143:41104 (size: 1167.0 B, free:413.9 MB)
17/05/16 14:26:31 INFO spark.SparkContext: Created broadcast 0 frombroadcast at DAGScheduler.scala:996
17/05/16 14:26:31 INFO scheduler.DAGScheduler: Submitting 2 missingtasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34)
17/05/16 14:26:31 INFO scheduler.TaskSchedulerImpl: Adding task set0.0 with 2 tasks
17/05/16 14:26:31 INFO scheduler.TaskSetManager: Starting task 0.0in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL,6026 bytes)
17/05/16 14:26:31 INFO executor.Executor: Running task 0.0 in stage0.0 (TID 0)
17/05/16 14:26:31 INFO executor.Executor: Fetchingspark://192.168.27.143:40855/jars/spark-examples_2.11-2.1.1.jar with timestamp1494915987472
17/05/16 14:26:31 INFO client.TransportClientFactory: Successfullycreated connection to /192.168.27.143:40855 after 145 ms (0 ms spent inbootstraps)
17/05/16 14:26:31 INFO util.Utils: Fetchingspark://192.168.27.143:40855/jars/spark-examples_2.11-2.1.1.jar to/tmp/spark-702c8654-489f-47f2-85e0-8b658ebb2988/userFiles-0a07fa86-4d14-4939-ad2b-95ac8488e187/fetchFileTemp3302336691796081023.tmp
17/05/16 14:26:33 INFO executor.Executor: Addingfile:/tmp/spark-702c8654-489f-47f2-85e0-8b658ebb2988/userFiles-0a07fa86-4d14-4939-ad2b-95ac8488e187/spark-examples_2.11-2.1.1.jarto class loader
17/05/16 14:26:34 INFO executor.Executor: Finished task 0.0 in stage0.0 (TID 0). 1114 bytes result sent to driver
17/05/16 14:26:34 INFO scheduler.TaskSetManager: Starting task 1.0in stage 0.0 (TID 1, localhost, executor driver, partition 1, PROCESS_LOCAL,6026 bytes)
17/05/16 14:26:34 INFO executor.Executor: Running task 1.0 in stage0.0 (TID 1)
17/05/16 14:26:34 INFO scheduler.TaskSetManager: Finished task 0.0in stage 0.0 (TID 0) in 2815 ms on localhost (executor driver) (1/2)
17/05/16 14:26:34 INFO executor.Executor: Finished task 1.0 in stage0.0 (TID 1). 1114 bytes result sent to driver
17/05/16 14:26:34 INFO scheduler.TaskSetManager: Finished task 1.0in stage 0.0 (TID 1) in 416 ms on localhost (executor driver) (2/2)
17/05/16 14:26:34 INFO scheduler.TaskSchedulerImpl: Removed TaskSet0.0, whose tasks have all completed, from pool
17/05/16 14:26:34 INFO scheduler.DAGScheduler: ResultStage 0 (reduceat SparkPi.scala:38) finished in 3.269 s
17/05/16 14:26:34 INFO scheduler.DAGScheduler: Job 0 finished:reduce at SparkPi.scala:38, took 4.404894 s
Pi is roughly 3.1434157170785855
17/05/16 14:26:34 INFO server.ServerConnector: StoppedSpark@32fe9d0a{HTTP/1.1}{0.0.0.0:4040}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@290b1b2e{/stages/stage/kill,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@1fc0053e{/jobs/job/kill,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@77307458{/api,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@389adf1d{/,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@7bf9b098{/static,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@72e34f77{/executors/threadDump/json,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@6e9319f{/executors/threadDump,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@6fa590ba{/executors/json,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@2416a51{/executors,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@293bb8a5{/environment/json,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@37ebc9d8{/environment,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@5217f3d0{/storage/rdd/json,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@32232e55{/storage/rdd,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@54361a9{/storage/json,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@549621f3{/storage,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@332a7fce{/stages/pool/json,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@3c9168dc{/stages/pool,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@72f46e16{/stages/stage/json,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@4985cbcb{/stages/stage,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@71104a4{/stages/json,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@5af28b27{/stages,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@4a3e3e8b{/jobs/job/json,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@7876d598{/jobs/job,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@15a902e7{/jobs/json,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO handler.ContextHandler: Stoppedo.s.j.s.ServletContextHandler@5118388b{/jobs,null,UNAVAILABLE,@Spark}
17/05/16 14:26:34 INFO ui.SparkUI: Stopped Spark web UI athttp://192.168.27.143:4040
17/05/16 14:26:34 INFO spark.MapOutputTrackerMasterEndpoint:MapOutputTrackerMasterEndpoint stopped!
17/05/16 14:26:34 INFO memory.MemoryStore: MemoryStore cleared
17/05/16 14:26:34 INFO storage.BlockManager: BlockManager stopped
17/05/16 14:26:34 INFO storage.BlockManagerMaster: BlockManagerMasterstopped
17/05/16 14:26:34 INFOscheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint:OutputCommitCoordinator stopped!
17/05/16 14:26:34 INFO spark.SparkContext: Successfully stoppedSparkContext
17/05/16 14:26:34 INFO util.ShutdownHookManager: Shutdown hookcalled
17/05/16 14:26:34 INFO util.ShutdownHookManager: Deleting directory/tmp/spark-702c8654-489f-47f2-85e0-8b658ebb2988
[root@hserver1 spark-2.1.1-bin-hadoop2.7]#注意:上面只是使用了单机本地模式调用Demo,使用集群模式运行Demo,请参考该博文
http://blog.csdn.net/pucao_cug/article/details/72453382