协同过滤itembase计算Spark实现(二)
博主前期有写过协同过滤协同过滤itembase增量计算Spark实现(一),其中已经较为基础的演示了基于欧拉距离求解相似度的过程,由于都是在一个JOB里,随着数据量的增长会出现计算耗时过长、OOM等现象,后期博主在推荐系统架构优化方面发现上述五个步骤在诸如看了还看,买了还买,相关搜索词,搜索最终购买等推荐模块存在着大量的相似,这些步骤的复用性太强,所以就开始考虑对算法模块按其计算步骤进行拆分,拆分之后的代码结构如下图:
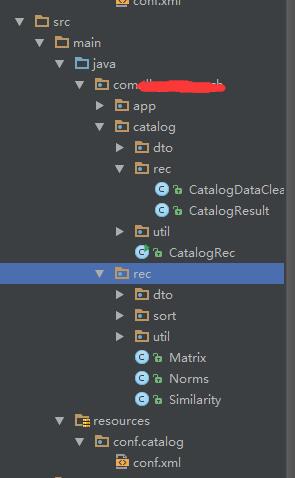
其中rec文件夹下为公用算法模块,主要包括norms,mastrix,similarity。后续求相似度得分的各种算法实现都可以在此模块下添加。
catalog文件夹为类目推荐模块,只里面只需要将原始数据dataclean成算法所需输入及算法结构组装成所需输出格式即可。
itembase协同过滤算法主要可以拆分成如下几个步骤:
1.数据清洗 dataclean
2.计算模 norms
3.生成共生矩阵 matrix
4.计算相似度 similarity
5.转化输出 output
下面演示架构调整之后itembase的计算过程:
数据清洗
如果可以从日志采集系统或者系统日志中得到如下基础数据,那恭喜已经迈出了成功的一大步,因为已经拥有了生产资料。
USERIF SKU REF
1000000148,374753033,2
1000000444,213854638,2
1000000444,250439018,2
1000000444,255468579,1
1000000518,160079966,2
1000000518,231416046,2
1000000518,236056060,2
1000000518,241393352,1
1000000518,242298041,1
1000000518,248723096,1
1000000533,216326552,2
1000000611,265955264,2
1000000665,212797458,2
1000000826,240917738,2
1000001161,229249059,2
......catalogDataClean
aggregateByKey(new ArrayList>(), new
Function2<List>, Tuple2,
List>>() {
@Override
public List> call(List> v1, Tuple2 v2) throws Exception {
if (0 != v2._1() && 0 != v2._2()) {
v1.add(v2);
}
return v1;
}
}, new Function2<List>, List>, List>>() {
@Override
public List> call(List> v1, List> v2) throws Exception {
v1.addAll(v2);
return v1;
}
}).filter(new Function<Tuple2<String, List<Tuple2<Long, Float>>>, Boolean>() {
@Override
public Boolean call(Tuple2List>> v1) throws Exception {
return v1._2().size() >= 2 && v1._2().size() <= confDO.getNeedCount();
}
}).map(new Function<Tuple2<String, List<Tuple2<Long, Float>>>, String>() {
@Override
public String call(Tuple2List>> t) throws Exception {
Collections.sort(t._2(), new SortByKey());
StringBuilder sb = new StringBuilder();
sb.append(t._1()).append(Constats.PARTTEN_END);
for (Tuple2 tuple : t._2()) {
sb.append(tuple._1()).append(Constats.PARTTEN).append(tuple._2()).append(Constats.PARTTEN_END);
}
if (sb.length() > t._1().length()) {
sb = sb.delete(sb.length() - Constats.PARTTEN_END.length(), sb.length());
}
return sb.toString();
}
}).saveAsTextFile(confDO.getTempPath() + Constats.DATA_CLEAN);
上述基础数据经过业务规则进行数据清洗,以userId为key,商品及得分的集合为value(skuId排序,生成共生矩阵时需要)输出结果如下:
userId sku ref sku ref sku ref
937700502 381564463 1.0 381248417 1.0 380973055 1.0 377078626 1.0
......求模
求模这边尝试保存成json的格式,后面在计算相似度是可以考虑利用spark sqlContext实现,这样避免了norms在集群之间的广播,减小对系统内存的消耗。
JavaRDD norms = sc.textFile(confDO.getTempPath() + Constats.DATA_CLEAN).flatMapToPair(new PairFlatMapFunction() {
@Override
public Iterable> call(String s) throws Exception {
return DataDealUtil.queryItemAndRef(s);
}
}).reduceByKey(new Function2() {
@Override
public Float call(Float v1, Float v2) throws Exception {
return v1 * v1 + v2 * v2;
}
}).map(new Function, NormsDTO>() {
@Override
public NormsDTO call(Tuple2 v1) throws Exception {
return new NormsDTO(v1._1(), v1._2() == Float.POSITIVE_INFINITY ? Float.MAX_VALUE : v1._2());
}
}).toJSON().saveAsTextFile(confDO.getTempPath() + Constats.NOREMS); 如果业务有商品黑名单的需求可以考虑在此处过滤,目前博主是这样做的:
sqlContext.createDataFrame(norms, NormsDTO.class).registerTempTable("norms");
//加载product信息
JavaRDD icRDD = DataDealUtil.queryProduct(confDO.getProductInputPath(), sc);
//生成产品表
sqlContext.createDataFrame(icRDD, ProductDTO.class).registerTempTable("product");
sqlContext.sql("select ta.*,tb.catalog from norms ta join product tb on ta.value = tb.itemCode")
.toJSON().saveAsTextFile(confDO.getTempPath() + Constats.NOREMS); 求模结果输出
{"ref":1.0,"value":52679631,"catalog":"002007005"}
{"ref":3.4028235E38,"value":61357431,"catalog":"019009004013"}
{"ref":8.0,"value":61503831,"catalog":"014023003"}
{"ref":1.0230607E29,"value":66857631,"catalog":"113003009"}
......如果你还需要返回其他字段可以酌情添加
生成共生矩阵
共生矩阵其实就是右上角矩阵,这样只需要计算一半数据即可。
因为在dataclean计算已经对sku进行了排序,所以这里就可以直接放心使用。
sc.textFile(confDO.getTempPath() + Constats.DATA_CLEAN).flatMapToPair(new PairFlatMapFunction, Float>() {
@Override
public Iterable, Float>> call(String s) throws Exception {
List> itemList = DataDealUtil.queryItemAndRef(s);
List, Float>> list = new ArrayList<>();
for (int i = 0; i < itemList.size(); i++) {
for (int j = i; j < itemList.size(); j++) {
list.add(new Tuple2<>(new Tuple2<>(itemList.get(i)._1(), itemList.get(j)._1()),
itemList.get(i)._2() * itemList.get(j)._2()));
}
}
return list;
}
}).reduceByKey(new Function2() {
@Override
public Float call(Float v1, Float v2) throws Exception {
return v1 + v2;
}
}) 共生矩阵输出结果为:
{"master":379869616,"ref":19.0,"slave":372501199}
{"master":387427775,"ref":2.0,"slave":386049630}
{"master":387713219,"ref":4.0,"slave":373536559}
{"master":372496545,"ref":4.0,"slave":251865949}
{"master":371041599,"ref":4.0,"slave":243016548}
{"master":388376322,"ref":4.0,"slave":388307883}
{"master":379284429,"ref":2.0,"slave":218151880}
{"master":373737195,"ref":2.0,"slave":258594000}
{"master":266551992,"ref":2.0,"slave":233835000}
{"master":378748812,"ref":4.0,"slave":255309807}
{"master":388673944,"ref":4.0,"slave":215564562}
{"master":381707460,"ref":1.0,"slave":246491758}
......计算相似度
欧拉距离求相似度
输入为norms和matrix
sqlContext.jsonFile(confDO.getTempPath() + Constats.NOREMS).registerTempTable("norms");
sqlContext.jsonFile(confDO.getTempPath() + Constats.MATRIX).registerTempTable("matrix");
sqlContext.cacheTable("norms");
sqlContext.sql("select ta.master,ta.slave,ta.ref,tb.ref as normsRef, tb.catalog as mId from matrix ta " +
"join norms tb on tb.value = ta.master")
.registerTempTable("masterFrame");
DataFrame similarity = sqlContext.sql("select ta.master, ta.slave, " +
"(1 / (1 + sqrt(ta.normsRef + tb.ref - 2 * ta.ref))) as ref,ta.mId,tb.catalog as sId from masterFrame ta " +
"join norms tb on tb.value = ta.slave and ta.master != ta.slave");
sqlContext.uncacheTable("norms");
similarity.toJavaRDD().map(new Function() {
@Override
public String call(Row v1) throws Exception {
return v1.apply(0) + Constats.PARTTEN + v1.apply(1) + Constats.PARTTEN + v1.apply(2) + Constats.PARTTEN
+ v1.apply(3) + Constats.PARTTEN + v1.apply(4);
}
}).saveAsTextFile(confDO.getTempPath() + Constats.SIMILARITY); 将norms表缓存 sqlContext.cacheTable(“norms”)可以提升系统性能减少一次IO读取。个人感觉利用spark的sqlcontext是非常巧妙的,尤其是在大数据量的场景下,此实现方案可以大大减少集群内存使用量及计算时间,可以避免出现oom,timeout等异常。
相似度得分输出为:
master slave ref mCatalog sCatalog
25461787 23423520 2.1855107033222275E-15 100007001 100007005
236258795 23423520 5.421010997210578E-20 100006008 100007005
......转化输出
这里无非是将共生矩阵进行一定的业务处理,比如类目过滤,价格过滤等,最重要的就是将矩阵补全,只需要简单的将master跟slave进行对换即可。
总结
至此利用周末两天时间对推荐系统spark实现的算法拆分工作已经做完,系统的拆分能够保证大数据计算前提下的断点续算,中间结果的保存,增量计算等等各方面的需求得到合理高效的解决并实现。博主这边只是提供了系统优化的一个思路,亲们可以在此基础上结合业务场景进行适当的调整与优化。
比如在dataClean阶段直接输出userId,sku,ref的格式,在求模的时候不需要进行拆分直接reduceBykey即可,但是在求mastrix的时候则需要进行一次groupByKey求集合,博主分别实现了上述两种方案,发现后者在计算mastrix时对系统内存使用率会会高大约一半,耗时长,偶尔还会出现tiemout的现象,故选择了前者。这样的实验并不是绝对的。哈,程序猿工作宗旨就是保证所开发的项目健康高效。
其中还有个小插曲,因为G20妹子周末停休,答应去接妹子下班,昨天刚好在拆分算法模块,结果有点仓促,直接拖鞋就跑央视大楼去了,各种丢人!!!今天怎么也得好好回去准备下,不能再丢人啦,我要回去收拾下接妹子下班啦~~~
协同过滤itembase计算Spark实现(三)