2019-04-10 - Elasticsearch 初学者之记录es6的基本使用:添加索引、数据、测试ik分词(明明安装了ik 确不分词问题)
最近在做的web系统需要实现搜索框,其搜索内容涉及到几张表以及表里面的多个字段,表之间存在一些关系。
考虑使用强大的Elasticsearch 来锻炼一下自己,好吧安装我这里就不详述了,可以搜出n多篇文章;
这次在服务端安装使用的es是6.6.2版本,下载(https://www.elastic.co/cn/downloads/)、上传、解压,./bin/elasticsearch 启动 (踩坑说明:第一次启动可以不加 -d,方便看到日志,因为可能会遇到使用root用户启动不允许的错误,然后你切换了普通用户,发现 又报了某个文件没有权限的问题,切回root赋权 命令: [chown -R 组名:普通用户名 /your es 目录] ;还有一些关于配置的问题:借鉴这位兄台的操作吧 正常都可以解决了:https://blog.csdn.net/dajienet/article/details/80009391
启动成功后,访问:

配置文件位于es根目录的config目录下面,有elasticsearch.yml 可以自定义name,clustername 是为了集群之间使用同一个可以相互通信的。
之后还安装了kibana(web界面管理操作es的,安装启动超简单)logstash(后面用作从mysql导入数据到es中),ik分词器(放到es根目录下的plugin中),安装启动坑不太多;
//创建一个索引-oldindex 概念类比mysql的 db,_doc 为type 类比mysql的table,里面有一个字段名mytext 类型为text
(更新:网上很多都是这个类比的,但是在es7版本中即将删除type 而且官方解释 type并不类比 mysql里买的table
最初,我们谈到了一个“索引”类似于SQL数据库中的“数据库”,而“类型”等同于“表”。
这是一个糟糕的比喻,导致错误的假设。在SQL数据库中,表彼此独立。一个表中的列与另一个表中具有相同名称的列无关。映射类型中的字段不是这种情况。
在Elasticsearch索引中,不同映射类型中具有相同名称的字段在内部由相同的Lucene字段支持。换句话说,使用上面的示例,类型中的user_name字段user存储在与类型中的字段完全相同的user_name字段中tweet,并且两个 user_name字段在两种类型中必须具有相同的映射(定义)。
例如,当您希望deleted成为 同一索引date中的某个类型的boolean字段和另一个类型的字段时,这可能会导致挫败感。
最重要的是,在同一索引中存储具有很少或没有共同字段的不同实体会导致稀疏数据并干扰Lucene有效压缩文档的能力。
出于这些原因,我们决定从Elasticsearch中删除映射类型的概念。
)
网上好多资料都是curl -XPUT 的形式,直接粘贴在命令行格式还会乱,看着也不舒服,个人不喜欢用,还是用postman
或者适用kibana中的dev tools吧devtools 工具开始用起来还不是很熟练,不过它还蛮多功能的 多行、提示等,建议多多练习;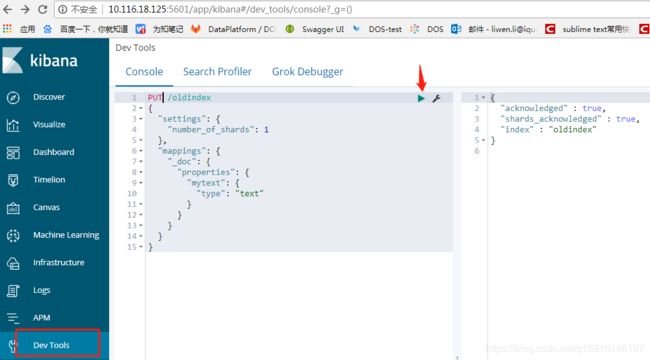
建立索引后,存储一个文档数据,文本格式:
POST /oldindex/_doc/
{"text" : "百度人民生活在搜索的是这样子的网址:www.baidu.com",
"url" : "百度人民生活在这样如果你还记得我的家庭网址:www.baidu.com" }
POST /oldindex/_doc/1
{"content": "百度人民生活在搜索的是这样子的网址:www.baidu.com",
"text" : "我是一个勤劳的小蜜蜂,感觉人生达到了巅峰"}
POST /oldindex/_doc/2
{ "content": "生活在搜索的是这样子如果你还记得我们的人生如戏网址:www.baidu.com" }
查看一下刚才添加的数据:
POST /oldindex/_doc/_search
{
"query":{
"match_all":{} }
}
或者按照某个字段匹配:
POST /oldindex/_doc/_search
{"query":{
"match":{
"url":"人民"
}
}}
当然了我们可能还可以按多个字段匹配并且要求其中某个字段必须是xx值: (筛选type字段必须为table,并且在text和url字段中查找含有“人民”的文档)
{
"query": {
"bool": {
"must": {
"multi_match": {
"fields": [
"text",
"url"
],
"query": "人民"
}
},
"filter": {
"match": {
"type": "table"
}
} //filter 这个条件可以自行去掉
}
}
}
但是当我把筛选词改为“好人”的时候,含有“人” 的词条也被检索了出来。。。很明显是分词的问题,但是我明明在启动的时候已经加载了ik分词器呀:

网上找了很多关于ik的测试,比如:
GET _analyze?pretty
{
"analyzer": "ik_max_word",
"text": "百度人民生活在搜索的是这样子的网址:www.baidu.com"
}
结果就不贴了太长了,百度、人民、民生、www、baidu 都会分词,功能没问题,但是我搜索的时候搜的"好人" 确实不应该被检索出来;
网上也搜了半天,结合自己使用kibana工具查看这个地方:
所以对于你我新手而言,有时候被一个小问题绊住却不知道如何下手。。。
下面是如何设置某字段在搜索时自动使用 ik分词: (啰嗦:多用kibana工具)
//设定mapping( 此时 oldindex索引已经建立的, doc99 是mapping设置下的type )
POST /oldindex/doc99/_mapping
{
"properties":{
"yourtext":{
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
} //如果想修改一个当前已存在索引或者已存在字段的mapping,会报这个分词器冲突错误:
"type": "illegal_argument_exception",
"reason": "Mapper for [mytext] conflicts with existing mapping in other types:\n[mapper [mytext] has different [analyzer]]"
so , you know !
最好是新建一个索引,从新设置mapping,我的下文中有说明;关于设置mapping的一些坑
https://blog.csdn.net/q18810146167/article/details/89339380
上面的操作是新手摸索 亲手实测操作,其实还包括添加其他分词器、logstash导出MySQL数据到es中并自动设置多字段mapping、cluster建设、结合springboot2.0版本,多个条件匹配等。都不是太难。后面有时间会继续更新。。。
有什么问题可以下方评论,欢迎指正,共同进步。。。
希望看完的小伙伴多多支持,转载,写博客也蛮累的。。。。
参考文献:https://blog.csdn.net/alan_liuyue/article/details/78361431
https://blog.csdn.net/dajienet/article/details/80009391