hadoop基础----hadoop实战(三)-----hadoop运行MapReduce---对单词进行统计--经典的自带例子wordcount
我们在第一篇文章中已经进行了hadoop1.0的环境安装。
hadoop基础----hadoop实战(一)-----hadoop环境安装---手动安装官方1.0版本
上一篇也熟悉了常用的hadoop的hdfs命令。
hadoop基础----hadoop实战(二)-----hadoop操作hdfs---hdfs文件系统常用命令
这一章我们就是尝试hadoop的MapReduce的统计功能---单词计数,下几篇文章会熟悉myeclipse写MapReduce打jar包放到hadoop中运行的整个流程(也就是工作中的hadoop开发流程)以及分析学习MapReduce的写法。
单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版"Hello World"。
单词计数主要完成功能是:统计一系列文本文件中每个单词出现的次数,如下图所示。

该程序的完整代码可以在Hadoop安装包的"src/examples"目录下找到。每个版本的路径类似。命令应该是example.jar。
我们之前的安装路径是/home/joe/hadoop/hadoop-1.2.1/,可以看到路径下有hadoop-examples-1.2.1.jar
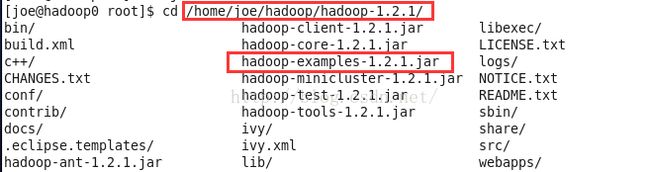
我们现在就按步骤来运行这个计数代码。
创建本地目录和需要统计的文件
cd /home/joe
mkdir input

然后创建文件
cd input
vim file1.txt写上需要统计的文本并保存。
我们这里写上
hello world
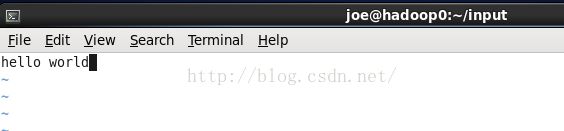
再创建第二个文件
vim file2.txt文件2写上
hello hadoop

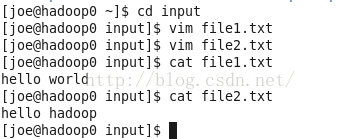
查看文件内容:
cat file1.txt
cat file2.txt
如图:
创建hdfs输入目录
mapreduce的程序默认需要一个hdfs的输入目录input和一个hdfs的输出目录output。
如果你的hadoop文件系统hdfs中还没有input目录则需要我们创建。
因为我们在前面已经把hadoop命令设置成了全局,否则下面的命令需要在hadoop安装的bin目录下运行。
hadoop fs -mkdir input
上传需要统计的文件到输入目录
我们之前创建的file1.txt和file2.txt是在本地目录,现在需要把它们上传才能在hadoop中使用。
hadoop fs -put file* input
hadoop fs -ls input如图:

运行单词统计mapreduce
执行命令时记得把路径写全了--最好写绝对路径,不然会提示找不到Jar包和目录。
我们前面的已经找到了自己的路径,我的是/home/joe/hadoop/hadoop-1.2.1/hadoop-examples-1.2.1.jar
hadoop jar /home/joe/hadoop/hadoop-1.2.1/hadoop-examples-1.2.1.jar wordcount /user/joe/input /user/joe/output
查看输出结果
查看输出结果的目录
hadoop fs -ls output如图:

输出的结果就在part-r-00000中
查看输出结果
hadoop fs -cat output/part-r-00000如图,统计成功,跟我们设想的一样:

下一篇我们会安装myeclipse的hadoop安装环境,找到wordcount的java代码,打包进行运行。也就是熟悉平时开发hadoop的mapreduce的工作流程。