hadoop(十三)storm流式计算(实时处理)
storm介绍
说明+安装文档
Storm是一个开源的分布式实时计算系统,可以简单、可靠的处理大量的数据流。被称作“实时的hadoop”。Storm有很多使用场景:如实时分析,在线机器学习,持续计算, 分布式RPC,ETL等等。Storm支持水平扩展,具有高容错性,保证每个消息都会得到处理,而且处理速度很快(在一个小集群中,每个结点每秒可以处理 数以百万计的消息)。Storm的部署和运维都很便捷,而且更为重要的是可以使用任意编程语言来开发应用。
高可靠性
高容错性
Storm集群和Hadoop集群表面上看很类似。Hadoop上运行的是MapReduce jobs,而在Storm上运行的是拓扑(topology);
Hadoop擅长于分布式离线批处理,而Storm设计为支持分布式实时计算;
Hadoop新的spark组件提供了在hadoop平台上运行storm的可能性
在深入理解Storm之前,需要了解一些概念:
Topologies : 拓扑,也俗称一个任务
Spouts : 拓扑的消息源
Bolts : 拓扑的处理逻辑单元
tuple:消息元组
Streams : 流
Stream groupings :流的分组策略
Tasks : 任务处理单元
Executor :工作线程
Workers :工作进程
Configuration : topology的配置
Topology 与 Mapreduce
一个关键的区别是: 一个MapReduce job最终会结束, 而一个topology永远会运行(除非你手动kill掉)
Nimbus 与 ResourManager
在Storm的集群里面有两种节点: 控制节点(master node)和工作节点(worker node)。控制节点上面运行一个叫Nimbus后台程序,它的作用类似Hadoop里面的JobTracker。Nimbus负责在集群里面分发代码,分配计算任务给机器, 并且监控状态。
Supervisor (worker进程)与NodeManager(YarnChild)
每一个工作节点上面运行一个叫做Supervisor的节点。Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程。每一个工作进程执行一个topology的一个子集;一个运行的topology由运行在很多机器上的很多工作进程组成。
storm安装
1、安装一个zookeeper集群
2、上传storm的安装包,解压
3、修改配置文件storm.yaml
#所使用的zookeeper集群主机
storm.zookeeper.servers:
- "weekend05"
- "weekend06"
- "weekend07"
#nimbus所在的主机名
nimbus.host: "weekend05"
supervisor.slots.ports
-6701
-6702
-6703
-6704
-6705
启动storm
在nimbus主机上
nohup ./storm nimbus 1>/dev/null 2>&1 &
nohup ./storm ui 1>/dev/null 2>&1 &
在supervisor主机上
nohup ./storm supervisor 1>/dev/null 2>&1 &
storm的深入学习:
分布式共享锁的实现
事务topology的实现机制及开发模式
在具体场景中的跟其他框架的整合(flume/activeMQ/kafka(分布式的消息队列系统) /redis/hbase/mysql cluster)
demo
完成
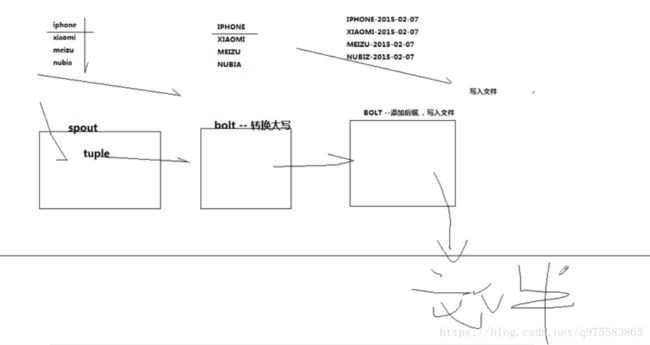
import java.util.Map;
import java.util.Random;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
public class RandomWordSpout extends BaseRichSpout{
private SpoutOutputCollector collector;
//模拟一些数据
String[] words = {"iphone","xiaomi","mate","sony","sumsung","moto","meizu"};
//不断地往下一个组件发送tuple消息
//这里面是该spout组件的核心逻辑
@Override
public void nextTuple() {
//可以从kafka消息队列中拿到数据,简便起见,我们从words数组中随机挑选一个商品名发送出去
Random random = new Random();
int index = random.nextInt(words.length);
//通过随机数拿到一个商品名
String godName = words[index];
//将商品名封装成tuple,发送消息给下一个组件
collector.emit(new Values(godName));
//每发送一个消息,休眠500ms
Utils.sleep(500);
}
//初始化方法,在spout组件实例化时调用一次
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
//声明本spout组件发送出去的tuple中的数据的字段名
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("orignname"));
}
}
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class UpperBolt extends BaseBasicBolt{
//业务处理逻辑
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
//先获取到上一个组件传递过来的数据,数据在tuple里面
String godName = tuple.getString(0);
//将商品名转换成大写
String godName_upper = godName.toUpperCase();
//将转换完成的商品名发送出去
collector.emit(new Values(godName_upper));
}
//声明该bolt组件要发出去的tuple的字段
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("uppername"));
}
}import java.io.FileWriter;
import java.io.IOException;
import java.util.Map;
import java.util.UUID;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple;
public class SuffixBolt extends BaseBasicBolt{
FileWriter fileWriter = null;
//在bolt组件运行过程中只会被调用一次
@Override
public void prepare(Map stormConf, TopologyContext context) {
try {
fileWriter = new FileWriter("/home/hadoop/stormoutput/"+UUID.randomUUID());
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//该bolt组件的核心处理逻辑
//每收到一个tuple消息,就会被调用一次
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
//先拿到上一个组件发送过来的商品名称
String upper_name = tuple.getString(0);
String suffix_name = upper_name + "_itisok";
//为上一个组件发送过来的商品名称添加后缀
try {
fileWriter.write(suffix_name);
fileWriter.write("\n");
fileWriter.flush();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//本bolt已经不需要发送tuple消息到下一个组件,所以不需要再声明tuple的字段
@Override
public void declareOutputFields(OutputFieldsDeclarer arg0) {
}
}import backtype.storm.Config;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.generated.StormTopology;
import backtype.storm.topology.TopologyBuilder;
/**
* 组织各个处理组件形成一个完整的处理流程,就是所谓的topology(类似于mapreduce程序中的job)
* 并且将该topology提交给storm集群去运行,topology提交到集群后就将永无休止地运行,除非人为或者异常退出
* @author [email protected]
*
*/
public class TopoMain {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
//将我们的spout组件设置到topology中去
//parallelism_hint :4 表示用4个excutor来执行这个组件
//setNumTasks(8) 设置的是该组件执行时的并发task数量,也就意味着1个excutor会运行2个task
builder.setSpout("randomspout", new RandomWordSpout(), 4).setNumTasks(8);
//将大写转换bolt组件设置到topology,并且指定它接收randomspout组件的消息
//.shuffleGrouping("randomspout")包含两层含义:
//1、upperbolt组件接收的tuple消息一定来自于randomspout组件
//2、randomspout组件和upperbolt组件的大量并发task实例之间收发消息时采用的分组策略是随机分组shuffleGrouping
builder.setBolt("upperbolt", new UpperBolt(), 4).shuffleGrouping("randomspout");
//将添加后缀的bolt组件设置到topology,并且指定它接收upperbolt组件的消息
builder.setBolt("suffixbolt", new SuffixBolt(), 4).shuffleGrouping("upperbolt");
//用builder来创建一个topology
StormTopology demotop = builder.createTopology();
//配置一些topology在集群中运行时的参数
Config conf = new Config();
//这里设置的是整个demotop所占用的槽位数,也就是worker的数量
conf.setNumWorkers(4);
conf.setDebug(true);
conf.setNumAckers(0);
//将这个topology提交给storm集群运行
StormSubmitter.submitTopology("demotopo", conf, demotop);
}
}