大数据学习系列之五 ----- Hive整合HBase图文详解
引言
在上一篇 大数据学习系列之四 —– Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 —– HBase环境搭建(单机) 中成功搭建了Hive和HBase的环境,并进行了相应的测试。本文主要讲的是如何将Hive和HBase进行整合。
Hive和HBase的通信意图
Hive与HBase整合的实现是利用两者本身对外的API接口互相通信来完成的,其具体工作交由Hive的lib目录中的hive-hbase-handler-*.jar工具类来实现,通信原理如下图所示。
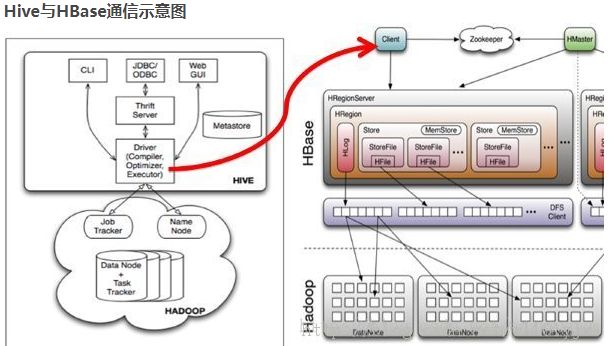
Hive整合HBase后的使用场景:
(一)通过Hive把数据加载到HBase中,数据源可以是文件也可以是Hive中的表。
(二)通过整合,让HBase支持JOIN、GROUP等SQL查询语法。
(三)通过整合,不仅可完成HBase的数据实时查询,也可以使用Hive查询HBase中的数据完成复杂的数据分析。
一、环境选择
1,服务器选择
本地虚拟机
操作系统:linux CentOS 7
Cpu:2核
内存:2G
硬盘:40G
2,配置选择
JDK:1.8 (jdk-8u144-linux-x64.tar.gz)
Hadoop:2.8.2 (hadoop-2.8.2.tar.gz)
Hive: 2.1 (apache-hive-2.1.1-bin.tar.gz)
HBase:1.6.2 (hbase-1.2.6-bin.tar.gz)
3,下载地址
官网地址
JDK:
http://www.oracle.com/technetwork/java/javase/downloads
Hadopp:
http://www.apache.org/dyn/closer.cgi/hadoop/common
Hive
http://mirror.bit.edu.cn/apache/hive/
HBase:
http://mirror.bit.edu.cn/apache/hbase/
百度云盘
链接:https://pan.baidu.com/s/1jIemIDC 密码:uycu
二、服务器的相关配置
在配置Hadoop+Hive+HBase之前,应该先做一下配置。
做这些配置为了方便,使用root权限。
1,更改主机名
首先更改主机名,目的是为了方便管理。
输入:
hostname 查看本机的名称
然后更改主机名为master
输入:
hostnamectl set-hostname master注:主机名称更改之后,要重启(reboot)才会生效。
2,做IP和主机名的映射
修改hosts文件,做关系映射
输入
vim /etc/hosts添加
主机的ip 和 主机名称
192.168.238.128 master3,关闭防火墙
关闭防火墙,方便访问。
CentOS 7版本以下输入:
关闭防火墙
service iptables stopCentOS 7 以上的版本输入:
systemctl stop firewalld.service4,时间设置
查看当前时间
输入:
date查看服务器时间是否一致,若不一致则更改
更改时间命令
date -s ‘MMDDhhmmYYYY.ss’5,整体的环境配置
/etc/profile 的整体配置
#Java Config
export JAVA_HOME=/opt/java/jdk1.8
export JRE_HOME=/opt/java/jdk1.8/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
# Scala Config
export SCALA_HOME=/opt/scala/scala-2.12.2
# Spark Config
export SPARK_HOME=/opt/spark/spark1.6-hadoop2.4-hive
# Zookeeper Config
export ZK_HOME=/opt/zookeeper/zookeeper3.4
# HBase Config
export HBASE_HOME=/opt/hbase/hbase1.2
# Hadoop Config
export HADOOP_HOME=/opt/hadoop/hadoop2.8
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
# Hive Config
export HIVE_HOME=/opt/hive/hive2.1
export HIVE_CONF_DIR=${HIVE_HOME}/conf
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${ZK_HOME}/bin:${HBASE_HOME}/bin:${HIVE_HOME}/bin:$PATH
注:具体的配置以自己的为准,没有的不用配置。
三、Hadoop的环境配置
Hadoop的具体配置在大数据学习系列之一 —– Hadoop环境搭建(单机) 中介绍得很详细了。所以本文就大体介绍一下。
注:具体配置以自己的为准。
1,环境变量设置
编辑 /etc/profile 文件 :
vim /etc/profile配置文件:
export HADOOP_HOME=/opt/hadoop/hadoop2.8
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH2,配置文件更改
先切换到 /home/hadoop/hadoop2.8/etc/hadoop/ 目录下
3.2.1 修改 core-site.xml
输入:
vim core-site.xml在添加:
<configuration>
<property>
<name>hadoop.tmp.dirname>
<value>/root/hadoop/tmpvalue>
<description>Abase for other temporary directories.description>
property>
<property>
<name>fs.default.namename>
<value>hdfs://master:9000value>
property>
configuration>3.2.2修改 hadoop-env.sh
输入:
vim hadoop-env.sh将${JAVA_HOME} 修改为自己的JDK路径
export JAVA_HOME=${JAVA_HOME}修改为:
export JAVA_HOME=/home/java/jdk1.83.2.3修改 hdfs-site.xml
输入:
vim hdfs-site.xml在添加:
<property>
<name>dfs.name.dirname>
/root/hadoop/dfs/name
Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.
property>
<property>
<name>dfs.data.dirname>
/root/hadoop/dfs/data
Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.
property>
<property>
<name>dfs.replicationname>
2
property>
<property>
<name>dfs.permissionsname>
false
need not permissions
property>3.2.4 修改mapred-site.xml
如果没有 mapred-site.xml 该文件,就复制mapred-site.xml.template文件并重命名为mapred-site.xml。
输入:
vim mapred-site.xml修改这个新建的mapred-site.xml文件,在节点内加入配置:
<property>
<name>mapred.job.trackername>
<value>master:9001value>
property>
<property>
<name>mapred.local.dirname>
<value>/root/hadoop/varvalue>
property>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>3,Hadoop启动
启动之前需要先格式化
切换到/home/hadoop/hadoop2.8/bin目录下
输入:
./hadoop namenode -format格式化成功后,再切换到/home/hadoop/hadoop2.8/sbin目录下
启动hdfs和yarn
输入:
start-dfs.sh
start-yarn.sh启动成功后,输入jsp查看是否启动成功
在浏览器输入 ip+8088 和ip +50070 界面查看是否能访问
能正确访问则启动成功
四、Hive的环境配置
Hive环境的具体配置在我的这篇大数据学习系列之四 —– Hadoop+Hive环境搭建图文详解(单机) 以及介绍得很详细了。本篇就大概介绍下。
修改hive-site.xml
切换到 /opt/hive/hive2.1/conf 目录下
将hive-default.xml.template 拷贝一份,并重命名为hive-site.xml
然后编辑hive-site.xml文件
cp hive-default.xml.template hive-site.xml
vim hive-site.xml编辑hive-site.xml文件,在 中添加:
<property>
<name>hive.metastore.warehouse.dirname>
<value>/root/hive/warehousevalue>
property>
<property>
<name>hive.exec.scratchdirname>
<value>/root/hivevalue>
property>
<property>
<name>hive.metastore.urisname>
<value>value>
property>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=truevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>123456value>
property>
<property>
<name>hive.metastore.schema.verificationname>
<value>falsevalue>
<description>
description>
property>然后将配置文件中所有的
${system:java.io.tmpdir}更改为 /opt/hive/tmp (如果没有该文件则创建),
并将此文件夹赋予读写权限,将
${system:user.name}
更改为 root
例如:
更改之前的:

更改之后:

配置图:
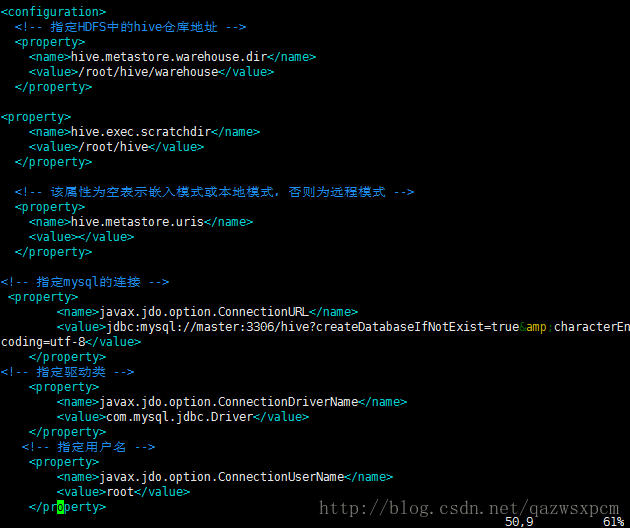
注: 由于hive-site.xml 文件中的配置过多,可以通过FTP将它下载下来进行编辑。也可以直接配置自己所需的,其他的可以删除。 MySQL的连接地址中的master是主机的别名,可以换成ip。
修改 hive-env.sh
修改hive-env.sh 文件,没有就复制 hive-env.sh.template ,并重命名为hive-env.sh
在这个配置文件中添加
export HADOOP_HOME=/opt/hadoop/hadoop2.8
export HIVE_CONF_DIR=/opt/hive/hive2.1/conf
export HIVE_AUX_JARS_PATH=/opt/hive/hive2.1/lib添加 数据驱动包
由于Hive 默认自带的数据库是使用mysql,所以这块就是用mysql
将mysql 的驱动包 上传到 /opt/hive/hive2.1/lib
五、HBase的环境配置
HBase环境的具体配置在我的这篇大数据学习系列之二 —– HBase环境搭建(单机) 以及介绍得很详细了。本篇就大概介绍下。
修改 hbase-env.sh
编辑 hbase-env.sh 文件,添加以下配置
export JAVA_HOME=/opt/java/jdk1.8
export HADOOP_HOME=/opt/hadoop/hadoop2.8
export HBASE_HOME=/opt/hbase/hbase1.2
export HBASE_CLASSPATH=/opt/hadoop/hadoop2.8/etc/hadoop
export HBASE_PID_DIR=/root/hbase/pids
export HBASE_MANAGES_ZK=false说明:配置的路径以自己的为准。HBASE_MANAGES_ZK=false 是不启用HBase自带的Zookeeper集群。
修改 hbase-site.xml
编辑hbase-site.xml 文件,在添加如下配置
<property>
<name>hbase.rootdirname>
<value>hdfs://test1:9000/hbasevalue>
<description>The directory shared byregion servers.description>
property>
<property>
<name>hbase.zookeeper.property.clientPortname>
<value>2181value>
<description>Property from ZooKeeper'sconfig zoo.cfg. The port at which the clients will connect.
description>
property>
<property>
<name>zookeeper.session.timeoutname>
<value>120000value>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>test1value>
property>
<property>
<name>hbase.tmp.dirname>
<value>/root/hbase/tmpvalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>falsevalue>
property>说明:hbase.rootdir:这个目录是region server的共享目录,用来持久化Hbase 。hbase.cluster.distributed :Hbase的运行模式。false是单机模式,true是分布式模式。若为false,Hbase和Zookeeper会运行在同一个JVM里面。
六、Hive整合HBase的环境配置以及测试
1,环境配置
因为Hive与HBase整合的实现是利用两者本身对外的API接口互相通信来完成的,其具体工作交由Hive的lib目录中的hive-hbase-handler-.jar工具类来实现。所以只需要将hive的 hive-hbase-handler-.jar 复制到hbase/lib中就可以了。
切换到hive/lib目录下
输入:
cp hive-hbase-handler-*.jar /opt/hbase/hbase1.2/lib
注: 如果在hive整合hbase中,出现版本之类的问题,那么以hbase的版本为主,将hbase中的jar包覆盖hive的jar包。
2,hive和hbase测试
在进行测试的时候,确保hadoop、hbase、hive环境已经成功搭建好,并且都成功启动了。
打开xshell的两个命令窗口
一个进入hive,一个进入hbase
6.2.1在hive中创建映射hbase的表
在hive中创建一个映射hbase的表,为了方便,设置两边的表名都为t_student,存储的表也是这个。
在hive中输入:
create table t_student(id int,name string) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties("hbase.columns.mapping"=":key,st1:name") tblproperties("hbase.table.name"="t_student","hbase.mapred.output.outputtable" = "t_student");**说明:第一个t_student 是hive表中的名称,第二个t_student是定义在hbase的table名称 ,第三个t_student 是存储数据表的名称(“hbase.mapred.output.outputtable” = “t_student”这个可以不要,表数据就存储在第二个表中了) 。
(id int,name string) 这个是hive表结构。如果要增加字段,就以这种格式增加。如果要增加字段的注释,那么在字段后面添加comment ‘你要描述的’。
例如:
create table t_student(id int comment ‘StudentId’,name string comment ‘StudentName’)
org.apache.hadoop.hive.hbase.HBaseStorageHandler 这个是指定的存储器。
hbase.columns.mapping 是定义在hbase的列族。
例如:st1就是列族,name就是列。在hive中创建表t_student,这个表包括两个字段(int型的id和string型的name)。 映射为hbase中的表t_student,key对应hbase的rowkey,value对应hbase的st1:name列。**
表成功创建之后
在hive、hbase分别中查看表和表结构
hive中输入
show tables;
describe t_student;hbase输入:
list
describe ‘t_student’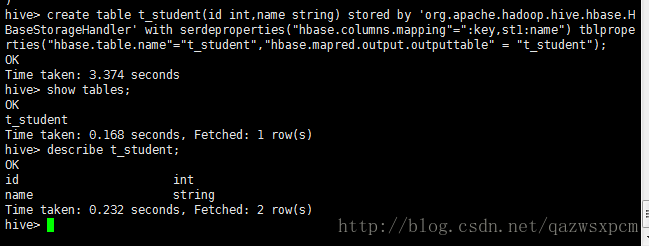
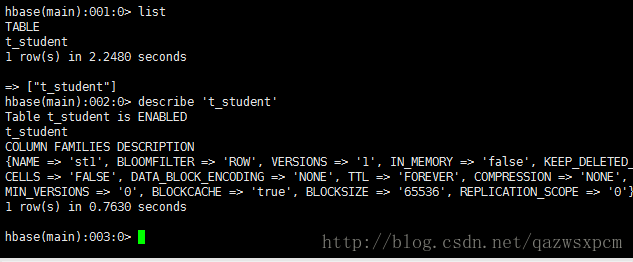
可以看到表已经成功的创建了
6.2.2数据同步测试
进入hbase之后
在t_student中添加两条数据 然后查询该表
put 't_student','1001','st1:name','zhangsan'
put 't_student','1002','st1:name','lisi'
scan 't_student'
然后切换到hive中
查询该表
输入:
select * from t_student;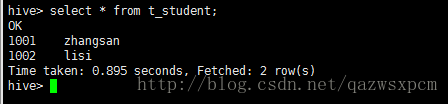
然后在hive中删除该表
注:因为做测试要看结果,所以将表删除了。如果同学们要做测试的话,是没有必要删除该表的,因为在后面还会使用该表。
然后查看hive和hbase中的表是否删除了
输入:
drop table t_student;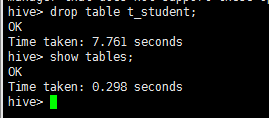

通过这些可以看到hive和hbase之间的数据成功同步!
6.2.3关联查询测试
hive外部表测试
先在hbase中建一张t_student_info表,添加两个列族
然后查看表结构
输入:
create 't_student_info','st1','st2'
describe 't_student_info'
然后在hive中创建外部表
说明:创建外部表要使用EXTERNAL 关键字
输入:
create external table t_student_info(id int,age int,sex string) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties("hbase.columns.mapping"=":key,st1:age,st2:sex") tblproperties("hbase.table.name"="t_student_info");
然后在t_student_info 中添加数据
put 't_student_info','1001','st2:sex','man'
put 't_student_info','1001','st1:age','20'
put 't_student_info','1002','st1:age','18'
put 't_student_info','1002','st2:sex','woman'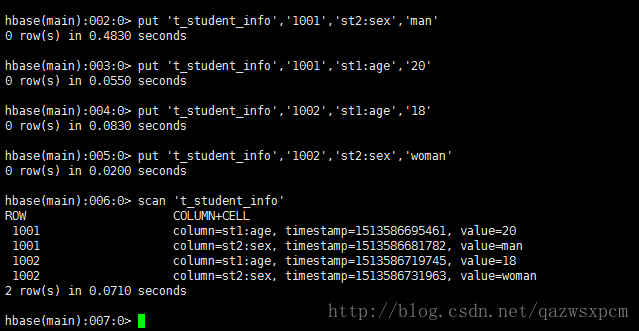
然后在hive中查询该表
输入:
select * from t_student_info;
查询到数据之后,然后将t_student 和t_student_info进行关联查询。
输入:
select * from t_student t join t_student ti where t.id=ti.id ;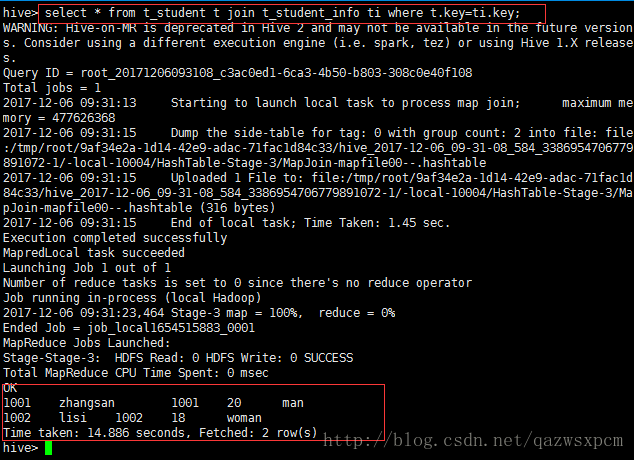
说明:通过关联查询,可以得出表之间是可以关联查询的。但是明显看到hive 使用默认的mapreduce 作为引擎是多么的慢。。。
**其他说明:
由于自己的虚拟机配置实在太渣,即使调大reduce内存,限制每个reduce处理的数据量,还是不行,最后没办法使用公司的测试服务进行测试。
在查询一张表的时候,hive没有使用引擎,因此相对比较快,如果是进行了关联查询之类的,就会使用引擎,由于hive默认的引擎是mr,所以会很慢,也和配置有一定关系,hive2.x以后官方就不建议使用mr了。**
本文到此结束,谢谢阅读!
版权声明:
作者:虚无境
博客园出处:http://www.cnblogs.com/xuwujing
CSDN出处:http://blog.csdn.net/qazwsxpcm
个人博客出处:http://www.panchengming.com
原创不易,转载请标明出处,谢谢!