探讨kafka的分区数与多线程消费
kafka算是很麻烦的一件事儿,起因是最近需要采集大量的数据,原先是只用了典型的high-level Consumer的API,最经典的不过如下:
- Properties props = new Properties();
- props.put("zookeeper.connect", "xxxx:2181");
- props.put("zookeeper.connectiontimeout.ms", "1000000");
- props.put("group.id", "test_group");
- props.put("zookeeper.session.timeout.ms", "40000");
- props.put("zookeeper.sync.time.ms", "200");
- props.put("auto.commit.interval.ms", "1000");
- ConsumerConfig consumerConfig = new ConsumerConfig(props);
- ConsumerConnector consumerConnector = Consumer.createJavaConsumerConnector(consumerConfig);
- Map
- topicCountMap.put("test", new Integer(1));
- //key--topic
- Map
- consumerConnector.createMessageStreams(topicCountMap);
- KafkaStream<byte[], byte[]> stream = consumerMap.get("test").get(0);
- ConsumerIterator<byte[], byte[]> it = stream.iterator();
- StringBuffer sb = new StringBuffer();
- while(it.hasNext()) {
- try {
- String msg = new String(it.next().message(), "utf-8").trim();
- System.out.println("receive:" + msg);
- } catch (UnsupportedEncodingException e) {
- e.printStackTrace();
- }
- }
这是典型的kafka消费端消费数据的代码,但可以看出这是十分典型的单线程消费。在本地玩玩熟悉kafka还行,(就跟入门java学会写main方法打印hello world一样~~~~),问题是学的东西必须真正应用到实际中,你不可能只在单线程采集里原地打转吧。。so,多线程采集迫在眉急啊!!
本人研究卡夫卡多线程消费还是耗了一段时间的,希望把过程尽可能完整地记录下来,以便各位同行有需要可以参考。。
首先,最好理解kafka的基本原理和一些基本概念,阅读官网文档很有必要,这样才会有一个比较清晰的概念,而不是跟无头苍蝇一样乱撞——出了错去网上查是灰常痛苦滴!!
http://kafka.apache.org/documentation.html
好了,大概说下卡夫卡的“分区·”的概念吧:
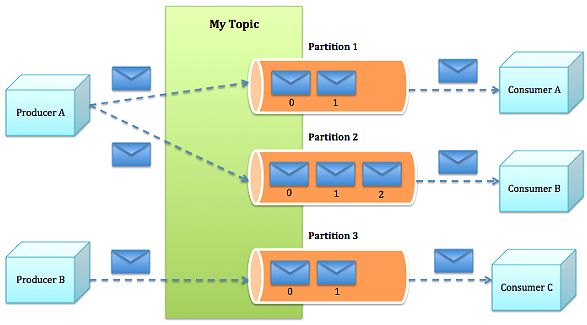
这张图比较清晰地描述了“分区”的概念,对于某一个topic的消息来说,我们可以把这组消息发送给若干个分区,就相当于一组消息分发一样。
分区、Offset、消费线程、group.id的关系
1)一组(类)消息通常由某个topic来归类,我们可以把这组消息“分发”给若干个分区(partition),每个分区的消息各不相同;
2)每个分区都维护着他自己的偏移量(Offset),记录着该分区的消息此时被消费的位置;
3)一个消费线程可以对应若干个分区,但一个分区只能被具体某一个消费线程消费;
4)group.id用于标记某一个消费组,每一个消费组都会被记录他在某一个分区的Offset,即不同consumer group针对同一个分区,都有“各自”的偏移量。
说完概念,必须要注意的一点是,必须确认卡夫卡的server.properties里面的一个属性num.partitions必须被设置成大于1的值,否则消费端再怎么折腾,也用不了多线程哦。我这里的环境下,该属性值被设置成10了。
重构一下上述经典的消费端代码:
- public class KafakConsumer implements Runnable {
- private ConsumerConfig consumerConfig;
- private static String topic="blog";
- Properties props;
- final int a_numThreads = 6;
- public KafakConsumer() {
- props = new Properties();
- props.put("zookeeper.connect", "xxx:2181,yyy:2181,zzz:2181");
- // props.put("zookeeper.connect", "localhost:2181");
- // props.put("zookeeper.connectiontimeout.ms", "30000");
- props.put("group.id", "blog");
- props.put("zookeeper.session.timeout.ms", "400");
- props.put("zookeeper.sync.time.ms", "200");
- props.put("auto.commit.interval.ms", "1000");
- props.put("auto.offset.reset", "smallest");
- consumerConfig = new ConsumerConfig(props);
- }
- @Override
- public void run() {
- Map
- topicCountMap.put(topic, new Integer(a_numThreads));
- ConsumerConfig consumerConfig = new ConsumerConfig(props);
- ConsumerConnector consumer = kafka.consumer.Consumer.createJavaConsumerConnector(consumerConfig);
- Map
- List
- ExecutorService executor = Executors.newFixedThreadPool(a_numThreads);
- for (final KafkaStream stream : streams) {
- executor.submit(new KafkaConsumerThread(stream));
- }
- }
- public static void main(String[] args) {
- System.out.println(topic);
- Thread t = new Thread(new KafakConsumer());
- t.start();
- }
- }
从这段重构的代码可以看出,KafkaStream
其中,具体消费线程KafkaConsumerThread代码为:
- public class KafkaConsumerThread implements Runnable {
- private KafkaStream<byte[], byte[]> stream;
- public KafkaConsumerThread(KafkaStream<byte[], byte[]> stream) {
- this.stream = stream;
- }
- @Override
- public void run() {
- ConsumerIterator<byte[], byte[]> it = stream.iterator();
- while (it.hasNext()) {
- MessageAndMetadata<byte[], byte[]> mam = it.next();
- System.out.println(Thread.currentThread().getName() + ": partition[" + mam.partition() + "],"
- + "offset[" + mam.offset() + "], " + new String(mam.message()));
- }
- }
- }
编写生产端(Producer)的代码:
- public class KafkaProducer implements Runnable {
- private Producer
- private ProducerConfig config = null;
- public KafkaProducer() {
- Properties props = new Properties();
- props.put("zookeeper.connect", "*****:2181,****:2181,****:2181");
- // props.put("zookeeper.connect", "localhost:2181");
- // 指定序列化处理类,默认为kafka.serializer.DefaultEncoder,即byte[]
- props.put("serializer.class", "kafka.serializer.StringEncoder");
- // 同步还是异步,默认2表同步,1表异步。异步可以提高发送吞吐量,但是也可能导致丢失未发送过去的消息
- props.put("producer.type", "sync");
- // 是否压缩,默认0表示不压缩,1表示用gzip压缩,2表示用snappy压缩。压缩后消息中会有头来指明消息压缩类型,故在消费者端消息解压是透明的无需指定。
- props.put("compression.codec", "1");
- // 指定kafka节点列表,用于获取metadata(元数据),不必全部指定
- props.put("broker.list", "****:6667,***:6667,****:6667");
- config = new ProducerConfig(props);
- }
- @Override
- public void run() {
- producer = new Producer
- // for(int i=0; i<10; i++) {
- // String sLine = "I'm number " + i;
- // KeyedMessage
- // producer.send(msg);
- // }
- for(int i = 1; i <= 6; i++){ //往6个分区发数据
- List
- for(int j = 0; j < 6; j++){ //每个分区6条讯息
- messageList.add(new KeyedMessage
- //String topic, String partition, String message
- ("blog", "partition[" + i + "]", "message[The " + i + " message]"));
- }
- producer.send(messageList);
- }
- }
- public static void main(String[] args) {
- Thread t = new Thread(new KafkaProducer());
- t.start();
- }
- }
上述生产端代码相对传统的发送端代码也做了改进,首先是用了批量发送(源码):
- public void send(List
- {
- underlying().send(JavaConversions..MODULE$.asScalaBuffer(messages).toSeq());
- }
而不是:
- public void send(KeyedMessage
- {
- underlying().send(Predef..MODULE$.wrapRefArray((Object[])new KeyedMessage[] { message }));
- }
第二,KeyedMessage用的构造函数:
- public KeyedMessage(String topic, K key, V message) { this(topic, key, key, message); }
第二个参数表示分区的key。
而非:
- public KeyedMessage(String topic, V message) {
- this(topic, null, null, message);
- }
分别run一下生产和消费的代码,可以看到消费端打印结果:
pool-2-thread-5: partition[5],offset[0], message[The 5 message]
pool-2-thread-1: partition[2],offset[0], message[The 2 message]
pool-2-thread-2: partition[1],offset[0], message[The 1 message]
pool-2-thread-5: partition[4],offset[0], message[The 4 message]
pool-2-thread-1: partition[3],offset[0], message[The 3 message]
pool-2-thread-4: partition[6],offset[0], message[The 6 message]
可以看到,6个分区的数据全部被消费了,但是不妨看下消费线程:pool-2-thread-1线程同时消费了partition[2]和partition[3]的数据;pool-2-thread-2消费了partiton[1]的数据;pool-2-thread-4消费了partiton[6]的数据;而pool-2-thread-5则消费了partitoin[4]和partition[5]的数据。
从上述消费情况来看,验证了消费线程和分区的对应情况——即:一个分区只能被一个线程消费,但一个消费线程可以消费多个分区的数据!虽然我指定了线程池的线程数为6,但并不是所有的线程都去消费了,这当然跟线程池的调度有关系了。并不是一个消费线程对应地去消费一个分区的数据。
我们不妨仔细看下消费端启动日志部分,这对我们理解kafka的启动生成和消费的原理有益:
【限于篇幅,启动日志略,只分析关键部分】
消费端的启动日志表明:
1)Consumer happy_Connor-PC-1445916157267-b9cce79d rebalancing the following partitions: ArrayBuffer(0, 1, 2, 3, 4, 5, 6, 7, 8, 9) for topic blog with consumers: List(happy_Connor-PC-1445916157267-b9cce79d-0, happy_Connor-PC-1445916157267-b9cce79d-1, happy_Connor-PC-1445916157267-b9cce79d-2, happy_Connor-PC-1445916157267-b9cce79d-3, happy_Connor-PC-1445916157267-b9cce79d-4, happy_Connor-PC-1445916157267-b9cce79d-5)
happy_Connor-PC-1445916157267-b9cce79d表示一个消费组,该topic可以使用10个分区:the following partitions: ArrayBuffer(0, 1, 2, 3, 4, 5, 6, 7, 8, 9) for topic blog。然后定义了6个消费线程,List(happy_Connor-PC-1445916157267-b9cce79d-0, happy_Connor-PC-1445916157267-b9cce79d-1, happy_Connor-PC-1445916157267-b9cce79d-2, happy_Connor-PC-1445916157267-b9cce79d-3, happy_Connor-PC-1445916157267-b9cce79d-4, happy_Connor-PC-1445916157267-b9cce79d-5)。消费线程的个数由topicCountMap.put(String topic, Integer count)的第二个参数决定。但真正去消费的线程还是由线程池的调度机制来决定;
2)线程由zookeeper来声明它拥有1个或多个分区;
3)真正有数据存在的分区是由生产发送端来决定,即使你的kafka设置了10个分区,消费端在消费的时候,消费线程虽然会根据zookeeper的某种机制来声明它所消费的分区,但实际消费过程中,还是会消费真正存在数据的分区。(本例中,你只往6个分区push了数据,所以即使你声明了10个分区,你也只能消费6个分区的数据)。
如果把topicCountMap的第二个参数Integer值改成1,发送端改成往7个分区发数据再测试,可得到消费端的打印结果:
- pool-2-thread-1: partition[6],offset[0], message[The 6 message]
- pool-2-thread-1: partition[3],offset[0], message[The 3 message]
- pool-2-thread-1: partition[2],offset[0], message[The 2 message]
- pool-2-thread-1: partition[5],offset[0], message[The 5 message]
- pool-2-thread-1: partition[4],offset[0], message[The 4 message]
- pool-2-thread-1: partition[7],offset[0], message[The 7 message]
- pool-2-thread-1: partition[1],offset[0], message[The 1 message]
可以看出,如果你topicCountMap的值改成1,而 List
下面再来模拟一些状况:
状况一:往大于实际分区数的分区发数据,比如发送端的第一层循环设为11:
可看到消费端此时虽能正常的完全消费这10个分区的数据,但生产端会报异常:
No partition metadata for topic blog4 due to kafka.common.LeaderNotAvailableException}] for topic [blog4]: class kafka.common.LeaderNotAvailableException
这说明,你往partition11发送失败,因为卡夫卡已经设置了10个分区,你再往不存在的分区数发当然会报错了。
状况二:发送端用传统的发送方法,即KeyedMessage的构造函数只有topic和Message
- //针对topic创建一个分区并发送数据
- List
- for(int i = 1; i <= 10; i++){
- messageList.add(new KeyedMessage
- }
- producer.send(messageList);
消费端打印结果:
pool-2-thread-1: partition[7],offset[0], 我是发送的内容message1
pool-2-thread-1: partition[7],offset[1], 我是发送的内容message2
pool-2-thread-1: partition[7],offset[2], 我是发送的内容message3
pool-2-thread-1: partition[7],offset[3], 我是发送的内容message4
pool-2-thread-1: partition[7],offset[4], 我是发送的内容message5
pool-2-thread-1: partition[7],offset[5], 我是发送的内容message6
pool-2-thread-1: partition[7],offset[6], 我是发送的内容message7
pool-2-thread-1: partition[7],offset[7], 我是发送的内容message8
pool-2-thread-1: partition[7],offset[8], 我是发送的内容message9
pool-2-thread-1: partition[7],offset[9], 我是发送的内容message10
这表明,只用了1个消费线程消费1个分区的数据。这说明,如果发送端发送数据没有指定分区,即用的是
- public KeyedMessage(String topic,V message) { this(topic, key, key, message); }
- sendMessage(KeyedMessage(String topic,V message))
的话,同样达不到多线程消费的效果!
状况三:将线程池的大小设置成比topicCountMap的value值小?
- topicCountMap.put(topic, new Integer(7));
- //......................
- ExecutorService executor = Executors.newFixedThreadPool(5);
发送端往9个分区发送数据,run一下,会发现消费端打印结果:
pool-2-thread-3: partition[7],offset[0], message[The 7 message]
pool-2-thread-5: partition[1],offset[0], message[The 1 message]
pool-2-thread-4: partition[4],offset[0], message[The 4 message]
pool-2-thread-2: partition[3],offset[0], message[The 3 message]
pool-2-thread-4: partition[5],offset[0], message[The 5 message]
pool-2-thread-1: partition[8],offset[0], message[The 8 message]
pool-2-thread-2: partition[2],offset[0], message[The 2 message]
你会发现:虽然我生产发送端往9个分区发送了数据,但实际上只消费掉了7个分区的数据。(如果你再跑一边,可能又是6个分区的数据)——这说明,有的分区的数据没有被消费,原因只可能是线程不够。so,当线程池中的大小小于分区数时,会出现有的分区没有被采集的情况。建议设置:实际发送分区数(一般就等于设置的分区数)= topicCountMap的value = 线程池大小 否则极易出现reblance的异常!!!
好了,折腾这么久。我们可以看出,卡夫卡如果想要多线程消费提高效率的话,就可以从分区数上下手,分区数就是用来做并行消费的而且生产端的发送代码也很有讲究。(这只是针对某一个topic而言,当然实际情况中,你可以一个topic一个线程,同样达到多线程效果,当然这是后话了)