【嵌入式基础】2019大疆嵌入式笔试题A卷(附超详细解答)
原文地址
前不久的大疆嵌入式线上笔试,可能是因为最近只是在做毕设项目,还没有来得及认真系统复习,直接崩了。就凭借着记忆,把一些记得住的笔试题分享一下,作下记录。
整个大疆嵌入式线上笔试,分为选择题(单选题、多选题)、填空题、简答题、编程题。也没有将所有的题目都记得,就分成填空选择题、简答题和编程题三块来介绍吧。
填空选择题
1、ARM指令和Thumb指令。(选择题)
解答:在ARM的体系结构中,可以工作在三种不同的状态,一是ARM状态,二是Thumb状态及Thumb-2状态,三是调试状态。而ARM状态和Thumb状态可以直接通过某些指令直接切换,都是在运行程序,只不过指令长度不一样而已。
- ARM状态:arm处理器工作于32位指令的状态,所有指令均为32位;
- Thumb状态:arm执行16位指令的状态,即16位状态;
- thumb-2状态:这个状态是ARM7版本的ARM处理器所具有的新的状态,新的thumb-2内核技术兼有16位及32位指令,实现了更高的性能,更有效的功耗及更少地占用内存。总的来说,感觉这个状态除了兼有arm和thumb的优点外,还在这两种状态上有所提升,优化;
- 调试状态:处理器停机时进入调试状态。
也就是说:ARM状态,此时处理器执行32位的字对齐的ARM指令;Thumb状态,此时处理器执行16位的,半字对齐的THUMB指令。
ARM状态和Thumb状态切换程序:
- 从ARM到Thumb: LDR R0,=lable+1 BX R0(状态将寄存器的最低位设置为1,BX指令、R0指令将进入thumb状态);
- 从ARM到Thumb: LDR R0,=lable BX R0(寄存器最低位设置为0,BX指令、R0指令将进入arm状态)。
- 当处理器进行异常处理时,则从异常向量地址开始执行,将自动进入ARM状态。
关于这个知识点还有几个注意点:
- ARM处理器复位后开始执行代码时总是只处于ARM状态;
- Cortex-M3只有Thumb-2状态和调试状态;
- 由于Thumb-2具有16位/32位指令功能,因此有了thumb-2就无需Thumb了。
另外,具有Thumb-2技术的ARM处理器也无需再ARM状态和Thumb-2状态间进行切换了,因为thumb-2具有32位指令功能。
参考文章:ARM处理器的工作状态。
2、哪种总线方式是全双工类型、哪种总线方式传输的距离最短?(选择题)
解答:几种总线接口的通信方式的总结如下图所示:
| 总线接口 | 串/并 | 同步/异步 | 速率 | 工作方式 | 用线 | 总线拓扑结构 | 信距离 |
| UART | 串 | 异步 | 慢 波特率设置 |
全双工 | 2线 Rx、Tx |
RS485支持总线式、 星形、树形 |
远 最远1200m |
| I2C |
串 |
同步 |
慢 |
半双工 |
2线 SDA、SCL |
总线型(特殊的树形) |
近 |
| SPI |
串 |
同步 |
快 |
全双工 |
3线或4线 SCLK、SIMO、 SOMI、SS(片选) |
环形 |
远 |
| USB |
串 |
同步 |
快 |
半双工 |
4线 Vbus(5V)、GND、D+、D-(3.3V) |
星形 |
近 |
3、TCP与UCP的区别。(选择题)
解答:TCP和UCP的区别总结如下图所示:
| 角度 | TCP | UCP |
| 是否连接 | 面向连接(发送数据前需要建立连接) | 无连接(发送数据无需连接) |
| 是否丢包重试 | 实现了数据传输时各种控制功能,可以进行丢包的重发控制, 还可以对次序乱掉的分包进行顺序控制 |
不会进行丢包重试,也不会纠正到达的顺序 |
| 模式 | 流模式(面向字节流) | 数据报模式(面向报文) |
| 对应关系 | 一对一 | 支持一对一,一对多,多对一和多对多的交互通信 |
| 头部开销 | 最小20字节 | 只有8字节 |
| 可靠性 | 全双工非常可靠、无差错、不丢失、不重复、且按序到达 | 不保证可靠交付,不保证顺序到达 |
| 拥塞控制 | 有控制 更多详情 | 有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低 (对实时应用很有用,如IP电话,实时视频会议等) |
| 资源要求 | TCP程序结构较复杂,较多 | UDP程序结构简单,少 |
参考文章:一看就懂系列之 超级详解TCP与UDP。
4、Linux的用户态与内核态的转换方法。(选择题)
解答:Linux下内核空间与用户空间进行通信的方式主要有syscall(system call)、procfs、ioctl和netlink等。
- syscall:一般情况下,用户进程是不能访问内核的。它既不能访问内核所在的内存空间,也不能调用内核中的函数。Linux内核中设置了一组用于实现各种系统功能的子程序,用户可以通过调用他们访问linux内核的数据和函数,这些系统调用接口(SCI)称为系统调用;
- procfs:是一种特殊的伪文件系统 ,是Linux内核信息的抽象文件接口,大量内核中的信息以及可调参数都被作为常规文件映射到一个目录树中,这样我们就可以简单直接的通过echo或cat这样的文件操作命令对系统信息进行查取;
- netlink:用户态应用使用标准的 socket API 就可以使用 netlink 提供的强大功能;
- ioctl:函数是文件结构中的一个属性分量,就是说如果你的驱动程序提供了对ioctl的支持,用户就可以在用户程序中使用ioctl函数控制设备的I/O通道。
5、linux目录结构,选项是/usr、/tmp、/etc目录的作用。(选择题)
解答:linux目录图:
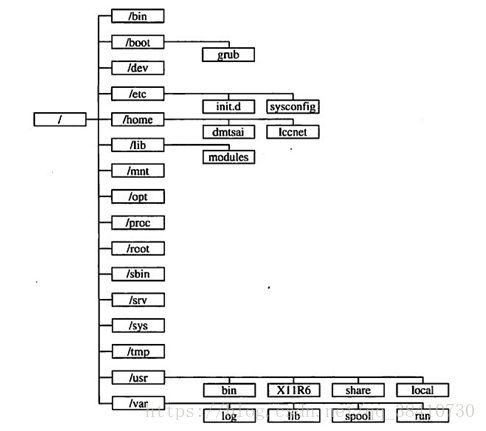
- /usr:不是user的缩写,其实usr是Unix Software Resource的缩写, 也就是Unix操作系统软件资源所放置的目录,而不是用户的数据啦。这点要注意。 FHS建议所有软件开发者,应该将他们的数据合理的分别放置到这个目录下的次目录,而不要自行建立该软件自己独立的目录;
- /tmp:这是让一般使用者或者是正在执行的程序暂时放置档案的地方。这个目录是任何人都能够存取的,所以你需要定期的清理一下。当然,重要资料不可放置在此目录啊。 因为FHS甚至建议在开机时,应该要将/tmp下的资料都删除;
- /etc:系统主要的设定档几乎都放置在这个目录内,例如人员的帐号密码档、各种服务的启始档等等。 一般来说,这个目录下的各档案属性是可以让一般使用者查阅的,但是只有root有权力修改。 FHS建议不要放置可执行档(binary)在这个目录中。 比较重要的档案有:/etc/inittab, /etc/init.d/, /etc/modprobe.conf, /etc/X11/, /etc/fstab, /etc/sysconfig/等等。
参考文章:Linux文件目录结构详解。
6、下面这段程序的运行结果?(选择题)
-
int main(){ -
const int x=5; -
const int *ptr; -
ptr=&x; -
*ptr=10; -
printf("%d\n",x); -
return 0; -
}
解答:编译出错。
这道题主要是讲解const与指针的问题:
-
const int a; -
int const a; -
const int *a; -
int * const a; -
const int * const a; -
int const * const a;
- 前两个的作用是一样,a是一个常整型数;
- 第三个意味着a是一个指向常整型数的指针(也就是,整型数是不可修改的,但指针可以);
- 第四个意思a是一个指向整型 数的常指针(也就是说,指针指向的整型数是可以修改的,但指针是不可修改的);
- 最后两个意味着a是一个指向常整型数的常指针(也就是说,指针指向的整型数 是不可修改的,同时指针也是不可修改的)。
也就是说:本题x是一个常量,不能改变;ptr是一个指向常整型数的指针。而当*ptr=10;的时候,直接违反了这一点。同时要记得一点,const是通过编译器在编译的时候执行检查来确保实现的。
7、在32位系统中,有如下结构体,那么sizeof(fun)的数值是()
-
#pragma pack(1) -
struct fun{ -
int i; -
double d; -
char c; -
};
解答:13。
可能是一般的内存对齐做习惯了,如果本题采用内存对齐的话,结果就是24(int 4 double char 7)。但是#pragma pack(1)让编译器将结构体数据强制按1来对齐。
每个特定平台上的编译器都有自己的默认“对齐系数”(32位机一般为4,64位机一般为8)。我们可以通过预编译命令#pragma pack(k),k=1,2,4,8,16来改变这个系数,其中k就是需要指定的“对齐系数”。
只需牢记:
- 第一个数据成员放在offset为0的地方,对齐按照对齐系数和自身占用字节数中,二者比较小的那个进行对齐;
- 在数据成员完成各自对齐以后,struct或者union本身也要进行对齐,对齐将按照对齐系数和struct或者union中最大数据成员长度中比较小的那个进行;
参考文章:#pragma pack()的解读。
8、Linux中的文件/目录权限设置命令是什么?(选择题)
解答:chmod
9、下面四个选项是四个整数在内存中的存储情况,请选择其中最大的一个。(选择题)
| A | B | C | D |
| Big-endian 低地址 高地址 12 34 56 78 |
Big-endian 低地址 高地址 56 78 12 34 |
Little-endian 低地址 高地址 34 56 78 12 |
Little-endian 低地址 高地址 78 12 34 56 |
解答:大端小端问题:
- 所谓的大端模式(BE big-endian),是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中(低对高,高对高);
- 所谓的小端模式(LE little-endian),是指数据的低位保存在内存的低地址中,而数据的高位保存在内存的高地址中(低对低,高对高)。
那么A:12345678、B:56781234、C:12785634、D:56341278。
10、C语言的各种变量的存取区域,给你一段小程序,让你分析各个变量的存储区域(填空题)
解答:具体的题目内容忘了,但是大体上给出各个变量可能的存储区域:
- 堆:堆允许程序在运行时动态地申请某个大小的内存。一般由程序员分配释放;
- 栈:由编译器自动分配释放,存放函数的参数值,局部变量等值;
- 静态存储区:一定会存在且不会消失,这样的数据包括常量、常变量(const 变量)、静态变量、全局变量等;
- 常量存储区:常量占用内存,只读状态,决不可修改,常量字符串就是放在这里的。
11、下面这段程序的运行结果?(填空题)
-
int main() { -
int a[10] = { 0,1,2,3,4,5,6,7,8,9 }; -
memcpy(a + 3, a, 5); -
for (int i = 0; i<10; i++){ -
printf("%d ", a[i]); -
} -
return 0; -
}
解答:0 1 2 0 1 5 6 7 8 9
首先看一下内存复制函数memcpy()函数的定义:
void * memcpy ( void * destination, const void * source, size_t num );将source指向的地址处的 num 个字节 拷贝到 destination 指向的地址处。注意,是字节。
因为memcpy的最后一个参数是需要拷贝的字节的数目!一个int类型占据4个字节!这样的话,本题5字节,实际上只能移动2个数字(往大的去)。如果要想达到将a地址开始的5个元素拷贝到a+3地址处,需要这么写:
memcpy(a + 3, a, 5*sizeof(int));参考文章:memcpy使用时需要注意的地方。
12、C语言编译过程中,volatile关键字和extern关键字分别在哪个阶段起作用?(填空题)
解答:volatile应该是在编译阶段,extern在链接阶段。
volatile关键字的作用是防止变量被编译器优化,而优化是处于编译阶段,所以volatile关键字是在编译阶段起作用。
参考文章:C语言文件的编译与执行的四个阶段并分别描述和volatile为什么要修饰中断里的变量。
13、linux系统打开设备文件,进程可能处于三种基本状态,如果多次打开设备文件,驱动程序应该实现什么?(填空题)
不太清楚……
简答题
1、简述实时操作系统和非实时操作系统特点和区别。
解答:实时操作系统是保证在一定时间限制内完成特定功能的操作系统。实时操作系统有硬实时和软实时之分,硬实时要求在规定的时间内必须完成操作,这是在操作系统设计时保证的;软实时则只要按照任务的优先级,尽可能快地完成操作即可。
实时性最主要的含义是:任务的最迟完成时间是可确认预知的。
| 比较项目 | 非实时系统 | 实时系统 |
| 交互能力 | 较强 | 较弱 |
| 响应时间 | 秒集 | 毫秒、微秒级 |
| 可靠性 | 一般 | 较高 |
| 进程完成的截止期限 | 没有 | 有 |
| 进程切换的要求 | 一般 | 快 |
| 内核 | 非可剥夺(体现公平) | 可剥夺(体现优先级别) |
2、简述static关键字对于工程模块化的作用。
解答:在C语言中,static有下3个作用:
- 函数体内的static变量的作用范围为该函数体,不同于auto变量,该变量的内存只被分配一次,以为其值在下次调用时仍维持上次的值(该变量存放在静态变量区);
- 在模块内static全局变量可以被模块内所有函数访问,但不能被模块外其他函数访问。(注意,只有在定义了变量后才能使用。如果变量定义在使用之后,要用extern 声明。所以,一般全部变量都会在文件的最开始处定义。);
- 在模块内的static函数只可被这一模块内的其他函数调用,这个函数的使用范围被限制在声明它的模块内。
在嵌入式系统中,要时刻懂得移植的重要性,程序可能是很多程序员共同协作同时完成,在定义变量及函数的过程,可能会重名,这给系统的集成带来麻烦,因此保证不冲突的办法是显示的表示此变量或者函数是本地的,static即可。在Linux的模块编程中,这一条很明显,所有的函数和全局变量都要用static关键字声明,将其作用域限制在本模块内部,与其他模块共享的函数或者变量要EXPORT到内核中。
3、无锁可以提高整个程序的性能,但是CPU需要对此提供支持,请以x86/ARM为例简述。
解答:无锁编程具体使用和考虑到的技术方法包括:原子操作(atomic operations), 内存栅栏(memory barriers), 内存顺序冲突(memory order), 指令序列一致性(sequential consistency)和顺ABA现象等等。
在这其中最基础最重要的是操作的原子性或说原子操作。原子操作可以理解为在执行完毕之前不会被任何其它任务或事件中断的一系列操作。原子操作是非阻塞编程最核心基本的部分,没有原子操作的话,操作会因为中断异常等各种原因引起数据状态的不一致从而影响到程序的正确。
对于原子操作的实现机制,在硬件层面上CPU处理器会默认保证基本的内存操作的原子性,CPU保证从系统内存当中读取或者写入一个字节的行为肯定是原子的,当一个处理器读取一个字节时,其他CPU处理器不能访问这个字节的内存地址。但是对于复杂的内存操作CPU处理器不能自动保证其原子性,比如跨总线宽度或者跨多个缓存行(Cache Line),跨页表的访问等。这个时候就需要用到CPU指令集中设计的原子操作指令,现在大部分CPU指令集都会支持一系列的原子操作。
而在无锁编程中经常用到的原子操作是Read-Modify-Write (RMW)这种类型的,这其中最常用的原子操作又是 COMPARE AND SWAP(CAS),几乎所有的CPU指令集都支持CAS的原子操作,比如X86平台下中的是 CMPXCHG(Compare Are Exchange)。
继续说一下CAS,CAS操作行为是比较某个内存地址处的内容是否和期望值一致,如果一致则将该地址处的数值替换为一个新值。CAS操作具体的实现原理主要是两种方式:总线锁定和缓存锁定。所谓总线锁定,就是CPU执行某条指令的时候先锁住数据总线的, 使用同一条数据总线的CPU就无法访问内存了,在指令执行完成后再释放锁住的数据总线。锁住数据总线的方式系统开销很大,限制了访问内存的效率,所以又有了基于CPU缓存一致性来保持操作原子性作的方法作为补充,简单来说就是用CPU的缓存一致性的机制来防止内存区域的数据被两个以上的处理器修改。
最后这里随便说一下CAS操作的ABA的问题,所谓的ABA的问题简要的说就是,线程a先读取了要对比的值v后,被线程b抢占了,线程b对v进行了修改后又改会v原来的值,线程1继续运行执行CAS操作的时候,无法判断出v的值被改过又改回来。
解决ABA的问题的一种方法是,一次用CAS检查双倍长度的值,前半部是指针,后半部分是一个计数器;或者对CAS的数值加上版本号。
参考文章:无锁编程技术及实现。
编程题
1、已知循环缓冲区是一个可以无限循环读写的缓冲区,当缓冲区满了还继续写的话就会覆盖我们还没读取到的数据。下面定义了一个循环缓冲区并初始化,请编写它的Write函数:
-
typedef struct RingBuf { -
char *Buf; -
unsigned int Size; -
unsigned int RdId; -
unsigned int WrId; -
}RingBuf; -
void Init(RingBuf *ringBuf, char *buf, unsigned int size) { -
memset(ringBuf, 0, sizeof(RingBuf)); -
ringBuf->Buf = buf; -
ringBuf->Size = size; -
ringBuf->RdId = 0; -
ringBuf->WrId = 0; -
}
解答:实际上我觉得提供的初始化代码部分,对WrId的初始化有点问题,Write()函数的完整代码如下:
-
typedef struct RingBuf { -
char *Buf; -
unsigned int Size; -
unsigned int RdId; -
unsigned int WrId; -
}RingBuf; -
void Init(RingBuf *ringBuf, char *buf, unsigned int size) { -
memset(ringBuf, 0, sizeof(RingBuf)); -
ringBuf->Buf = buf; -
ringBuf->Size = size; -
ringBuf->RdId = 0; -
ringBuf->WrId = strlen(buf); -
} -
void Write(RingBuf *ringBuf, char *buf, unsigned int len) { -
unsigned int pos = ringBuf->WrId; -
while (pos + len > ringBuf->Size) { -
memcpy(ringBuf->Buf + pos, buf, ringBuf->Size - pos); -
buf += ringBuf->Size - pos; -
len -= ringBuf->Size - pos; -
pos = 0; -
} -
memcpy(ringBuf->Buf + pos, buf, len); -
ringBuf->WrId = pos + len; -
} -
void Print(RingBuf *ringBuf) { -
for (int i = 0; i < ringBuf->Size; i++) { -
cout << ringBuf->Buf[i]; -
} -
cout << endl; -
} -
int main() -
{ -
RingBuf *rb = (RingBuf *)malloc(sizeof(RingBuf)); -
char init_str[] = "ABC"; -
int size = 6; -
Init(rb, init_str, size); -
char p[] = "1234567"; -
Write(rb, p, 7); -
Print(rb); -
return 0; -
}
2、已知两个已经按从小到大排列的数组,将它们中的所有数字组合成一个新的数组,要求新数组也是按照从小到大的顺序。请按照上述描述完成函数:
int merge(int *array1, int len1, int *array2, int len2, int *array3);解答:这道题本质上就是一道合并排序,网上一大堆的程序案例,就不多介绍了。下面这段程序是我自己写的,并不是从网上贴的,如果有一些BUG,还请指出。
-
int merge(int *array1, int len1, int *array2, int len2, int *array3) { -
int retn = len1 + len2; -
if ((*array1 < *array2 || len2 == 0) && len1 > 0) { -
*array3 = *array1; -
merge(++array1, --len1, array2, len2, ++array3); -
} -
if ((*array1 >= *array2 || len1 == 0) && len2 > 0) { -
*array3 = *array2; -
merge(array1, len1, ++array2, --len2, ++array3); -
} -
return retn; -
}