hadoop环境搭建和在本地用虚拟机模拟分布式集群的搭建
由于老师布置的大作业,以及对于想深入的实践下课堂学到的知识,记录下步骤,写了本篇文章。当然也走了一些弯路,希望大家能够一次成功吧。
需要的工具:
1:VMwave
2:centOS
可能会用到的东西:
1: centos的yum出现Could not retrieve mirrorlist解决方法
Centos7 安装wget报错,could not retrieve mirrorlist http://mirrorlist.centos.org/ 如图:
看一下它的提示,把链接在浏览器运行一下,看看不能访问,如果不能访问,在linux下ping一下看看是不是网络链接正常。出现这种原因就是一般网络没链接好。
修改一下dns,找到/etc/sysconfig/network-scripts/ifcfg-eno33
注意一下,ifcfg-eno33后面的数字是随机产生的。
将unboot改为yes,重新启动网络,service network restart
2:配置centos的静态ip地址
进入/etc/sysconfig/network-scripts目录,找到该接口的配置文件(ifcfg-ens33)(名字为随机生成不一定一样)。如果没有,请创建一个。
打开配置文件并编辑以下变量:
在上图中,要设置成“BOOTPROTO=none”表示该接口不通过DHCP获取ip。“ONBOOT=yes”告诉我们,系统将在启动时开启该接口。
上图的getway网关地址在虚拟网络编辑器里面查看:
保存修改并使用以下命令来重启网络服务:
- # systemctl restart network.service
现在验证接口是否配置正确:
- # ip add
三台虚拟机配置完成后可以使用ping命令来测试是否能通信。
测试成功!
3:在Windows下传文件到虚拟机
http://blog.csdn.net/guoxin91/article/details/31761505
开始搭建:
1.首先,克隆另外两台完全一模一样的虚拟机。
分别在3台虚拟机上做一下更新:#yum - y update
后面要安装软件时,如果没有更新,在安装所需软件时,可能会说找不到软件
2.修改机器名和hosts文件。
第一步:修改三台虚拟机的机器名。
方法一:暂时修改机器名:hostname
用hostname命令可以临时修改机器名,但机器重新启动之后就会恢复原来的值。
#hostname //查看机器名
#hostname -i //查看本机器名对应的ip地址
方法二:永久性修改机器名:修改系统配置文件
修改/etc/sysconfig/network //修改这个系统配置文件,才能有效改变机器名
/etc/hosts //hostname命令读这个配置文件
直接修改/etc/hosts文件,系统本身用到主机名的地方不会变化,所以
/etc/hosts 是网络中用的,/etc/sysconfig/network是本机起作用
可以使用hostname来查看。
第二步:修改三台虚拟机的/etc/hosts文件。
分别在master、slave1、slave2下修改:
#vim /etc/hosts
进入文件后原内容删除加入如下内容。
127.0.0.1 localhost
192.168.199.3 master master
192.168.199.4 slave1 slave1
192.168.199.5 slave2 slave2
第三步:免密码登录
使用secureCRT远程工具连接
node1,在node1上运行如下命令即可
ssh-keygen -t rsa
ssh-copy-id 其它虚拟机ip或者名称
至此各个机器上的SSH配置已经完成,可以测试一下了,比如master向slave1发起ssh连接
第四步:安装jdk
下载jdk版本。我是在windows下下载的,然后在 虚拟机的/usr/目录下新建java
#cd /usr/ --进入usr目录
#mkdir java --创建 java目录
#rz ---用来上传文件用的,默认在那个目录下,就上传在那个目录下 我下载的是jdk-7u79-linux-i586.rpm
#rpm -ivh jdk-7u79-linux-i586.rpm --等待安装完成
# vim /etc/profile --修改/etc/profile文件,在最后面加入
export JAVA_HOME=/usr/java/jdk1.7.0_79
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
再按wq进行保存
#source /etc/profile ---让修改后的配置生效
#cd
#java
#javac
#java -version ---进行测试是否成功
关于在Windows下传文件到虚拟机里在上面有提到。
http://blog.csdn.net/guoxin91/article/details/31761505
至此安装完成。
在另外的两台虚拟机如法炮制。
第五步:安装hadoop
第一步:将hadoop-1.2.1-bin.tar.gz文件拷贝到/home/hadoop目录下。
第二步:解压Hadoop,解压路径/opt。
[root@master ~]#tar -zxvf /home/hadoop/hadoop-1.2.1-bin.tar.gz -C /opt
第三步:配置系统变量[root@master ~]#vi /etc/profile#set hadoop path
export HADOOP_HOME=/opt/hadoop-1.2.1
export PATH=$PATH:$HADOOP_HOME/bin
[root@master ~]#source /etc/profile
第四步:更改conf目录下的conf/core-site.xml, conf/hdfs-site.xml, conf/mapred-site.xml,conf/hadoop-env.sh,conf/masters,conf/slaves 文件。[root@master ~]#vim /opt/hadoop-1.2.1/conf/hadoop-env.sh添加内容:
export JAVA_HOME=/opt/jdk1.8.0_151
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_CLASSPATH=$JAVA_HOME/lib/tools.jar
保存退出。
[root@master ~]#vi /opt/hadoop-1.2.1/conf/masters进入文件加入如下信息:192.168.199.3
[root@master ~]#vim /opt/hadoop-1.2.1/conf/slaves进入文件加入如下信息:
192.168.199.4
192.168.199.5
[root@master ~]#vim /opt/hadoop-1.2.1/conf/core-site.xml进入文件加入如下信息。
[root@master ~]#vi /opt/hadoop-1.2.1/conf/hdfs-site.xml进入文件加入如下信息。(replication默认是3,如果不修改,datanode少于三台就会报错)。
[root@master ~]#vim /opt/hadoop-1.2.1/conf/mapred-site.xml进入文件加入如下信息。
第五步:可以使用scp将hadoop-1.2.1拷贝到其它两个虚拟机上。但是这里我选择在slave1和slave2上按上述方法配置。
至此hadoop安装完成。
第六步:测试hadoop自带的Wordcount程序
参考:http://blog.csdn.net/hxh1994/article/details/40784535
1、在安装Hadoop成功后,在Hadoop的包里面就已经有了已经编译好并被打包成jar包的WordCount实例,如图1所示,打包好的jar包全名为hadoop-examples-1.2.1.jar:
下面我们在hadoop的目录下新建一个名字为input的目录,然后在input目录下新建file1和file2两个文件,将向两个文件中写入信息,整个过程如图1所示:
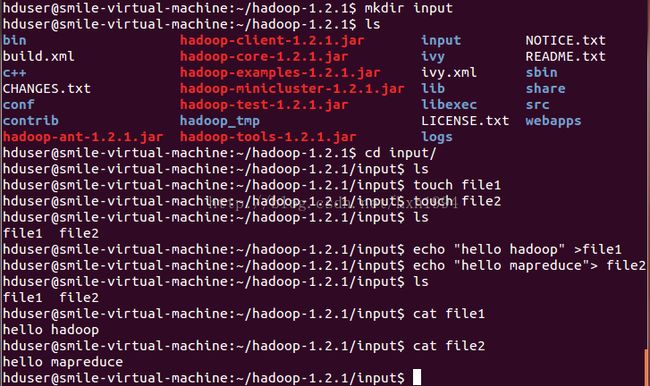
图1
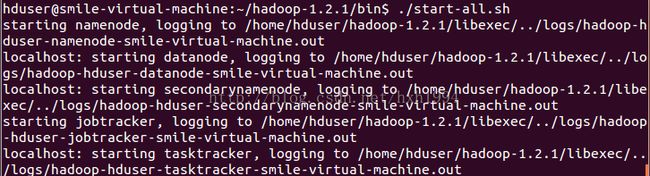
2、创建好输入文件file1和file2之后,下面我们就开启hadoop的服务了,即分别格式化hdfs文件系统并启动start-all脚本,分别如图2和图3所示
命令为 hadoop namenode –format
start-all.sh
jps查看运行的进程
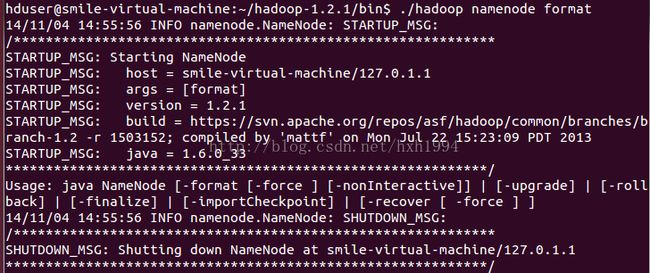
图2
2. 在HDFS上创建输入文件夹
参考:https://www.cnblogs.com/madyina/p/3708153.html
呼出终端,输入下面指令:
bin/hadoop fs -mkdir hdfsInput
执行这个命令时可能会提示类似安全的问题,如果提示了,请使用
bin/hadoop dfsadmin -safemode leave
来退出安全模式。
当分布式文件系统处于安全模式的情况下,文件系统中的内容不允许修改也不允许删除,直到安全模式结 束。安全模式主要是为了系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略必要的复制或者删除部分数据块。运行期通过命令也可以进入 安全模式。
意思是在HDFS远程创建一个输入目录,我们以后的文件需要上载到这个目录里面才能执行。
3. 上传本地file中文件到集群的hdfsInput目录下
在终端依次输入下面指令:
cd hadoop-1.2.1
bin/hadoop fs -put file/myTest*.txt hdfsInput

4. 运行例子:
在终端输入下面指令:
bin/hadoop jar hadoop-examples-1.2.1.jar wordcount hdfsInput hdfsOutput
注意,这里的示例程序是1.2.1版本的,可能每个机器有所不一致,那么请用*通配符代替版本号
bin/hadoop jar hadoop-examples-*.jar wordcount hdfsInput hdfsOutput
应该出现下面结果:
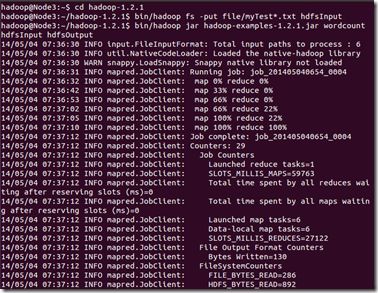
Hadoop命令会启动一个JVM来运行这个MapReduce程序,并自动获得Hadoop的配置,同时把类的路径(及其依赖关系)加入到Hadoop的库中。以上就是Hadoop Job的运行记录,从这里可以看到,这个Job被赋予了一个ID号:job_201202292213_0002,而且得知输入文件有两个(Total input paths to process : 2),同时还可以了解map的输入输出记录(record数及字节数),以及reduce输入输出记录。
查看HDFS上hdfsOutput目录内容:
在终端输入下面指令:
bin/hadoop fs -ls hdfsOutput
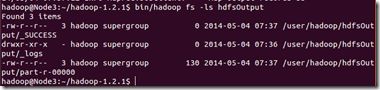
从上图中知道生成了三个文件,我们的结果在"part-r-00000"中。
使用下面指令查看结果输出文件内容
bin/hadoop fs -cat hdfsOutput/part-r-00000

(注意:请忽视截图指令中的3)
输出目录日志以及输入目录中的文件是永久存在的,如果不删除的话,如果出现结果不一致,请参考这个因素。
每次计算完都要删除之前的输入输出数据,要不然可能会报错。
删除数据:bin/hadoop fs -rm xxx