轻量级模块SENet与SKNet详解
SENet & SKNet
SENet(Squeeze-and-Excitation Networks)是2017ImageNet分类比赛冠军模型,论文发表于2018年CVPR,目前是CVPR2018引用量最多的论文。SKNet(Selective Kernel Networks)是2019CVPR的一篇文章。二者有一定共通之处,本文将这两个模型放在一起对比分析。
Paper : Sequeeze-and-excitation networks,Selective Kernel Networks
Github: Sequeeze-and-excitation networks,Selective Kernel Networks
1.引入
卷积核通常被看作是在局部感受野上,将空间(spatial)信息和特征维度(channel-wise)信息进行聚合的信息聚合体
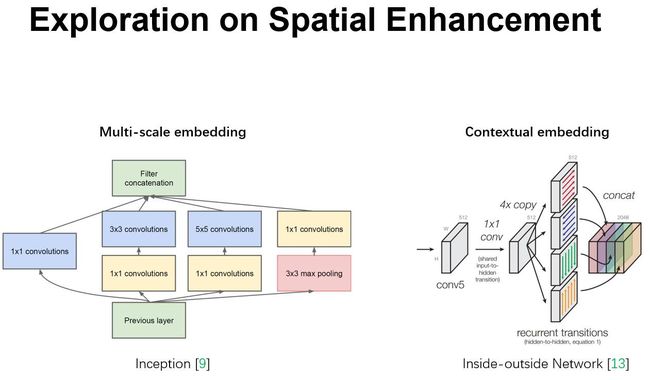
从卷积核的意义入手,目前很多卷积神经网络的相关工作都是通过改进网络的空间结构来优化模型。如Inception模块通过引入不同大小的卷积核来获得不同感受野上的信息。或inside-outside网络参考空间上下文信息,等等。
那么可不可以在网络中加入特征维度信息呢?
基于这一想法,诞生了Squeeze-and-Excitation Networks。
2.SE-Net结构
SENet的作者想通过该模块实现两个功能
(1) 显式地建立模型,定义通道间关系
(2) 实现“特征重标定”。即对于不同channel-wise,加强有用信息并压缩无用信息
接下来看一下SENet结构
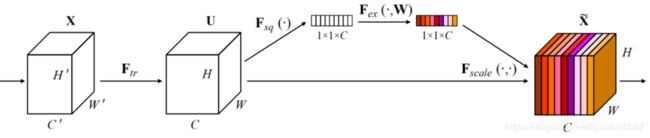
上图中X为输入向量,Ftr为一次普通卷积操作,从U到 X ~ \widetilde{X} X 的三步操作Squeeze,Excitation,Scale为SENet模块主要构成
2.1 Sequeeze:Global Information Embedding
In order to tackle the issue of exploiting channel dependencies, we first consider the signal to each channel in the output features. Each of the learned filters operates with a local receptive field and consequently each unit of the transformation output U is unable to exploit contextual information outside of this region.
为了能够建模通道间依赖关系,作者想要首先把每个通道信息用一个通道描述符来表示。即将每个通道上H × \times ×W维度的信息压缩为一个数。我们可以很容易的想到一个办法——全局平均池化。(对应结构图中 Fsq(·) 操作)
Formally, a statistic z ∈ RC is generated by shrinking U through its spatial dimensions H ×W ,such that the c -th element of z is calculated by:
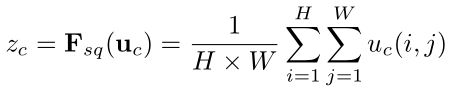
这样我们就把H × \times ×W × \times ×C的矩阵压缩到了1 × \times × 1 × \times ×C,每个通道的信息都用该通道的全局平均池化值来表示
2.2 Excitation: Adaptive Recalibration
To make use of the information aggregated in the squeeze operation, we follow it with a second operation which aims to fully capture channel-wise dependencies.
为了能够使用这些压缩过的信息对通道关系进行建模,我们进行了第二步操作Excitation。
我们希望通道间关系的建模是灵活并且非线性的,于是在此处作者使用了一个简单且有效的全连接结构。(对应结构图中Fex( · , W) 操作)
To meet these criteria, we opt to employ a simple gating mechanism with a sigmoid activation:
where δ refers to the ReLU function, W1∈ RC × \times × C r \frac{C}{r} rCand W2 ∈ RC × \times × C r \frac{C}{r} rC
这里的Excitation用的是 全连接层->Relu激活->全连接层
第一个全连接层将特征维度降低到原来的1/r,第二个全连接层将维度升回原来的大小。
这里使用两个而不是一个全连接层的原因是:
(1) 增加更多的非线性,可以更好地拟合通道间复杂的相关性
(2) 尽可能减少参数量和计算量
2.3 Scale
这里Scale就是一个简单的加权操作(对应结构图中Fscale( ·,·)操作)
在经过Excitation第二个全连接层后得到的输出是经过sigmoid激活的权重值
The final output of the block is obtained by rescaling the transformation output U with the activations:
where X ~ \widetilde{X} X = [ x ~ 1 \tilde{x}_1 x~1 , x ~ 2 \tilde{x}_2 x~2 ,…, x ~ C \tilde{x}_C x~C ] and Fscale (uc ,sc ) refers to channel-wise multiplication between the scalar sc and the feature map uc ∈ RH×W.
通过将Excitation步骤计算得到权重值乘回原来的矩阵中,得到了SE blocks最终的输出。
3.SE模块嵌入实例


如上两图是SE模块嵌入到Inception网络和ResNet网络的示例图。可以看到不需要改变原来的网络结构,直接在原来的结构中加入一个SE模块即可。需要注意的是若将SE嵌入到含有skip-connections的网络(如ResNet)中,需要在Addition前对分支上Residual进行特征重标定操作 。如果在Addition后的特征进行重标定,由于主干上存在0-1的Scale操作,在网络较深BP优化时,在靠近输入层易出现梯度消失问题,导致模型难以优化。
其他网络关于SE模块嵌入位置的讨论详见论文。
4.SENet Experiments
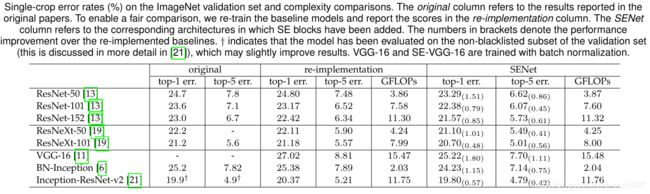
上表中第一列是对应模型作者论文中给出的实验结果,第二列是SENet作者复现结果,第三列是将原网络嵌入SE模块的结果。
可以看到提升还是很明显的,并且该模块对于不同深度和不同结构的模型都是有效的。
作者提到,以ResNet-50为例,嵌入SE模块的SE-ResNet-50其参数约提高2%-10%,理论计算复杂度提升<1%,实际训练时,使用GPU训练时间多出10%(作者分析可能是GPU对类似于SE模块的低量级全连接网络和全局平局池化计算没有针对性优化),使用CPU训练时间多出<2%(这个结果倒是较符合理论计算值)
5.Selective Kernel Networks
SKNet同样是一个轻量级嵌入式的模块,其灵感来源是,我们在看不同尺寸不同远近的物体时,视觉皮层神经元接受域大小是会根据刺激来进行调节的。那么对应于CNN网络,一般来说对于特定任务特定模型,卷积核大小是确定的,那么是否可以构建一种模型,使网络可以根据输入信息的多个尺度自适应的调节接受域大小呢?
基于这种想法,作者提出了Selective Kernel Networks(SKNet)。结构图如下
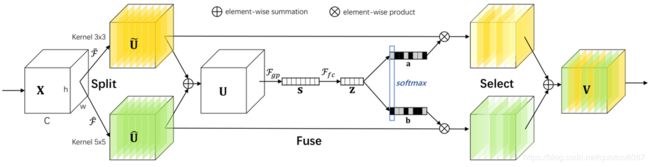
这个网络主要分为Split,Fuse,Select三个操作
Split:
Split: For any given feature map X ∈ RH’×W’×C’, by default we first conduct two transformations F ~ \widetilde{F} F : X → U ~ \widetilde{U} U ∈RH×W×C and
F ^ \widehat{F} F : X → U ^ \widehat{U} U ∈RH×W×C with kernel sizes 3 and 5, respectively. Note that both F ~ \widetilde{F} F and F ^ \widehat{F} F are composed of efficient grouped/depthwise convolutions, Batch Normalization and ReLU function in sequence.For further efficiency, the conventional convolution with a 5×5 kernel is replaced with the dilated convolution with a 3×3 kernel and dilation size 2.
这里的Split是指对输入向量X进行不同卷积核大小的完整卷积操作(包括efficient grouped/depthwise convolutions,Batch Normalization,ReLU function)。如结构图所示,对X进行Kernel3×3和Kernel5×5的卷积操作,得到输出 U ~ \widetilde{U} U 和 U ^ \widehat{U} U 。
Fuse
这部分和SE模块的处理大致相同,U= U ~ \widetilde{U} U + U ^ \widehat{U} U 。Fgp为全局平均池化操作,Ffc为先降维再升维的两层全连接层。需要注意的是输出的两个矩阵a和b,其中矩阵b为冗余矩阵,在如图两个分支的情况下b=1-a。
Select
Select操作对应于SE模块中的Scale。区别是Select使用a和b两个权重矩阵对 U ~ \widetilde{U} U 和 U ^ \widehat{U} U 进行加权操作,然后求和得到最终的输出向量V。
![]()
6.SKNet结构实例与实验结果
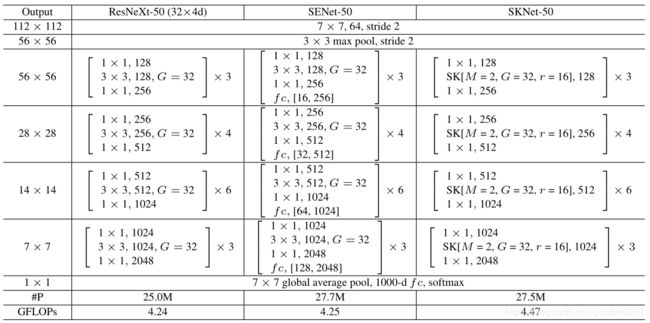
如上图所示使ResNext-50,SENet-ResNext-50,SKNet-ResNext-50三个网络的结构对比。
可以看到SENet是在(1×1卷积+3×3卷积+1×1卷积)完整卷积操作后直接加入全连接层,学习通道间依赖关系,再将学习到的通道权重加权回原向量。
而SKNet则是替代了ResNext中3*3卷积部分,用两个或多个不同卷积核大小的卷积操作 加学习通道权重全连接层替代。输出向量再继续进行1×1卷积操作。
从参数量来看,由于模块嵌入位置不同,SKNet的参数量与SENet大致持平(或略小于后者)。计算量也略有上升(当然,带来的精度提升远小于增加的计算量成本)。
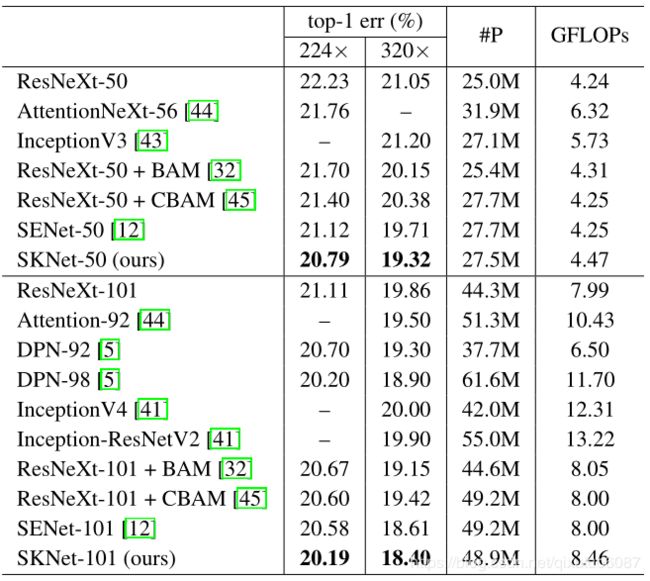
上图给出了SKNet与其他常见模型(包括SENet)的精度比较(使用ImageNet数据集)。可以看到SKNet取得了最好的结果。
在论文中作者还给出了不同卷积核等参数对精度影响实验结果。
7.总结
SENet和SKNet都是可直接嵌入网络的轻量级模块,虽然SKNet的实验结果表明其略好于SENet,但SKNet使用时涉及到了卷积核数量和大小的选择问题,其作者也只是给出了不同参数选择下的实验结果,并选择了一个最好的结果与其他模型相比较。但直观来说SKNet相当于给网络融入了soft attention机制,使网络可以获取不同感受野的信息,这或许可以成为一种泛化能力更好的网络结构。毕竟虽然Inception网络结构精妙,效果也不错,但总觉得有种人工设计特征痕迹过重的感觉。如果有网络可以自适应的调整结构,以获取不同感受野信息,那么或许可以实现CNN模型极限的下一次突破。
SE模块的更多介绍可以看这篇文章 → http://www.sohu.com/a/161633191_465975