范式理论的程序设计(五)
关于数据库范式理论的程序设计 - ClosureUtils
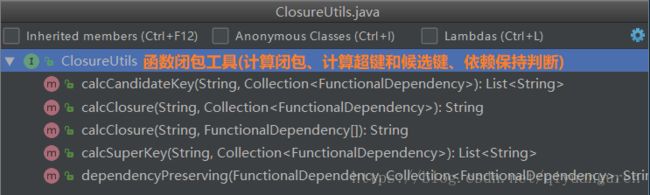
这里我使用的工具类全部都是使用接口,public interface ClosureUtils extends ArmstrongUtils是关于闭包(closure)相关的工具。包含了属性闭包的计算、超键和候选键的计算、函数依赖保存的判断定。
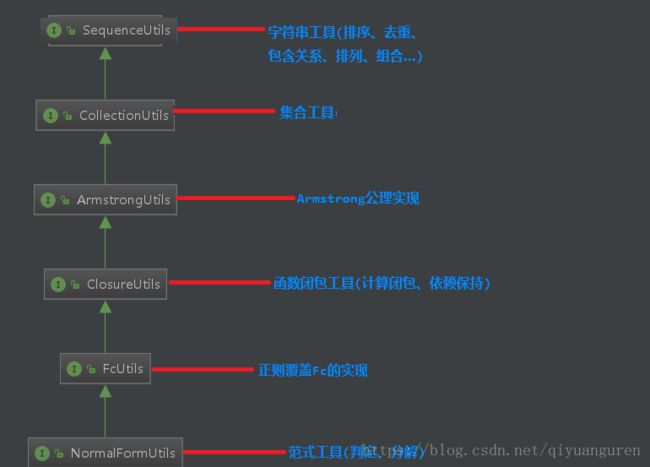
Utils工具的继承关系
ClosureUtils接口
import com.ruoxing.dbs.bean.FunctionalDependency;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Comparator;
import java.util.List;
import java.util.stream.Collectors;
/**
* @author :ruoxing
* @type :Interface
* @date :2018年5月
* @description :函数闭包工具(计算闭包、计算超键和候选键、依赖保持判断)
*/
public interface ClosureUtils extends ArmstrongUtils {
}
属性闭包的计算
1. 属性闭包
关系模式R的子集α在函数依赖集F上根据Armstrong公理推导,能逻辑蕴含的最大属性集。
2. 算法描述 《数据库系统概念》P193
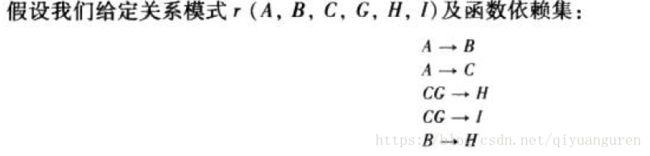

3. 算法代码
/**
* 描述:计算属性闭包(迭代)
* @param attribution 属性α
* @param fds 函数依赖集F,由于没有涉及到超键,所有这里的关系模式R默认为F中所有出现的字符
* @return α的闭包
*/
default String calcClosure(String attribution, Collection fds) {
//attribution = sort(attribution);
return calcClosure(attribution, fds.toArray(new FunctionalDependency[]{}));
}
default String calcClosure(String attribution, FunctionalDependency[] fds) {
final StringBuffer sb = new StringBuffer(attribution);
//是否添加过了
boolean[] visited = new boolean[fds.length];
boolean done = true;
while (done) {
boolean loop = false;
for (int i = 0; i < fds.length; i++) {
if (visited[i]) continue;
if (contains(sb, fds[i].getLeft())) {
sb.append(fds[i].getRight());
visited[i] = true;
loop = true;
}
}
done = loop;
}
//返回 排序后(去重后(sb.toString()))
return sort(deDuplicate(sb.toString())).toString();
} 4.测试代码(Junit)
import com.ruoxing.dbs.bean.FunctionalDependency;
import com.ruoxing.dbs.util.ClosureUtils;
import org.junit.Before;
import org.junit.Test;
import java.util.Collection;
import java.util.HashSet;
/**
* 描述:测试ClosureUtils
*/
public class Test4 implements ClosureUtils {
private final Collection F = new HashSet<>();
private String R = "ABCGHI";
@Before
public void before() {
F.add(new FunctionalDependency("A", "B"));
F.add(new FunctionalDependency("A", "C"));
F.add(new FunctionalDependency("CG", "H"));
F.add(new FunctionalDependency("CG", "I"));
F.add(new FunctionalDependency("B", "B"));
}
} @Test
public void test01() {
final Collection fds = new HashSet<>();
fds.add(new FunctionalDependency("A", "B"));
fds.add(new FunctionalDependency("A", "C"));
fds.add(new FunctionalDependency("CG", "H"));
fds.add(new FunctionalDependency("CG", "I"));
fds.add(new FunctionalDependency("B", "B"));
System.out.println("AG的属性闭包=" + calcClosure("AG", fds));//AG的属性闭包=ABCGHI
} 超键的计算
这里的算法是给定关系模式R和函数依赖集F,然后出所有的超键,后面超键和候选键的判定都不会直接使用这个方法来先算出所有超键在判定其是否在该集合中。而是依然使用属性闭包来判定是否是超键。
1. 算法代码
/**
* 描述:计算属性集R在函数依赖集F上的所有超键
* @param R 属性集R
* @param F 函数集F
* @return 所有超键的集合
*/
default List calcSuperKey(String R, Collection F) {
//对R进行去重排序
final String attributions = sort(deDuplicate(R)).toString();
//获取R的所有组合(子集)
final Collection combinations = combination(R);
//子集根据进行属性个数(少->多)排序
final List subset = combinations.stream()
.map(CharSequence::toString)
.sorted(Comparator.comparingInt(String::length))
.collect(Collectors.toList());
//用于存放超键(前面计算到的子集都是不同的,所有可以用List)
final List superKeys = new ArrayList<>();
subset.forEach(sub -> {
//如果sub的闭包包含R,则是超键
if (calcClosure(sub, F).equals(attributions)) superKeys.add(sub);
});
return superKeys;
} 2.测试代码
@Test
public void test02() {
System.out.println("关系模式R的所有超键:");
System.out.println(calcSuperKey(R,F));
//[AG, ABG, AGH, AGI, ACG, ACGI, ACGH, AGHI, ABCG, ABGH, ABGI, ABCGH, ACGHI, ABCGI, ABGHI, ABCGHI]
}候选键的计算
1. 算法代码
/**
* 描述:计算属性集R在函数依赖集F上的所有候选键
* @param R 属性集R
* @param F 函数集F
* @return 所有候选键的集合
*/
default List calcCandidateKey(String R, Collection F) {
//先获取其超键,将每个超键转换为Set superKeys = calcSuperKey(R, F);
//用于存放候选键的字符集合的集合
final List candidateKeys = new ArrayList<>();
superKeys.forEach(superKeySet -> {
//如果已经添加过更小的超键,就直接继续判断下一个超键
for (String candidateKey : candidateKeys) {
if (contains(superKeySet, candidateKey)) return;
}
//如果没有添加过更小的超键,则该超键为候选键
candidateKeys.add(superKeySet);
});
return candidateKeys;
} 2. 测试代码
@Test
public void test03() {
System.out.println("关系模式R的所有候选键:");
System.out.println(calcCandidateKey(R,F));//[AG]
}依赖保持的判定
1. 算法描述

2. 算法代码
/**
* 描述:依赖保持判定(迭代)
* @param fd 某个依赖 α → β
* @param F 函数依赖集
* @param patterns 分解后的多个模式Ri... String[]
* @return boolean
*/
default boolean dependencyPreserving(FunctionalDependency fd, Collection F, String... patterns) {
//result = α;
String result = fd.getLeft().toString();
//visited[i]用于标记是否遍历过Ri
final boolean[] visited = new boolean[patterns.length];
boolean done = true;
while (done) {
String copy = result;
boolean loop = false;
for (int i = 0; i < patterns.length; i++) {
final String Ri = patterns[i];
//计算result ∩ Ri
final CharSequence intersect = intersect(result, Ri);
//在F下计算(result ∩ Ri)+
final String closure = calcClosure(intersect.toString(), F);
//t=(result∩Ri)+ ∩ Ri
final CharSequence t = intersect(Ri, closure).toString();
//result=result ∪ t;
result = union(result, t).toString();
//去重在排序
result = sort(deDuplicate(result)).toString();
//System.out.println("遍历" + Ri + "后:" + result);
//如果result发生了变化
if (!copy.equals(result)) {
//Ri标记为遍历过了
visited[i] = true;
//继续循环迭代
loop = true;
break;
}
}
//当某一次迭代Ri,result都没有变换时,loop=false;while()循环也结束
done = loop;
}
//result是否包含β
return contains(result, fd.getRight());
} 3. 测试代码
@Test
public void test04() {
String R = "ABCDEG";
Set F = new HashSet<>();
F.add(new FunctionalDependency("BC","D"));
F.add(new FunctionalDependency("CD","AE"));
F.add(new FunctionalDependency("AG","CE"));
F.add(new FunctionalDependency("AB","GE"));
//将R分解为R1=(ACDE),R2=(BCDG)
String R1 = "ACDE";
String R2 = "BCDG";
//对于上面的分解,测试AG->CE,这个函数依赖是否被保持?
final boolean b = dependencyPreserving(new FunctionalDependency("AG", "CE"), F, R1, R2);
System.out.println(b);//false
//遍历ACDE后:result=AG
//遍历BCDG后:result=AG
}