python爬虫——爬取指定网站数据并保存到本地
由于需要每天从指定网站上获取数据,于是决定学习下pyhon爬虫,并使用脚本来自动获取数据并保存到本地。网址如下:
http://58.51.240.121:8503/Analysis_GuideRank.aspx。
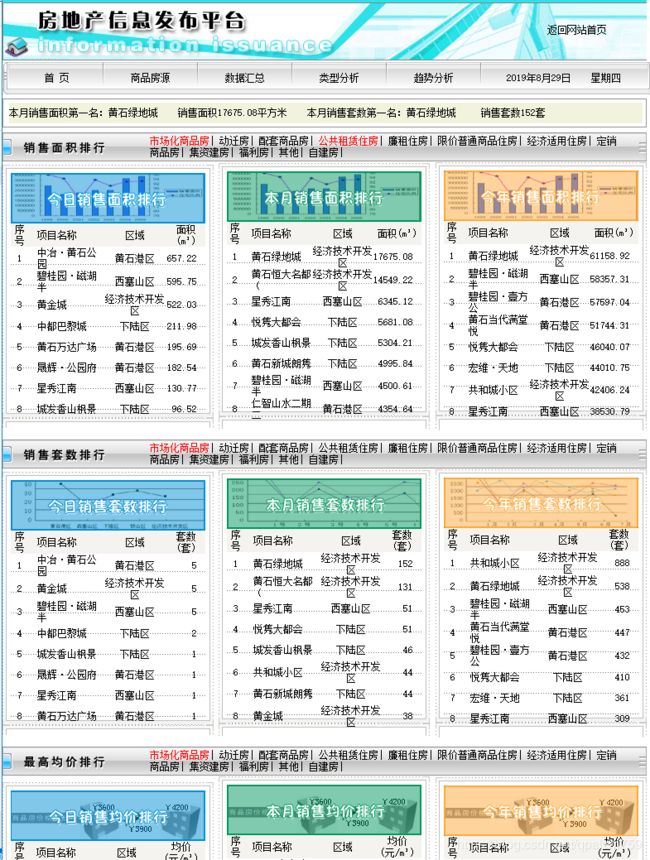
由于该站点首页布局较为简单,通过查看页面源码发现所有数据均位于表格中,因此主要思路为:
1、通过beautifulSoup来解析网页数据,并获取所有table中的值;
#coding=utf-8
from urllib import request #python3使用urllib,python2可以使用urllib2
from bs4 import BeautifulSoup
from lxml import etree
import csv
import pandas as pd
import re
#打开url,获取所有table的内容
URL = "http://58.51.240.121:8503/Analysis_GuideRank.aspx"
page = request.urlopen(URL)
soup = BeautifulSoup(page,'lxml')
table_node = soup.find_all('table')
2、利用正则表达式匹配出我们需要的table,提取该table中的数据写入列表中;
for table in table_node:
data = table.get_text(",",strip=True) #获取table中的文本内容,去除空格,用‘,’隔开
m = table_check.search(data)
table_check为正则表达式,如 table_check1 = re.compile('自建房.{3}序号.项目名称.区域.面积.{4}')。
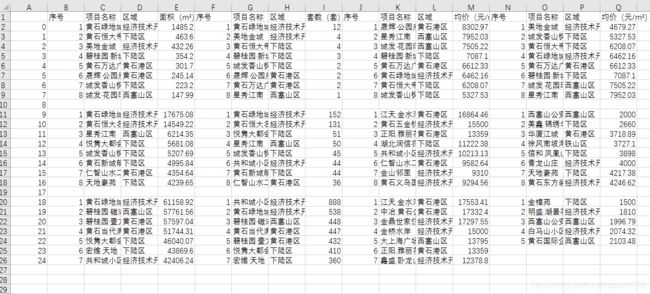
3、利用pandas对列表中的数据进行整理,并将处理好的多组数据拼接保存到本地csv文件中;
df = pd.DataFrame(data_list, columns=column)
# 横向拼接表格
result = pd.concat([df1, df2], axis=1)
result.to_csv('test.csv',mode='a', encoding='utf_8_sig')
4、用pyinstaller将脚本打包,方便使用。
进入脚本所在页面,打开cmd窗口,输入:pyinstaller -F myfile.py,将脚本打包成exe,打包成功后双击运行,最终效果如下: