yolo + yolov2 + yolov3 随笔总结(差异、相同、改进)
博客为随笔笔记类,便于加深理解以及比较各模型不同。若想要系统学习yolo系列,建议阅读论文或详解博客
PS:
!!!!yolo的bounding box和ssd的anchor box不一样!!!他不是在图中每一个坐标点生成了一系列的盒子,这个盒子我们把它叫做Anchor,也就是先验盒子!!yolo,没有先验的概念,而是将图片分成了一系列的格子!! 而这个格子直接预测到的目标的定位的框就是我们所说的bounding box,boungbox的信息直接用途中的格子表示 如:
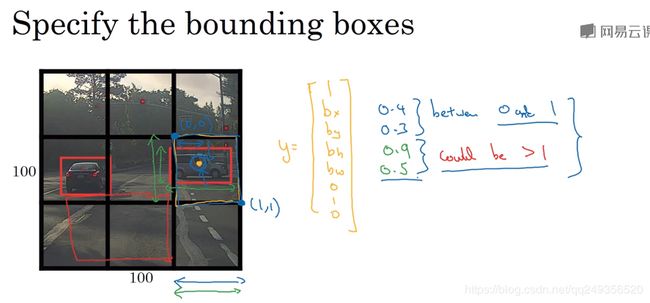
他没有anchor 也没有default
正文:
yolo核心思想:利用整张图作为网络的输入,直接在输出层回归bounding box的位置和其所属类别。yolo利用全图作为context信息,背景错误比较少。
yolo将一幅图分成s×s个格子(grid cell),如果某个object的中心落在这个格子,那么这个网格就负责这个object。
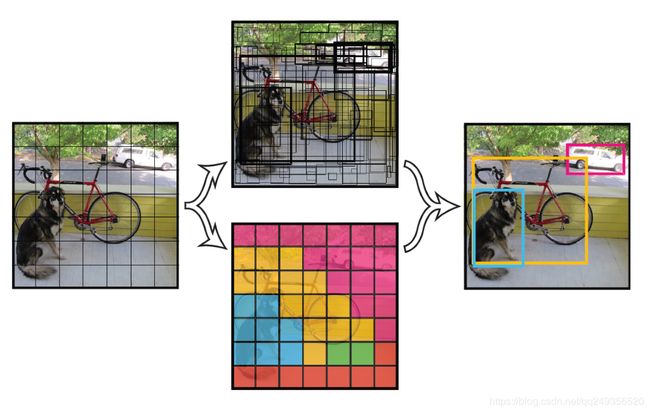
每个网格负责预测b个bounding box。每一个boundbox包含了x y h w自身的位置信息以及一个confidence。这个con代表了所预测的box中含有object的置信度以及这个box预测的有多准两种信息。计算如下:
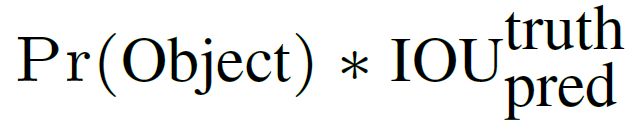
其中,如果有object落在一个grid cell里,第一项取1,否则取0。第二项则是bounding box和 gt box之间的IOU
每个bounding box要预测5个值,而每个网格还要预测一个类别信息。记为C类。则S×S个网格每个网格要预测B个boundbox还要预测C个catagories。输出就是:S x S x (5*B+C)的一个tensor。
此处注意:class信息是针对每个网格的,confidence信息是针对bounding box的(这也是之后要改进的地方)
网络如下:

损失函数共包含5个部分:

在这个损失中: 只有当某个网格中右object时才对class error进行惩罚
只有当某个box prediction对某个gt box负责时,才会对corrd error进行惩罚。而是否负责则根据IOU值推算。
yolo v2:
V2借鉴了faster的思想,引入了anchor,就像之前说的yolo需要改进的地方,bounding box对一个格子多个目标的预测能力很差。并且删除了yolo的全连接层,使用anchor预测bounging box
模型如下:
网络使用了darknet19 具体如下:

其网络设计对于v1没有太大改变,主要是:
在每个卷积层后引入BN层,代替dropout,加速收敛。
移除全连接层。
在16层开始分为两条路径,将底层特征连接到高层,提高模型性能。
使用Anchor:
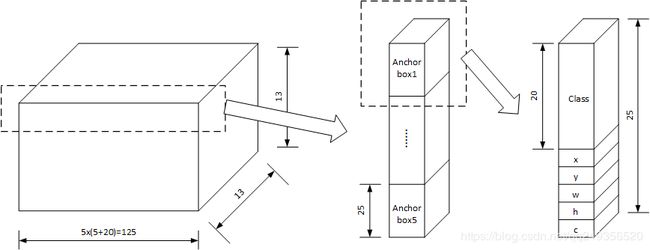
每个anchor包括25个信息,是否有目标,目标位置,目标种类。
计算如下:
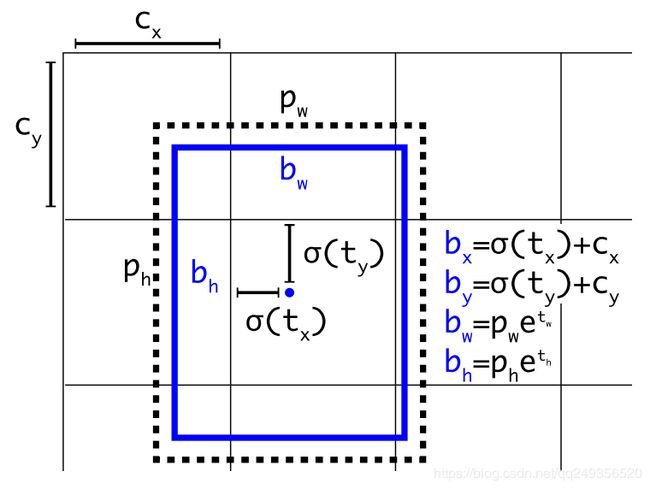
。其中每个cell包括5个anchor,这5个anchor具有不同尺寸的预设,该预设可以通过手动指定。也可通过在训练集上获得。在v2中,预设尺寸是通过在测试集上进行类聚获得的。
yolo v3:
yolov3 对于检测两个距离很近的物体,又或者是距离很近的不同类物体鲁棒性很好,全面超越SSD512。
v1 v2都不如SSD300
总的来说 v3比v2性能提高很大,但速度却没有下降,况且对于小目标鲁棒性很强。
yolo v3对于yolo以及v2的改变:
loss不同:作者v3替换了v2的softmax loss 变成logistic loss,而且每个ground truth只匹配一个先验框。
网络结构改变: 由darknet19变为darknet53,跳层现象越来越普遍,使用残差结构。
激活不同:激活函数由softmax改为sigmoid
anchor不同:anchor的数量由5个变为3个,提高了IOU
detection的策略不同:v2只有一个detection,v3一下变成了3个,分别是一个下采样的,feature map为13*13,还有2个上采样的eltwise sum,feature map为26*26,52*52,也就是说v3的416版本已经用到了52的feature map,而v2把多尺度考虑到训练的data采样上,最后也只是用到了13的feature map,这应该是对小目标影响最大的地方。
backbone不同:这和上一点是有关系的,v2的darknet-19变成了v3的darknet-53,为啥呢?就是需要上采样啊,卷积层的数量自然就多了,另外作者还是用了一连串的3*3、1*1卷积,3*3的卷积增加channel,而1*1的卷积在于压缩3*3卷积后的特征表示,这波操作很具有实用性,一增一减,效果棒棒。
结构如下:
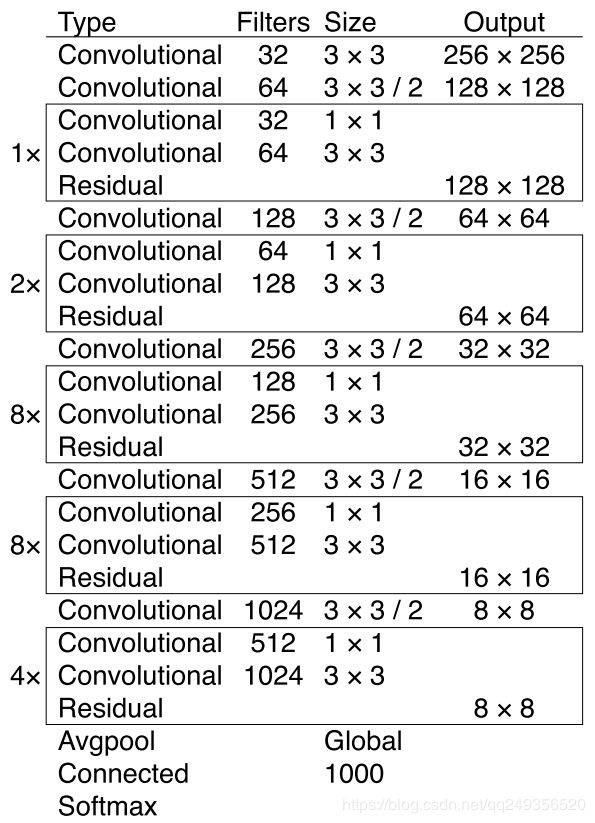

网络可能没有使用pool 直接使用conv stride=2进行下采样