使用python为爬虫获取免费代理ip
免费代理ip的爬取
爬虫一直是python使用的一个重要部分,而许多网站也为此做了许多反爬措施,其中爬虫访问过于频繁直接封ip地址也作为一种“伤敌一千,自损八百”的方法被许多网站采用,代理ip便可以防止这种情况出现。
搜索免费代理提供网站
提供免费代理的网站直接百度还是有很多的,这里我就选取了西刺免费代理,选取了透明代理进行爬取。
分析界面
打开网址,可以看见ip很规则的排列,可以说是对爬虫很友好了,Chrome打开F12分析这些代理的显示方式,可以知道是使用列表直接显示,还是比较简单的,单击下一页可以看见url里的最后多了个/2,页面的变换也可以很清楚的知道了。
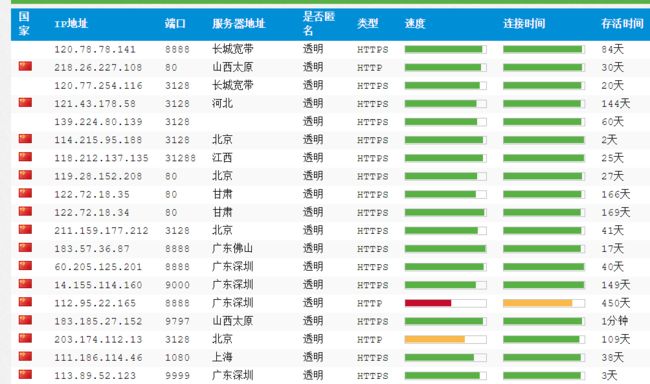
在html源码中的分布,

进行爬取和测试有效性
分析完毕开始爬取ip,直接使用第三方的requests和BeautifulSoup4,可以让抓取变得很方便,代码如下:
from iptools import header, dict2proxy
from bs4 import BeautifulSoup as Soup
def parse_items(items):
# 存放ip信息字典的列表
ips = []
for item in items:
tds = item.find_all('td')
# 从对应位置获取ip,端口,类型
ip, port, _type = tds[1].text, int(tds[2].text), tds[5].text
ips.append({'ip': ip, 'port': port, 'type': _type})
return ips
def check_ip(ip):
try:
proxy = dict2proxy(ip)
url = 'https://www.ipip.net/'
r = requests.get(url, headers=head, proxies=pro,timeout=5)
r.raise_for_status()
except:
return False
else:
return True
def get_proxies(index):
url = 'http://www.xicidaili.com/nt/%d' % index
r = requests.get(url, headers=header)
r.encoding = r.apparent_encoding
r.raise_for_status()
soup = Soup(r.text, 'lxml')
# 第一个是显示最上方的信息的,需要丢掉
items = soup.find_all('tr')[1:]
ips = parse_items(items)
good_proxies = []
for ip in ips:
if check(ip):
good_proxies.append(ip)
return good_proxies就像在上面写的,有效性我直接使用了ip查询网站,获得的ip基本确保可以直接使用。
写入json文件
可以将获取的ip存放在json文件中,json模块的使用也很简单,直接打开一个文件,使用dump方法写入文件即可,
import json
def write_to_json(ips):
with open('proxies.json', 'w', encoding='utf-8') as f:
json.dump(ips, f, indent=4)写入后的文件内容如下:

写入MongoDB
写入数据库后获取和操作会很方便,
from pymongo import MongoClient as Client
def write_to_mongo(ips):
client = Client(host='localhost', port=27017)
db = client['proxies_db']
coll = db['proxies']
for ip in ips:
if coll.find({'ip': ip['ip']}).count() == 0:
coll.insert_one(ip)
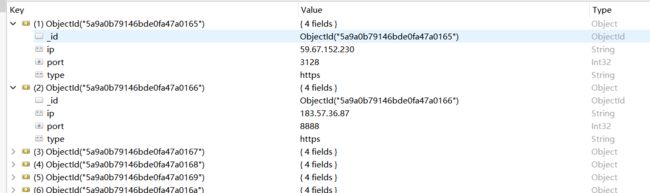
client.close()写入后使用RoboMongo查看
使用多线程
导入threading包,将Thread封装一下,得到最终的代码,
get_proxies.py
import json
import requests
import time
from proxies_get.iptools import header, dict2proxy
from bs4 import BeautifulSoup as Soup
from pymongo import MongoClient as Client
import threading
def parse_items(items):
# 存放ip信息字典的列表
ips = []
for item in items:
tds = item.find_all('td')
# 从对应位置获取ip,端口,类型
ip, port, _type = tds[1].text, int(tds[2].text), tds[5].text.lower()
ips.append({'ip': ip, 'port': port, 'type': _type})
return ips
def check_ip(ip, good_proxies):
try:
pro = dict2proxy(ip)
# print(pro)
url = 'https://www.ipip.net/'
r = requests.get(url, headers=header, proxies=pro, timeout=5)
r.raise_for_status()
print(r.status_code, ip['ip'])
except Exception as e:
# print(e)
pass
else:
good_proxies.append(ip)
def write_to_json(ips):
with open('proxies.json', 'w', encoding='utf-8') as f:
json.dump(ips, f, indent=4)
def write_to_mongo(ips):
'''将数据写入mongoDB'''
client = Client(host='localhost', port=27017)
db = client['proxies_db']
coll = db['proxies']
# 先检测,再写入,防止重复
for ip in ips:
if coll.find({'ip': ip['ip']}).count() == 0:
coll.insert_one(ip)
client.close()
class GetThread(threading.Thread):
'''对Thread进行封装'''
def __init__(self, args):
threading.Thread.__init__(self, args=args)
self.good_proxies = []
def run(self):
url = 'http://www.xicidaili.com/nt/%d' % self._args[0]
# 发起网络访问
r = requests.get(url, headers=header)
r.encoding = r.apparent_encoding
r.raise_for_status()
soup = Soup(r.text, 'lxml')
# 第一个是显示最上方的信息的,需要丢掉
items = soup.find_all('tr')[1:]
ips = parse_items(items)
threads = []
for ip in ips:
# 开启多线程
t = threading.Thread(target=check_ip, args=[ip, self.good_proxies])
t.start()
time.sleep(0.1)
threads.append(t)
[t.join() for t in threads]
def get_result(self):
return self.good_proxies
if __name__ == '__main__':
# 主函数使用多线程
threads = []
for i in range(1, 30):
t = GetThread(args=[i])
t.start()
time.sleep(10)
threads.append(t)
[t.join() for t in threads]
for t in threads:
proxies = t.get_result()
write_to_mongo(proxies)
iptools.py
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/64.0.3282.186 Safari/537.36'}
def dict2proxy(dic):
s = dic['type'] + '://' + dic['ip'] + ':' + str(dic['port'])
return {'http': s, 'https': s}
总结
这个免费代理ip的爬虫没什么太难的地方,就是服务器有点弱,一不小心就503了,需要限制一下访问速度。