MySQL之CTE(公用表表达式)
一、MySQL之CTE(公用表表达式)
(一)概念
1、MySQL的CTE是在MySQL8.0版本开始支持的,公用表表达式是一个命名的临时结果集,仅在单个SQL语句(例如select、insert、delete和update)的执行范围内存在。CTE分为递归CTE和非递归CTE。
(二)意义
1、MySQL8.0之前,进行复杂查询时需要使用子查询来实现,SQL语句不仅语句复杂性能低,而且不够清晰。CTE的出现简化了复杂查询语句的编写,提高了SQL性能。
2、与子查询或者派生查询相比,CTE可以重用上次的查询结果即查询一次即可,同时,CTE可以相互引用。例如:
WITH d1 AS (SELECT ... FROM ...), d2 AS (SELECT ... FROM d1 ... )
SELECT FROM d1, d2 ...(三)语法如下:
with cte_name1 [(column_list)] as (
查询语句
),
cte_name2 as(
查询语句
)
select * from cte_name;注意:查询中的列数必须与column_list中的列数相同。 如果省略column_list,将使用cte中查询语句中使用的列。
注意:多个cte查询语句之间用逗号分隔。
(四)cte实例:
WITH customers_in_usa AS (
SELECT
customerName, state
FROM
customers
WHERE
country = 'USA'
) SELECT
customerName
FROM
customers_in_usa
WHERE
state = 'CA'
ORDER BY customerName;(五)递归CTE
1、递归CTE概念:递归的方式是CTE的子查询可以引用其本身,使用递归方式时,WITH子句中要使用WITH RECURSIVE代替。递归CTE子句中必须包含两个部分,一个是种子查询(不可引用自身),另一个是递归查询,这两个子查询可以通过 UNION、UNION ALL或UNION DISTINCT 连接在一起。
注意:种子SELECT只会执行一次,并得到初始的数据子集,而递归SELECT是会重复执行直到没有新的行产生为止,最终将所有的结果集都查询出来,这对于深层查询(如具有父子关系的查询)是非常有用的。
2、递归实例:查询公司的组织架构数据,查询管理层级。
(1)创建表:
CREATE TABLE emp(
id INT PRIMARY KEY NOT NULL,
name VARCHAR(100) NOT NULL,
manager_id INT NULL,
INDEX (manager_id),
FOREIGN KEY (manager_id) REFERENCES employees_mgr
(id)
);(2)插入数据:
INSERT INTO emp VALUES
(333, "总经理", NULL),
(198, "副总1", 333),
(692, "副总2", 333),
(29, "主任1", 198),
(4610, "职员1", 29),
(72, "职员2", 29),
(123, "主任2", 692);
(3)递归查询:
WITH RECURSIVE test(id, name, path)
AS
(
SELECT id, name, CAST(id AS CHAR(200))
FROM emp WHERE manager_id IS NULL
UNION ALL
SELECT e.id, e.name, CONCAT(ep.path, ',', e.id)
FROM test AS ep JOIN emp AS e ON ep.id = e.manager_id
)SELECT * FROM test ORDER BY path;
(4)结果如下:
+------+---------+-----------------+
| id | name | path |
+------+---------+-----------------+
| 333 | 总经理| 333 |
| 198 | 副总1| 333,198 |
| 29 | 主任1| 333,198,29 |
| 4610 | 职员1| 333,198,29,4610 |
| 72 | 职员2| 333,198,29,72 |
| 692 | 副总2| 333,692 |
| 123 | 主任2| 333,692,123 |
+------+---------+-----------------+
二、子查询
(一)子查询概念
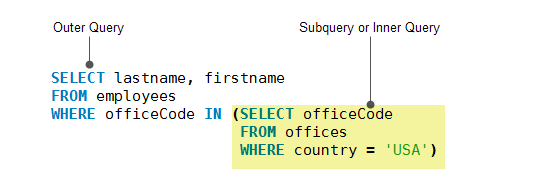
1、子查询是嵌套在另一个查询(如select、insert、update和delete)中的查询。子查询又称为内部查询,而包含子查询的查询称为外部查询。 子查询可以在使用表达式的任何地方使用,并且必须在括号中关闭。
2、如图所示:
三、派生表
(一)派生表概念
1、派生表是从select语句返回的虚拟表。派生表类似于临时表,但是在SELECT语句中使用派生表比临时表简单得多,因为派生表没有创建临时表的步骤。派生表会在使用过后即时清除的,所以我们在简化复杂查询的时候可以考虑使用。
注意:派生表和子查询通常可以互换使用,但是与子查询不同的是,派生表必须具有别名。
(二)派生表语法
SELECT column_list FROM
( SELECT column_list FROM table_1) derived_table_name --派生表
WHERE derived_table_name.c1 > 0;注意:派生表之间不可以相互引用。例如:SELECT ... FROM (SELECT ... FROM ...) AS d1, (SELECT ... FROM d1 ...) AS d2,第一个查询标记为d1,在第二个查询语句中使用d1是不允许的。
四、临时表
(一)临时表概念
1、临时表是一种特殊类型的表,它允许您存储一个临时结果集,可以在单个会话中多次重用。
(二)创建临时表语法
1、使用CREATE TEMPORARY TABLE语句创建临时表。请注意,在CREATE和TABLE关键字之间添加TEMPORARY关键字。
2、当会话结束或连接终止时,MySQL会自动删除临时表。当您不再使用临时表时,也可以使用DROP TABLE语句来显式删除临时表。
3、一个临时表只能由创建它的客户机访问。不同的客户端可以创建具有相同名称的临时表,而不会导致错误,因为只有创建临时表的客户端才能看到它。 但是,在同一个会话中,两个临时表不能共享相同的名称。
4、临时表可以与数据库中的普通表具有相同的名称。 不推荐使用相同名称。例如,如果在示例数据库(yiibaidb)中创建一个名为employees的临时表,则现有的employees表将变得无法访问。 对employees表发出的每个查询现在都是指employees临时表。 当删除您临时表时,永久employees表可以再次访问。
(三)临时表实例
1、创建一个临时表:
CREATE TEMPORARY TABLE table_name (
name VARCHAR(10) NOT NULL,
value INTEGER NOT NULL
);2、删除临时表:
drop temporary table table_name;