端到端的文本检测识别
选自ICCV 2017 澳大利亚阿德莱德大学沈春华老师组的作品Towards End-to-end Text Spotting with Convolutional Recurrent Neural Networks 。是目前为止第一篇提出端到端OCR文字检测+识别的文章。
文章主要3点贡献:
(1)提出端到端的OCR检测+识别的框架
(2)改进的ROI pooling。相比于fasterRCNN中ROI pooling 只能产生固定长宽的feature map,本文改进的ROI pooling可以产生固定长度,不同宽度的feature map,更适用于文字这样一个有着不同长度的对象,然后经过LSTM产生固定长度的feature。
(3)基于本文复杂的网络结构,提出了课程学习策略,一种由易到难的学习策略。先使用简单的在彩色背景上写字的合成图片进行训练,然后使用中等难度的在风景图片上写字的合成图片进行训练,最后使用真实的样本图片进行训练。

网络整体结构:

从网络结构可以看出和faster RCNN的结构很像。主要由TPN,RFE,TDN,TRN几个部分组成。
其中,基础CNN网络结构和faster RCNN一样,都是修改的VGG16结构。
TPN结构类似faster RCNN中的RPN,用途一样。
RFE模块类似faster RCNN中的ROI pooling 。
TDN模块用于文本框的回归和文本框的分数。
TRN模块用于文本内容的识别。
TPN(Text Proposal Network )模块

TPN模块包含24个anchor,其中4个scale(with box areas of 16*16, 32*32, 64*64, 80*80) ,6个aspect ratio(1 : 1, 2 : 1,3 : 1, 5 : 1, 7 : 1, 10 : 1) 。然后,这里采用了2种滤波器进行卷积,分别为5*3*256,3*1*256。这样的好处可以分别学到细节和上下文特征。
RFE(Region Feature Encoder )模块
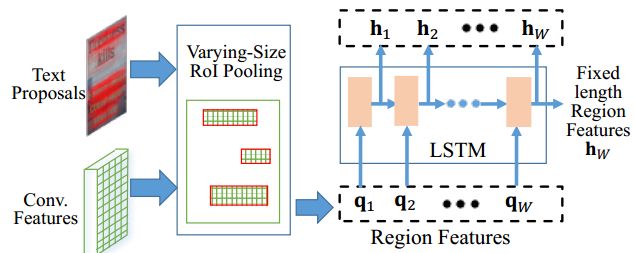
该模块和类似于faster RCNN中ROI pooling,区别在于,这里的ROI pooling中,输出的是固定高度,不定长度的feature map,大小为H×min(Wmax; 2Hw/h) ,然后经过LSTM变化为固定长度的特征输出。最终输出1024维的特征。
TDN(Text Detection Network)模块
TDN输出2048维的特征,然后分别接入边框的回归和分类的分数预测。
TRN(Text Recognition Network )模块

该模块是一个基于attention机制的seq2seq模型。最终模型输出38维向量(26个字母,10个数字,1个标点符号的代表,一个结束标志EOS)

其中,V = [v1; : : : ; vW ] 为特征经过LSTM编码后的输出特征。Hi’为解码层的输出值,Wv,Wh为需要学习的嵌入矩阵,α为attention矩阵的权值,ci 为输入特征的加权求和。
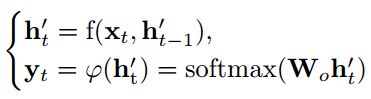
在每个时间步t = 0; 1; : : : ; T + 1 ,依据上面公式进行解码。其中,f()函数为RNN的函数,Wo 为将特征映射到输出空间的映射矩阵。
损失函数
整个框架的分类为binary_crossentrop,回归为smooth L1

在TPN模块中,正anchor阈值为0.7,负anchor阈值为0.3,N为一个batch中随机选择的anchor个数,为256,N+为正anchor的个数,为128。

LDR模块中,N^为TPN中输出的ROI的个数,为128,N^+为正的ROI个数,小于等于64。其中,正anchor的阈值为0.6,负anchor的阈值为0.4
References:
https://cs.adelaide.edu.au/~chhshen/index.html