CMS GC日志详解
GC 日志参数
JVM的GC日志的主要参数包括如下几个:
-XX:+PrintGC 输出GC日志
-XX:+PrintGCDetails 输出GC的详细日志
-XX:+PrintGCTimeStamps 输出GC的时间戳(以基准时间的形式)
-XX:+PrintGCDateStamps 输出GC的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800)
-XX:+PrintHeapAtGC 在进行GC的前后打印出堆的信息
-Xloggc:../logs/gc.log 日志文件的输出路径
垃圾收集器组合
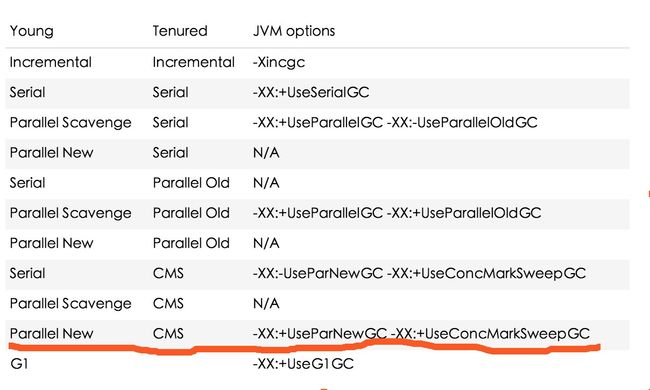
下面列举典型的垃圾收集器组合 ParNew + CMS,讲解 GC 日志的含义。
下面先简单介绍这2个垃圾收集器:
ParNew : 年轻代垃圾收集器,多线程,采用标记—复制算法。
CMS:老年代的收集器,全称(Concurrent Mark and Sweep),是一种以获取最短回收停顿时间为目标的收集器。
日志详解
1. ParNew GC 日志
2017-05-01T14:20:34.306+0800: 44.642: [GC2017-05-01T14:20:34.306+0800: 44.642: [ParNew: 327680K->40960K(368640K), 0.0883899 secs] 327680K->60854K(1007616K), 0.0886153 secs] [Times: user=0.56 sys=0.05, real=0.10 secs]
| 日志内容 | 含义解释 |
|---|---|
| 2017-05-01T14:20:34.306+0800 | GC发生的时间 |
| 44.642 | GC开始,相对JVM启动的相对时间,单位是秒 |
| GC | 区别MinorGC和FullGC的标识,这次代表的是MinorGC |
| ParNew | 收集器的名称 |
| 327680K->40960K | 收集前后年轻代的使用情况 |
| (368640K) | 整个年轻代的容量 |
| 0.0883899 secs | 该区域 gc 所花的时间 |
| 327680K->60854K | 收集前后整个堆的使用情况 |
| (1007616K) | 整个堆的容量 |
| 0.0886153 secs | GC 总时间 |
| [Times: user=0.56 sys=0.05, real=0.10 secs] | GC事件在不同维度的耗时 |
CMS 日志
以下是一段完整的 CMS GC 日志记录,下面会对每一个环节进行拆解并做详细说明:
2017-05-18T20:32:21.029+0800: 442.193: [GC [1 CMS-initial-mark: 349375K(638976K)] 393510K(1007616K), 0.0424478 secs] [Times: user=0.03 sys=0.00, real=0.03 secs]
2017-05-18T20:32:21.060+0800: 442.236: [CMS-concurrent-mark-start]
2017-05-18T20:32:21.279+0800: 442.452: [CMS-concurrent-mark: 0.216/0.216 secs] [Times: user=1.00 sys=0.13, real=0.22 secs]
2017-05-18T20:32:21.279+0800: 442.453: [CMS-concurrent-preclean-start]
2017-05-18T20:32:21.294+0800: 442.456: [CMS-concurrent-preclean: 0.004/0.004 secs] [Times: user=0.03 sys=0.00, real=0.01 secs]
2017-05-18T20:32:21.294+0800: 442.456: [CMS-concurrent-abortable-preclean-start]
CMS: abort preclean due to time 2017-05-18T20:32:26.429+0800: 447.591: [CMS-concurrent-abortable-preclean: 4.238/5.134 secs] [Times: user=5.38 sys=0.78, real=5.13 secs]
2017-05-18T20:32:26.429+0800: 447.591: [GC[YG occupancy: 77380 K (368640 K)]2017-05-18T20:32:26.429+0800: 447.591: [Rescan (parallel) , 0.0219897 secs]2017-05-18T20:32:26.452+0800: 447.613: [weak refs processing, 0.0002341 secs]2017-05-18T20:32:26.452+0800: 447.614: [class unloading, 0.0172195 secs]2017-05-18T20:32:26.469+0800: 447.631: [scrub symbol table, 0.0180261 secs]2017-05-18T20:32:26.487+0800: 447.649: [scrub string table, 0.0025024 secs] [1 CMS-remark: 349375K(638976K)] 426755K(1007616K), 0.0718764 secs] [Times: user=0.19 sys=0.00, real=0.07 secs]
2017-05-18T20:32:26.501+0800: 447.663: [CMS-concurrent-sweep-start]
2017-05-18T20:32:26.757+0800: 447.919: [CMS-concurrent-sweep: 0.256/0.256 secs] [Times: user=0.25 sys=0.00, real=0.26 secs]
2017-05-18T20:32:26.757+0800: 447.919: [CMS-concurrent-reset-start]
2017-05-18T20:32:26.760+0800: 447.922: [CMS-concurrent-reset: 0.003/0.003 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2017-05-18T20:32:21.029+0800: 442.193: [GC [1 CMS-initial-mark: 349375K(638976K)] 393510K(1007616K), 0.0424478 secs] [Times: user=0.03 sys=0.00, real=0.03 secs]
这阶段是CMS初始化标记的阶段,从垃圾回收的“根对象”开始,且只扫描直接与“根对象”直接关联的对象,并做标记,在此期间,其他线程都会停止。这时候的老年代容量为 638976K, 在使用到 349375K 时开始初始化标记。耗时短。
2017-05-18T20:32:21.060+0800: 442.236: [CMS-concurrent-mark-start]
并发标记阶段,与用户线程并发执行,过程耗时很长。目的:从GC Root 开始对堆中对象进行可达性分析,找出存活的对象。2017-05-18T20:32:21.279+0800: 442.452: [CMS-concurrent-mark: 0.216/0.216 secs] [Times: user=1.00 sys=0.13, real=0.22 secs]
并发标记阶段花费了0.216s cpu 时间 和0.216s 系统时间(包括其他线程占用cpu导致标记线程挂起的时间)2017-05-18T20:32:21.279+0800: 442.453: [CMS-concurrent-preclean-start]
并发预清理阶段,也是与用户线程并发执行。虚拟机查找在执行并发标记阶段新进入老年代的对象(可能会有一些对象从新生代晋升到老年代, 或者有一些对象被分配到老年代)。通过重新扫描,减少下一个阶段”重新标记”的工作,因为下一个阶段会Stop The World。2017-05-18T20:32:21.294+0800: 442.456: [CMS-concurrent-preclean: 0.004/0.004 secs] [Times: user=0.03 sys=0.00, real=0.01 secs]
该阶段花费了花费了 0.004s cpu 时间 和 0.004s 系统时间2017-05-18T20:32:21.294+0800: 442.456: [CMS-concurrent-abortable-preclean-start]
CMS: abort preclean due to time 2017-05-18T20:32:26.429+0800: 447.591: [CMS-concurrent-abortable-preclean: 4.238/5.134 secs] [Times: user=5.38 sys=0.78, real=5.13 secs]
并发可中止预清理阶段,运行在并行预清理和重新标记之间,直到获得所期望的eden空间占用率。增加这个阶段是为了避免在重新标记阶段后紧跟着发生一次垃圾清除。为了尽可能区分开垃圾清除和重新标记 ,我们尽量安排在两次垃圾清除之间运行重新标记阶段。2017-05-18T20:32:26.429+0800: 447.591: [GC[YG occupancy: 77380 K (368640 K)]2017-05-18T20:32:26.429+0800: 447.591: [Rescan (parallel) , 0.0219897 secs]2017-05-18T20:32:26.452+0800: 447.613: [weak refs processing, 0.0002341 secs]2017-05-18T20:32:26.452+0800: 447.614: [class unloading, 0.0172195 secs]2017-05-18T20:32:26.469+0800: 447.631: [scrub symbol table, 0.0180261 secs]2017-05-18T20:32:26.487+0800: 447.649: [scrub string table, 0.0025024 secs] [1 CMS-remark: 349375K(638976K)] 426755K(1007616K), 0.0718764 secs] [Times: user=0.19 sys=0.00, real=0.07 secs]
重新标记阶段,会暂停所有用户线程。该阶段的任务是完成标记整个年老代的所有的存活对象。
详解:
(1) 2016-08-23T11:23:08.447-0200: 65.550 – 时间
(2) CMS Final Remark – 收集阶段,这个阶段会标记老年代全部的存活对象,包括那些在并发标记阶段更改的或者新创建的引用对象
(3) YG occupancy: 77380 K (368640 K) – 年轻代当前占用情况和容量
(4) [Rescan (parallel) , 0.0219897 secs] – 重新标记所花的时间
(5) weak refs processing, 0.0002341 secs] –处理弱引用所花的时间
(6) class unloading, 0.0172195 secs] – 卸载无用的class所花的时间
(7) scrub string table, 0.0180261 secs – 暂时不清楚什么意思,网上找到一段英文解释(that is cleaning up symbol and string tables which hold class-level metadata and internalized string respectively)
(8) 349375K(638976K) – 在这个阶段之后老年代占有的内存大小和老年代的容量
(9) 426755K(1007616K) – 在这个阶段之后整个堆的内存大小和整个堆的容量
(10) 0.0718764 secs – 这个阶段的持续时间2017-05-18T20:32:26.501+0800: 447.663: [CMS-concurrent-sweep-start]
并发清理阶段开始,与用户线程并发执行。2017-05-18T20:32:26.757+0800: 447.919: [CMS-concurrent-sweep: 0.256/0.256 secs] [Times: user=0.25 sys=0.00, real=0.26 secs]
并发清理阶段结束,所用的时间。2017-05-18T20:32:26.757+0800: 447.919: [CMS-concurrent-reset-start]
2017-05-18T20:32:26.760+0800: 447.922: [CMS-concurrent-reset: 0.003/0.003 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
开始并发重置。在这个阶段,与CMS相关数据结构被重新初始化,这样下一个周期可以正常进行。以上过程是一个正常的CMS GC循环周期,接下来再分析一些不正常的日志。日志在笔者本地未能复现,下面内容转自互联网。
197.976: [GC 197.976: [ParNew: 260872K->260872K(261952K), 0.0000688 secs]197.976: [CMS197.981: [CMS-concurrent-sweep: 0.516/0.531 secs]
(concurrent mode failure): 402978K->248977K(786432K), 2.3728734 secs] 663850K->248977K(1048384K), 2.3733725 secs]- 1
- 2
这显示,ParNew收集请求执行,但是没有成功。因为此时系统估计没有老生代中没有足够的空间去容纳这些对象(预测之后可能会出现老生代的空余空间将会被系统占光),我们称这种情况为 “full promotion guarantee failure”
在这种情况下下,并发式的CMS被阻塞了,full GC执行了,GC算法进入了concurrent mode failure状态,调用一个serail Old GC(阻塞了其他线程)来清理系统的Heap
日志显示,Full GC花费了2.3733725s,老生代空间由402978K降到了248977K
concurrent mode failure可以通过增大老生代的空间或者通过设置CMSInitiatingOccupancyFraction一个小的值使得CMS Collection发生的更频繁(CMSInitiatingOccupancyFraction可以控制CMS执行的时间,假设设置为70,说明老生代在利用率为70%时发生CMS),但是把这个值设置小也会导致CMS发生更加频繁。
某些情况下,promotion failures也会发生,即使是老生代有足够的空间。这个原因是”fragmentation”-老生代的可用空间不是连续的,而将新生代的对象移动到老生代需要连续的可用空间。而CMS是不会对内存进行压缩的算法,因此造成了这种问题。
解释为什么会产生 concurrent mode failure 的原因:
CMS并发处理阶段用户线程还在运行中,伴随着程序运行会有新的垃圾产生,CMS无法处理掉它们(没有标记),只能在下一次GC的时候处理。同样的,用户线程运行就需要分配新的内存空间,为此,CMS收集器并不会在老年代全部被填满以后在进行收集,会预留一部分空间提供并发收集时的程序运行使用。即使是这样,还是会存在CMS运行期间预留的内存无法满足程序需求,就会出现”Concurrent Mode Failure”失败,这是,虚拟机将会启动备案操作:临时启动Serial Old 收集器来重新进行老年代的垃圾收集,Serial Old收集器会Stop the world,这样会导致停顿时间过长