gensim之word2vec源码阅读
word2vec经过多年的实战,在nlp各种任务中表现不俗,但是只经过读论文,阅读一些博客,word2vec的很多细节还是了解得不够深入。在面试,工作中也是浅尝辄止。不利于自己抓住问题的本质。仅以本篇博客记录阅读word2vec源码的过程。
源码来源
gensim
正宗源码,谷歌开源:https://code.google.com/p/word2vec/
使用方法
from gensim.models import Word2Vec
sentences = [["cat", "say", "meow"], ["dog", "say", "woof"]]
model = Word2Vec(sentences, min_count=1)
say_vector = model['say'] # get vector for word
上面这段代码创建一个word2vec类,传入的两个参数分别为Sentence, min_count。
第一个是需要训练的语句,另一个参数是过滤低频词是单词的频率。
主要参数:`
sentences : 句子的单词列表
sg : 训练模式,1表示用skip-gram, 0 表示用CBOW
size : 词向量维度
window : 窗口大小
alpha : 初始学习率大小
min_alpha : 学习率,线性衰减的下届
seed : 随机种子
min_count : 低频次阈值,即训练语料中小于等于这个频率的词将过滤掉
max_vocab_size : 设置词表大小,大于词表大小的单词量,根据频率丢弃掉。约 1000W单词 占 1GB内存
设置NOne不适用词表大小功能。
sample : 高频词下采样的阈值。useful range is (0, 1e-5).
workers : 线程数
hs : 层次softmax, 1表示使用,0表示不适用。
If 1, hierarchical softmax will be used for model training.
If set to 0, and `negative` is non-zero, negative sampling will be used.
**negative** : int
If > 0, negative sampling will be used, the int for negative specifies how many "noise words"
should be drawn (usually between 5-20).
If set to 0, no negative sampling is used.
**cbow_mean** : int {1,0}
If 0, use the sum of the context word vectors. If 1, use the mean, only applies when cbow is used.
**hashfxn** : function
Hash function to use to randomly initialize weights, for increased training reproducibility.
**iter** : int
Number of iterations (epochs) over the corpus.
**trim_rule** : function
Vocabulary trimming rule, specifies whether certain words should remain in the vocabulary,
be trimmed away, or handled using the default (discard if word count < min_count).
Can be None (min_count will be used, look to :func:`~gensim.utils.keep_vocab_item`),
or a callable that accepts parameters (word, count, min_count) and returns either
**attr:**`gensim.utils.RULE_DISCARD`, :attr:`gensim.utils.RULE_KEEP` o:attr:`gensim.utils.RULE_DEFAULT`.
Note: The rule, if given, is only used to prune vocabulary during build_vocab() and is not stored as part
of the model.
**sorted_vocab** : int {1,0}
If 1, sort the vocabulary by descending frequency before assigning word indexes.
**batch_words :** int
Target size (in words) for batches of examples passed to worker threads (and
thus cython routines).(Larger batches will be passed if individual
texts are longer than 10000 words, but the standard cython code truncates to that maximum.)
**compute_loss**: bool
If True, computes and stores loss value which can be retrieved using `model.get_latest_training_loss()`.
**callbacks** : :obj: `list` of :obj: `~gensim.models.callbacks.CallbackAny2Vec`
List of callbacks that need to be executed/run at specific stages during training.`
主要参数有 训练模式、word2vec size、windows size、是否
上面是word2vec类的构造函数(init)的说明,word2vec类继承自BaseWordEmbeddingModel类,BaseWordEmbeddingModel这个类又继承自baseAny2vecModel。继承关系如下:
BaseWordEmbeddingMode的初始化函数代码为:
def __init__(self, sentences=None, workers=3, vector_size=100, epochs=5, callbacks=(), batch_words=10000,
trim_rule=None, sg=0, alpha=0.025, window=5, seed=1, hs=0, negative=5, cbow_mean=1,
min_alpha=0.0001, compute_loss=False, fast_version=0, **kwargs):
self.sg = int(sg)
if vector_size % 4 != 0:
logger.warning("consider setting layer size to a multiple of 4 for greater performance")
self.alpha = float(alpha)
self.window = int(window)
self.random = random.RandomState(seed)
self.min_alpha = float(min_alpha)
self.hs = int(hs)
self.negative = int(negative)
self.cbow_mean = int(cbow_mean)
self.compute_loss = bool(compute_loss)
self.running_training_loss = 0
self.min_alpha_yet_reached = float(alpha)
self.corpus_count = 0
print('start training !')
super(BaseWordEmbeddingsModel, self).__init__(
workers=workers, vector_size=vector_size, epochs=epochs, callbacks=callbacks, batch_words=batch_words)
if fast_version < 0:
print('low version used!')
warnings.warn(
"C extension not loaded, training will be slow. "
"Install a C compiler and reinstall gensim for fast training."
)
self.neg_labels = []
if self.negative > 0:
# precompute negative labels optimization for pure-python training
self.neg_labels = zeros(self.negative + 1)
self.neg_labels[0] = 1.
if sentences is not None:
if isinstance(sentences, GeneratorType):
raise TypeError("You can't pass a generator as the sentences argument. Try an iterator.")
self.build_vocab(sentences, trim_rule=trim_rule)
self.train(
sentences, total_examples=self.corpus_count, epochs=self.epochs, start_alpha=self.alpha,
end_alpha=self.min_alpha, compute_loss=compute_loss)
else:
if trim_rule is not None:
logger.warning(
"The rule, if given, is only used to prune vocabulary during build_vocab() "
"and is not stored as part of the model. Model initialized without sentences. "
"trim_rule provided, if any, will be ignored.")
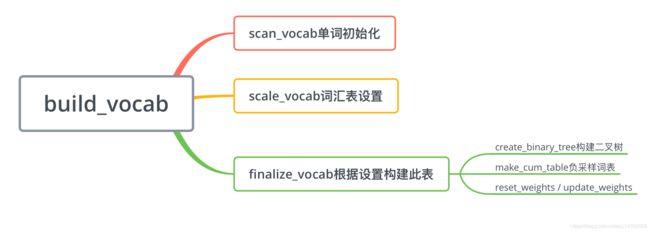
关键代码有两个,分别是构建单词表和模型训练
单词表的构建
self.train(
sentences, total_examples=self.corpus_count, epochs=self.epochs, start_alpha=self.alpha,
end_alpha=self.min_alpha, compute_loss=compute_loss)
点进去这个函数在BaseWordEmbeddingModel定义的代码为:
def train(self, sentences, total_examples=None, total_words=None,
epochs=None, start_alpha=None, end_alpha=None, word_count=0,
queue_factor=2, report_delay=1.0, compute_loss=False, callbacks=()):
self.alpha = start_alpha or self.alpha
self.min_alpha = end_alpha or self.min_alpha
self.compute_loss = compute_loss
self.running_training_loss = 0.0
return super(BaseWordEmbeddingsModel, self).train(
sentences, total_examples=total_examples, total_words=total_words,
epochs=epochs, start_alpha=start_alpha, end_alpha=end_alpha, word_count=word_count,
queue_factor=queue_factor, report_delay=report_delay, compute_loss=compute_loss, callbacks=callbacks)
好家伙,一层层调用,又调用到了aseWordEmbeddingsModel类中的train方法,我们点击去发现,代码如下:
def train(self, data_iterable, epochs=None, total_examples=None,
total_words=None, queue_factor=2, report_delay=1.0, callbacks=(), **kwargs):
"""Handle multi-worker training."""
self._set_train_params(**kwargs)
if callbacks:
self.callbacks = callbacks
self.epochs = epochs
self._check_training_sanity(
epochs=epochs,
total_examples=total_examples,
total_words=total_words, **kwargs)
for callback in self.callbacks:
callback.on_train_begin(self)
trained_word_count = 0
raw_word_count = 0
start = default_timer() - 0.00001
job_tally = 0
for cur_epoch in range(self.epochs):
for callback in self.callbacks:
callback.on_epoch_begin(self)
trained_word_count_epoch, raw_word_count_epoch, job_tally_epoch = self._train_epoch(
data_iterable, cur_epoch=cur_epoch, total_examples=total_examples, total_words=total_words,
queue_factor=queue_factor, report_delay=report_delay)
trained_word_count += trained_word_count_epoch
raw_word_count += raw_word_count_epoch
job_tally += job_tally_epoch
for callback in self.callbacks:
callback.on_epoch_end(self)
# Log overall time
total_elapsed = default_timer() - start
self._log_train_end(raw_word_count, trained_word_count, total_elapsed, job_tally)
self.train_count += 1 # number of times train() has been called
self._clear_post_train()
for callback in self.callbacks:
callback.on_train_end(self)
return trained_word_count, raw_word_count
在BaseWordEmbeddingModel的初始化过程中,调用了train。
真正干活的函数
for cur_epoch in range(self.epochs):
for callback in self.callbacks:
callback.on_epoch_begin(self)
trained_word_count_epoch, raw_word_count_epoch, job_tally_epoch = self._train_epoch(
data_iterable, cur_epoch=cur_epoch, total_examples=total_examples, total_words=total_words,
queue_factor=queue_factor, report_delay=report_delay)
trained_word_count += trained_word_count_epoch
raw_word_count += raw_word_count_epoch
job_tally += job_tally_epoch
for callback in self.callbacks:
callback.on_epoch_end(self)
前面准备了一大堆,好了,开始真正干活了,self._train_epoch开始执行了训练,我们一起看看这个函数到底是何方神圣吧。它的代码如下:
def _train_epoch(self, data_iterable, cur_epoch=0, total_examples=None,
total_words=None, queue_factor=2, report_delay=1.0):
"""Train one epoch."""
print('cur epoch = ', cur_epoch)
job_queue = Queue(maxsize=queue_factor * self.workers)
progress_queue = Queue(maxsize=(queue_factor + 1) * self.workers)
workers = [
threading.Thread(
target=self._worker_loop,
args=(job_queue, progress_queue,))
for _ in xrange(self.workers)
]
workers.append(threading.Thread(
target=self._job_producer,
args=(data_iterable, job_queue),
kwargs={'cur_epoch': cur_epoch, 'total_examples': total_examples, 'total_words': total_words}))
for thread in workers:
thread.daemon = True # make interrupting the process with ctrl+c easier
thread.start()
trained_word_count, raw_word_count, job_tally = self._log_epoch_progress(
progress_queue, job_queue, cur_epoch=cur_epoch, total_examples=total_examples, total_words=total_words,
report_delay=report_delay)
return trained_word_count, raw_word_count, job_tally
上面的代码看起来还是没有真正的干活,上面是一个包工头在分配任务,每个工人要干的活在
workers = [
threading.Thread(
target=self._worker_loop,
args=(job_queue, progress_queue,))
for _ in xrange(self.workers)
]
中分配。
def _worker_loop(self, job_queue, progress_queue):
"""Train the model, lifting lists of data from the job_queue."""
thread_private_mem = self._get_thread_working_mem()
jobs_processed = 0
while True:
job = job_queue.get()
if job is None:
progress_queue.put(None)
break # no more jobs => quit this worker
data_iterable, job_parameters = job
for callback in self.callbacks:
callback.on_batch_begin(self)
tally, raw_tally = self._do_train_job(data_iterable, job_parameters, thread_private_mem)
for callback in self.callbacks:
callback.on_batch_end(self)
progress_queue.put((len(data_iterable), tally, raw_tally)) # report back progress
jobs_processed += 1
logger.debug("worker exiting, processed %i jobs", jobs_processed)
self._do_train_job(data_iterable, job_parameters, thread_private_mem)是主要的训练,
主要的训练过程如下:
def _do_train_job(self, sentences, alpha, inits):
"""
Train a single batch of sentences. Return 2-tuple `(effective word count after
ignoring unknown words and sentence length trimming, total word count)`.
"""
work, neu1 = inits
tally = 0
if self.sg:
tally += train_batch_sg(self, sentences, alpha, work, self.compute_loss)
else:
tally += train_batch_cbow(self, sentences, alpha, work, neu1, self.compute_loss)
return tally, self._raw_word_count(sentences)`
train_batch_sg 函数的具体细节
def train_batch_sg(model, sentences, alpha, work=None, compute_loss=False):
"""
Update skip-gram model by training on a sequence of sentences.
Each sentence is a list of string tokens, which are looked up in the model's
vocab dictionary. Called internally from `Word2Vec.train()`.
This is the non-optimized, Python version. If you have cython installed, gensim
will use the optimized version from word2vec_inner instead.
"""
result = 0
for sentence in sentences:
word_vocabs = [model.wv.vocab[w] for w in sentence if w in model.wv.vocab and
model.wv.vocab[w].sample_int > model.random.rand() * 2 ** 32]
for pos, word in enumerate(word_vocabs):
reduced_window = model.random.randint(model.window) # `b` in the original word2vec code
# now go over all words from the (reduced) window, predicting each one in turn
start = max(0, pos - model.window + reduced_window)
for pos2, word2 in enumerate(word_vocabs[start:(pos + model.window + 1 - reduced_window)], start):
# don't train on the `word` itself
if pos2 != pos:
train_sg_pair(
model, model.wv.index2word[word.index], word2.index, alpha, compute_loss=compute_loss
)
result += len(word_vocabs)
return result
传入sentneces然后查词表lookup转化为id格式,调用train_sg_pair进行训练
不看源码不知道,一看吓一跳,光看paper真的对一个概念的掌握不是很深,如果这个概念比较经典,值得深究的话,还是要动手实现一下或者看一下源码。
这一块进行了一个操作:
对窗口进行了随机的截断。这操作相当于正则化吧。防止过拟合。这个跟dropout的操作类似,相当于bagging吧。
哈夫曼树构造过程
https://blog.csdn.net/qq_16761099/article/details/90292954
word2vec的原理与推导
http://www.hankcs.com/nlp/word2vec.html