NLP面试题目汇总11-15
11.如何对中文分词问题用隐马尔可夫模型进行建模和训练?
场景描述
介绍隐马尔可夫模型之前,首先了解马尔科夫过程。马尔科夫过程是满足无后效性的随机过程。**当前状态仅与前一状态相关。**时间和状态都是离散的马尔科夫过程也叫马尔科夫链
隐马尔可夫模型是对含有未知参数(隐状态)的马尔科夫链进行建模的过程
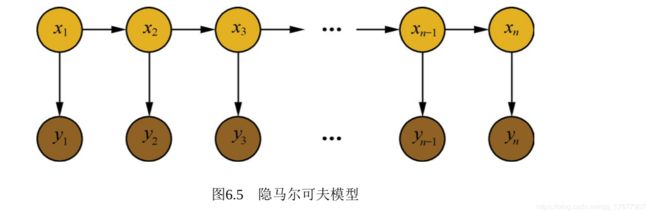


隐马尔可夫模型通常用来做序列标注问题,因此可以将分词问题转化为序列标注问题

11.5 最大熵隐马尔可夫模型为什么会产生标注偏置问题,如何解决?



标注偏置问题
它是一种判别式的概率无向图模型,既然是判别式,那就是对条件概率分布建模。

12.常见的概率图模型中,哪些是生成式模型,哪些是判别式模型?
首先需要弄清楚生成式模型与判别式模型的区别。
假设可观测的变量集合为X,需要预测的变量集合为Y,其他的变量集合为Z。生成式模式是对联合概率分布 P ( X , Y , Z ) P(X,Y,Z) P(X,Y,Z)进行建模,在给定观测集合X的条件下,通过计算边缘分布来求得对变量集合Y的推断。
P ( Y ∣ X ) = P ( X , Y ) P ( X ) = ∑ Z P ( X , Y , Z ) ∑ Y , Z P ( X , Y , Z ) P(Y|X)=\frac{P(X,Y)}{P(X)}= \frac{\sum_Z P(X,Y,Z)}{\sum_{Y,Z} P(X,Y,Z)} P(Y∣X)=P(X)P(X,Y)=∑Y,ZP(X,Y,Z)∑ZP(X,Y,Z)
判别式模型是直接对条件概率分布 P ( Y , Z ∣ X ) P(Y,Z|X) P(Y,Z∣X)进行建模,然后消掉无关变量Z就可以得到对变量集合Y的预测,即
P ( Y ∣ X ) = ∑ Z P ( Y , Z ∣ X ) P(Y|X)=\sum_ZP(Y,Z|X) P(Y∣X)=∑ZP(Y,Z∣X)
常见的概率图模型由朴素贝叶斯、最大熵模型、贝叶斯网络、隐马尔可夫模型、条件随机场、pLSA、LDA等。其中朴素贝叶斯、贝叶斯网络、pLSA、LDA属于生成式。最大熵模型属于判别式。隐马尔可夫模型、条件随机场是对序列数据进行建模的方法,其中隐马尔可夫属于生成式,条件随机场属于判别式。
13.使用过PyTorch或TensorFlow吗?简要写一个RNN算法。
用过PyTorch.但是不是很多。·
PyTorch入门
所有的框架都是基于计算图的。计算图分为静态和动态的。静态是先先定义后执行,动态图是运行过程中被定义的。
Tensor
Tensor是PyTorch中重要数据结构,可以认为是一个高维数组,可以是一个数(标量),一维数组(向量),二维数组(矩阵)或更高维数组。与numpy的区别是可以GPU加速。
import torch as t
x=t.Tensor(5,3) #构建5*3矩阵
y=t.rand(5,3) #随机初始化
Autograd
深度学习的本质是通过反向传播求导数。PyTorch的Autograd模块实现了自动求导功能,在Tensor上的所有操作,都能自动提供微分。
autograd.Variable是Autograd核心类,简单封装了Tensor。支持几乎所有Tensor的操作。Tensor在被封装成VAriable之后,可以调用它的.backward方法实现反向传播。
Variable主要包含3个属性:
- data:保存Variable所包含的Tensor
- grad:保存data对应的梯度
- grad_fn:纸箱一个function对象,用来计算梯度
from torch.autograd import Variable
x = Variable(t.ones(2,2),requires_grad = True) #使用Tensor新建一个Variable
y = x.sum()
y.backward() #反向传播计算梯度
x.grad() #查看梯度值
神经网络
torch.nn是专门为神经网络设计的模块化接口。nn构建与Autograd之上,可以用来定义和运行神经网络。nn.Module是nn中最重要的类,可以看做是一个网络的封装,包含各层网络的定义及forward方法。
下面以LeNet为例,看看如何用nn.Module实现。
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(1,6,5)
self.conv2 = nn.Conv2d(6,16,5)
self.fc1 = nn.Linear(16*5*5,120)
self.fc2 = nn.Linear(120,84)
self.fc3 = nn.Linear(84,10)
def forword(self,x):
x = F.max_pool2d(F.relu(self.conv1(x)),(2,2))
x = F.max_pool2d(F.relu(self.conv2(x)),2)
x = x.view(x.size()[0],-1)
x = x.relu(self.fc1(x))
x = x.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
只要在nn.Module子类中定义了forward函数,backward函数就会被自动实现(利用Autograd).在forward函数中可以使用任何Variable支持的函数。forward函数的输入和输出都是Variable,只有Variable才具有自动求导功能。输入时需要将Tensor封装为Variable。
损失函数及优化器
nn实现了神经网络中大部分的损失函数。例如:
nn.MSELoss用来计算均方误差
nn.CrossEntropyLoss用来计算交叉熵误差
output = net(input)
target = Variable(t.arange(0,10))
criterion = nn.MSELoss()
loss = criterion(output,target)
在反向传播计算完所有参数的梯度后,还需要使用优化方法更新网络的权重和参数。
torch.optim中实现了大部分深度学习中的优化方法
import torch.optim as optim
optimizer = optim.SGD(net.parameters(),lr = 0.01) #新建一个优化器 指定参数和学习率
optimizer.zero_grad() #先梯度清0
output = net(input)
loss = criterion(output,target) #计算损失
loss.backward() #反向传播
optimizer.step() #更新参数
循环神经网络
PyTorch中实现了最常用的RNN、LSTM、GRU。此外还有3种对应的RNNCell。RNN和RNNCell的区别在于RNN可以处理整个序列,RNNCell一次只能处理序列上的一个时间点的数据。RNN更完备更易于使用,RNNCell更灵活。
input = V(t.randn(2,3,4)) # 输入序列长度为2 batch_size为2 每个元素占4维
lstm = nn.LSTM(4,3,1) # lstm输入向量4维 3个隐含单元 1层
h0 = V(t.randn(1,3,3))
c0 = V(t.randn(1,3,3)) # 记忆单元
out, hn = lstm(input,(h0.c0))
词向量在NLP中应用广泛,PyTorch同样提供了Embedding层
embedding = nn.Embedding(4,5) # 有四个词 每个词用5维的向量表示
embedding.weight,data = t.arange(0,20).view(4,5) # 可以用预训练好的词向量初始化embedding
14.写过爬虫吗?
15.了解基于医学语义匹配的实体链接算法吗?
参考知乎回答
实体链接任务分为命名实体识别、实体链接两个阶段
对于其中的实体链接阶段进行介绍:
实体链接一般分为候选实体生成和候选实体消歧两个阶段。候选实体生成是指为了待链接的实体指称初步筛选出一批待选命名实体。候选实体生成的方法一般有:词典映射法和检索排序法。候选实体生成以后,我们需要在候选实体中选出真正的目标实体,我们称这个过程为实体消歧。常用的实体消歧方法以下分别介绍。
- 基于检索的方法
该方法将指称实体及其附近的关键词作为查询项,在知识库中进行查询,选取得分最高的候选实体作为目标实体;能够有效利用上下文信息
- 基于空间向量模型的方法
根据上下文分别构建指称实体和候选实体的特征向量,然后计算它们的余弦相似度,选取相似度最高的候选实体作为目标实体。但空间向量为词袋模型,不能反映词语之间的语义关系
- 基于排序模型的方法
该方法主要利用Learn to Rank(LTR)排序模型,根据查询与文档的文本相似度(余弦相似度)、欧氏距离、编辑距离、主题相似度、实体流行度等等特征进行训练和预测,选取排序最高的作为目标实体。它的优势就是可以有效地融入不同的特征。
- 基于主题模型的方法
根据指称实体与候选实体的主题分布相似度进行目标实体的确认。该方法的主要优势是能在一定程度上反映实体的语义相关性,避免维度灾难,在上下文信息比较丰富的情况下,能够取得很好的效果。
- 基于深度语义表示的方法
利用维基百科中实体链接关系与邻接关系等训练实体语义表示;然后结合上下文,使用类似于PageRank的方法对各个候选实体进行打分,选取得分最高的作为目标实体。
参考中科院软件所的slide
自然语言表达的多样性:
- 同一个意义可以以不同方式表达(多样性)
- 同一个表达在不同上下文中有不同的意义(歧义性)
实体链接:**将自然语言中的文本与知识库中的条目进行链接。**给定一篇文本中的实体指称(mention),确定这
些指称在给定知识库中的目标实体
关键技术:
引用表构建:引用表存储一个名字所有可能指向的实体
通常会加一些启发式规则过滤
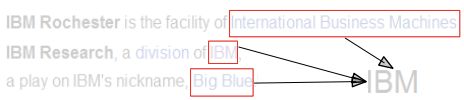
实体知识构建
- 实体知名度(表示一个实体被人们了解的程度,知名度越高越有可能提起)
- 实体的名字分布(一个实体的名字通常 定的 以 定的 个实体的名字通常是固定的,且以一定的
概率出现)
IBM和国际商用机器公司 国际商用机器公司都可以作为IBM公司的名字,但是BMI,Oracle不会作为它的
名字
- 实体上下文(特定实体的上下文规律性
上下文中出现iPad、视网膜屏的更有可能是苹果公司 出现好吃、甜的更可能是水果苹果
- 实体语义关联度(捕捉实体和实体之间的语义关系)
相关实体更有可能出现在一篇文章中
如何衡量两个实体之间的相似度? 1.在知识网络中的距离 2.在文章中共现的次数
- 文章主题(一篇文章的实体应该与其主题相关)
苹果公司更容易出现在IT相关主题文档中
水果苹果更容易出现在吃或农业相关文档中
链接推理算法
链接推理算法就是综合实体知识进行决策的过程。
局部推理
考虑单个实体的上下文,丌考虑文章中其它实体对该实体的影响
比如:
中关村的苹果不错 -> 水果苹果 or 苹果电脑?
可以利用上面提到的实体知识进行推理。
- 水果苹果和苹果电脑的上下文
- 相关度(中关村,水果苹果) = 0.1
- 相关度(中关村,苹果电脑) = 0.7
将提及m和候选实体e分别表示为特征向量
选择最大化sim(m, c, e)的实体作为目标链接对象
基于实体-提及模型融合实体知识
实体e是提及m目标实体的概率

模型选择能最大化条件概率 P ( e ∣ m ) P(e|m) P(e∣m)的实体e作为其提及m的目标实体

基于深度学习的统一表示学习
将实体、上下文、提及等文本信息利用NN映射到连续低维空间中,使用NN来同时考虑多方面信息之间的组合、转换和交互。

全局推理
单篇文本中的实体相互关联,全局推理算法进一步考虑不同实体链接决策之间的相互关联,从而提升性能。
图方法

- 使用知识库中的知识来构建mention-entity graph
- 构建算法来计算最大似然链接结构
- 同时考虑mention-entity的一致性和entity-entity之间的语义关联
- 保证每一个mention指向且只指向一个目标实体
- 计算最大似然链接结构的算法
- 寻找具有最大似然值的子图/最稠密子图
- 基于Graph Ranking寻找最大可能节点
统计方法
构建一个遵循如下原则的文档生成过程
- 主题一致性假设: 一篇文章中的所有实体都围绕他的主题.
- 上下文一致性假设: 一个实体的上下文词都与该实体一致
实体主题模型 - 将文档建模为一个文档-主题实体-词的结构