Calcite 原理解析
Apache Calcite 是独立于存储与执行的SQL解析、优化引擎,广泛应用于各种离线、搜索、实时查询引擎,如Drill、Hive、Kylin、Solr、flink、Samza等。本文结合hive中基于代价的优化,解析calcite优化引擎的实现原理。
Calcite架构
Calcite架构图如下,其中Operator Expressions 是查询树在calcite中的表示,可以直接通过calcite的SQL Parser解析得到,也可以通过Expressions Builder由Data Processing System中的查询树(本文对应hive中的AST)转换得到。Query Optimizer 根据Pluggable Rules对Operator Expressions进行优化,其中会用到Metadata Providers提供的信息进行代价计算等操作。

Hive CBO
本文中Data Processing System就是hive,本文主要解析hive如何利用calcite进行基于代价的优化(cost based optimization /CBO)。Hive CBO的主要实现代码在CalcitePlanner 这个类中, CalcitePlanner 继承自SemanticAnalyzer,重写了genOPTree 方法,由AST 生成 Operator Tree 。其中CalcitePlanner.CalcitePlannerAction.genLogicalPlan 函数对应上图中的Expressions Builder,把hive中的AST转换成calcite 中的Operator Expressions,也就是节点为RelNode的查询树。这个过程这里不展开,继续往下看。在CalcitePlanner.CalcitePlannerAction.HepPlan会对输入的basePlan根据rules进行优化,返回优化过的plan,代码如下:
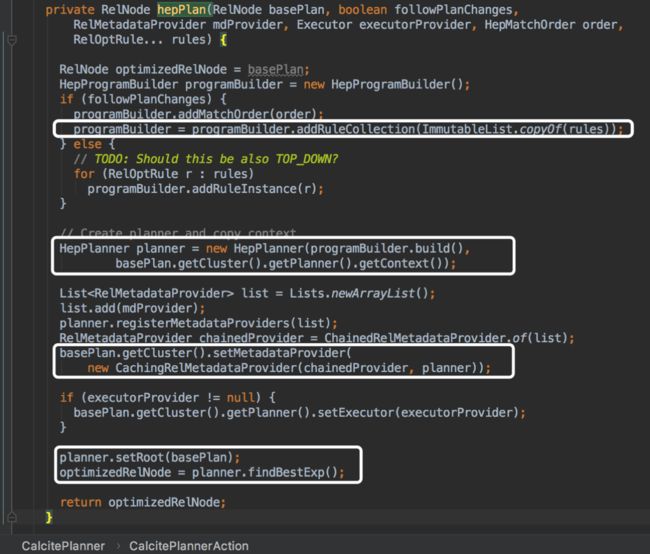
这里hive使用calcite的HepPlanner作为优化引擎(另一个选择是VolcanoPlanner),可以看到向planner输入原始的查询树、Metadata Providers、Rules,调用findBestExp(),返回优化后的查询树。与上面的架构图对应。下面我们来详细分析这几个部分是如何交互,完成优化的。
主要数据结构
下图列出了calcite中主要的相关接口和类,以及其中比较重要的成员。
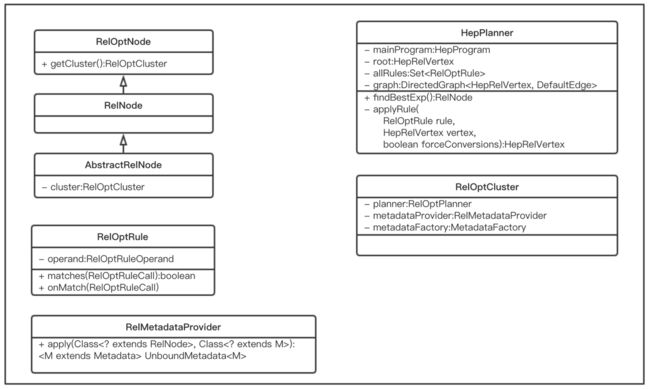
RelOptCluster 为查询优化过程中的环境信息,包含RelOptPlanner、MetadataFactory等信息,MetadataFactory可以看成RelMetadataProvider的一个工厂,calcite中MetadataFactoryImpl实现了MetadataFactory接口,其利用Guava Cache对RelMetadataProvider进行缓存。
RelNode代表了Operator Expressions中的一个节点,往往以根节点代表整个查询树。函数getCluster()可以得到当前cluster。
RelOptRule表示优化规则,是抽象类,calcite实现了很多优化规则,用户也可以实现自己的规则。其中有两个重要的函数:matches(RelOptRuleCall) 判断规则是否匹配当前RelNode;当匹配的时候会调用onMatch(RelOptRuleCall)。
RelMetadataProvider是如何获得relational expressions的matadata的接口,只有一个函数 apply(...),这么说可能不是很明了,下文的例子会详细讲。
HepPlanner就是根据rules进行优化的类,其成员mainProgram可以看成根据rules等信息生成的优化策略,会具体指导优化过程;graph是封装了Operator Expressions的有向图。其成员函数findBestExp()是优化的入口,返回优化过的Operator Expressions。执行时会多次调用applyRule(...) 函数,其中就会调用到RelOptRule的matches(RelOptRuleCall)和onMatch(RelOptRuleCall)。
优化流程
优化的主入口是HepPlanner.findBestExp(),其中会调用executeProgram(mainProgram),mainProgram 由Instructions组成,Instruction主要是RuleCollection,也有MatchOrder、MatchLimit等。对于RuleCollection,executeInstruction就是对每一个rule进行apply,这里以HiveReduceExpressionsRule为例往下分析,在HepPlanner.applyRule函数中可以看到,首先调用matchOperands以及HiveReduceExpressionsRule.matches判断此规则是否匹配,若匹配则调用fireRule(call),会进到HiveReduceExpressionsRule.onMatch函数进行这条规则的具体优化,时序图如下:
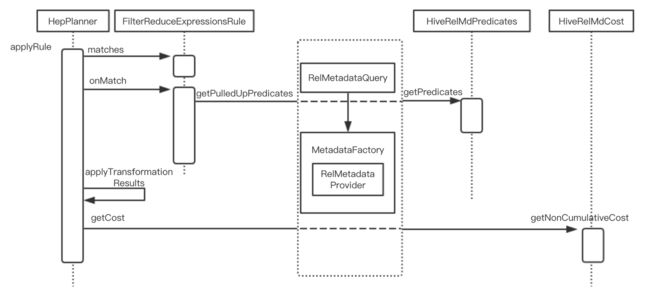
这里我们不展开讨论HiveReduceExpressionsRule具体做了什么,主要来看一下其怎么利用RelMetadataQuery进行metadata访问的。RelMetadataQuery可以看成metadata的访问媒介,实际访问的metadata由RelNode的MetadataFactory提供。在BuiltInMetadata中定义了所有metadata的接口,hive通过RelMetadataProvider实现了这些接口,并注册到MetadataFactory中。
RelMetadataProvider有好几个实现类,其中最重要的是ReflectiveRelMetadataProvider,这个类通过java的动态代理机制绑定hive的metadata实现。具体可见ReflectiveRelMetadataProvider.reflectiveSource的实现。部分代码如下:
private static RelMetadataProvider reflectiveSource(final Object target,
final ImmutableList methods) {
...
final Set> classes = Sets.newHashSet();
final Map, Method>, Method> handlerMap =
Maps.newHashMap();
for (final Method handlerMethod : target.getClass().getMethods()) {
for (Method method : methods) {
if (couldImplement(handlerMethod, method)) {
@SuppressWarnings("unchecked") final Class relNodeClass =
(Class) handlerMethod.getParameterTypes()[0];
classes.add(relNodeClass);
handlerMap.put(Pair.of(relNodeClass, method), handlerMethod);
}
}
}
final ConcurrentMap, UnboundMetadata> methodsMap = new ConcurrentHashMap<>();
for (Class key : classes) {
ImmutableNullableList.Builder builder =
ImmutableNullableList.builder();
for (final Method method : methods) {
builder.add(find(handlerMap, key, method));
}
final List handlerMethods = builder.build();
final UnboundMetadata function =
new UnboundMetadata() {
public Metadata bind(final RelNode rel,
final RelMetadataQuery mq) {
return (Metadata) Proxy.newProxyInstance(
metadataClass0.getClassLoader(),
new Class[]{metadataClass0},
new InvocationHandler() {
public Object invoke(Object proxy, Method method,
Object[] args) throws Throwable {
...
try {
return handlerMethod.invoke(target, args1);
} catch (InvocationTargetException
| UndeclaredThrowableException e) {
Throwables.propagateIfPossible(e.getCause());
throw e;
} finally {
mq.set.remove(key);
}
}
});
}
};
methodsMap.put(key, function);
}
return new ReflectiveRelMetadataProvider(methodsMap, metadataClass0);
}
函数的第一个参数target是hive实现的某个metadata的实现类,第二个参数methods是实现的目标接口。函数会找出target中对接口的实现函数,并将该实现函数的第一个参数作为key放在map中。之后在访问matadata的时候,会以当前RelNode的实际类型为key,在map中查找实现函数。如果没有以当前RelNode的实际类型为第一个参数的具体实现,就会有空指针异常。这里有我向hive提交的一个patch(HIVE-19202),就是这样的问题。
总结
本文介绍了calcite的架构及hive利用calcite进行CBO的部分源码分析。我们了解了一个数据处理系统可以如何通过扩展calcite的rule和metadata接口实现自定义的优化处理。