hadoop3.1.0 HA高可用完全分布式集群的安装部署(详细教程)
1.环境介绍
服务器环境:CentOS 7 5台服务器 两台namenode 三台datanode
| 节点 |
IP |
NN |
DN |
ZK |
ZKFC |
JN |
RM |
NM |
| h01 |
192.168.163.135 |
1 |
|
|
1 |
|
1 |
|
| h02 |
192.168.163.136 |
1 |
|
|
1 |
|
1 |
|
| h03 |
192.168.163.137 |
|
1 |
1 |
|
1 |
|
1 |
| h04 |
192.168.163.138 |
|
1 |
1 |
|
1 |
|
1 |
| h05 |
192.168.163.139 |
|
1 |
1 |
|
1 |
|
1 |
安装文件版本:
JDK : jdk-8u65-linux-x64.tar.gz
Zookeeper : zookeeper-3.4.9.tar.gz
Hadoop : hadoop-3.1.0.tar.gz
2.配置hadoop的hosts文件和关闭防火墙及配置ssh免密登陆每台都要配置
2.1添加hostname(每台都要执行)
hostnamectl --static set-hostname h012.2添加hosts文件配置项
vim /etc/hosts内容如下:
192.168.163.135 h01
192.168.163.136 h02
192.168.163.137 h03
192.168.163.138 h04
192.168.163.139 h05文件拷贝至其他4台服务器使用命令
scp -r /etc/hosts root@h02:/etc/hosts
scp -r /etc/hosts root@h03:/etc/hosts
scp -r /etc/hosts root@h04:/etc/hosts
scp -r /etc/hosts root@h05:/etc/hosts2.3关闭防火墙
安装iptables
yum install iptables-services关闭和永久关闭防火墙
systemctl stop iptables
systemctl disable iptables
systemctl stop firewalld
systemctl disable firewalld2.4配置ssh免密登陆(一定要配置很重要)
在5台服务器上生成密匙
ssh-keygen -t rsa
密匙相互拷贝服务器别漏掉
(每台都要执行包括自己本身)
ssh-copy-id h02在任意机器测试连接情况
ssh root@h01
3.安装JDK
新建文件夹
mkdir -p /usr/local/java解压jdk文件
tar -zxvf jdk..... -C /usr/local/jav
配置环境变量
vim /etc/profile内容如下
export JAVA_HOME=/usr/local/java/jdk1.8.0_65
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin生效配置文件
source /etc/profile
拷贝jdk到其他服务器
scp -r /usr/local/java/jdk1.8.0_65 h02:/usr/local/java/jdk1.8.0_65拷贝环境变量到其他服务器
scp /etc/profile h05:/etc每台机器生效环境变量
source /etc/profile
4.安装zookeeper集群
创建zookeeper的数据存放路径
(h03,h04,h05三台服务器都要创建)
mkdir zdata/data安装zookeeper
tar -xzvf zookeeper-3.4.9.tar.gz创建zookeeper的文件夹连接
ln -sf zookeeper-3.4.9 zookeeper修改环境变量
vim /etc/profile变成如下内容
export JAVA_HOME=/usr/local/java/jdk1.8.0_65
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export ZOOKEEPER_HOME=/zdata/zookeeper
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$ZOOKEEPER_HOME/bin拷贝后修改配置文件
cp /zdata/zookeeper/conf/zoo_sample.cfg /zdata/zookeeper/conf/zoo.cfg如下内容
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/zdata/data
# the port at which the clients will connect
clientPort=2181
server.1=h03:2888:3888
server.2=h04:2888:3888
server.3=h05:2888:3888拷贝安装目录和环境变量到h04,h05服务器
scp /etc/profile h05:/etc
scp -r /zdata/zookeeper-3.4.9 h04:/zdata/zookeeper-3.4.9生效配置文件
source /etc/profile生成ID在data文件夹中(三台服务器对应)
echo "1" > myid
echo "2" > myid
echo "3" > myid启动zookeeper服务进入bin目录(三台都要启动)
./zkServer.sh startJps查看是否启动成功
出现QuorumPeerMain标识启动成功
5.安装hadoop集群
新建hadoop文件夹 5台服务器都要创建
mkdir -p /usr/local/hadoop解压hadoop
tar -zxvf hadoop-3.1.0.tar.gz -C /usr/local/hadoop/配置环境变量每台都要配置
export JAVA_HOME=/usr/local/java/jdk1.8.0_65
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.0
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin生效配置文件命令上面有。
下面开始配置hadoop的配置文件
vim /usr/local/hadoop/hadoop-3.1.0/etc/hadoop/hadoop-env.sh内容如下
export JAVA_HOME=/usr/local/java/jdk1.8.0_65
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.0修改core-site.xml
fs.defaultFS
hdfs://ns1/
hadoop.tmp.dir
/hdata/tmp
ha.zookeeper.quorum
h03:2181,h04:2181,h05:2181
修改hdfs-site.xml
dfs.nameservices
ns1
dfs.ha.namenodes.ns1
nn1,nn2
dfs.namenode.rpc-address.ns1.nn1
h01:9000
dfs.namenode.http-address.ns1.nn1
h01:50070
dfs.namenode.rpc-address.ns1.nn2
h02:9000
dfs.namenode.http-address.ns1.nn2
h02:50070
dfs.namenode.shared.edits.dir
qjournal://h03:8485;h04:8485;h05:8485/ns1
dfs.journalnode.edits.dir
/hdata/jdata
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.ns1
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
修改mapred-site.xml
mapreduce.framework.name
yarn
修改yarn-site.xml
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
yrc
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
h01
yarn.resourcemanager.hostname.rm2
h02
yarn.resourcemanager.zk-address
h03:2181,h04:2181,h05:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
修改工作workers文件
vim workers内容如下
h01
h02
h03在/hadoop/sbin路径下:
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root还有,start-yarn.sh,stop-yarn.sh顶部也需添加以下:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root把配置好的hadoop文件拷贝至其他机器上(别忘记修改环境变量)
scp -r /usr/local/hadoop/hadoop-3.1.0 h03:/usr/local/hadoop/hadoop-3.1.0
scp -r /usr/local/hadoop/hadoop-3.1.0 h04:/usr/local/hadoop/hadoop-3.1.0
scp -r /usr/local/hadoop/hadoop-3.1.0 h05:/usr/local/hadoop/hadoop-3.1.0
启动过程
第一步先启动journalnode分别在h03,h04,h05服务器上启动jps查看启动是否成功
sbin/hadoop-daemon.sh start journalnode
在h01上格式化hdfs(格式化后在吧hadoop拷贝至h02第二个节点)
hdfs namenode -format
scp -r /usr/local/hadoop/hadoop-3.1.0 h02:/usr/local/hadoop/hadoop-3.1.0
在h01上格式化ZKCF只需要执行一次
hdfs zkfc -formatZK
启动hdfs在h01上
sbin/start-dfs.sh
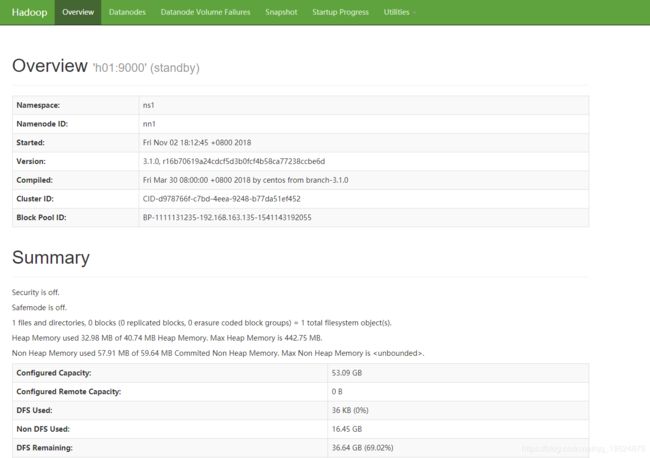
- 测试集群运行
http://h02:50070
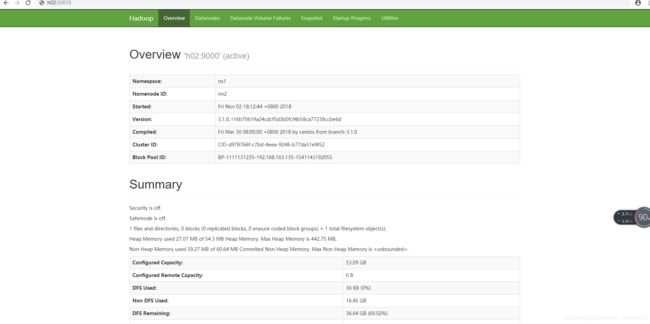
http://h01:50070